2020-12-31 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:270 收藏
Published at 2020-12-31 | Last Update 2020-12-31
This post also provides an English version.
This post belongs to the Cilium Code Walk Through Series.
排查问题时研究了一下 Cilium health probe 相关的代码,本文略作整理,仅供参考。代码基于 1.8.4。
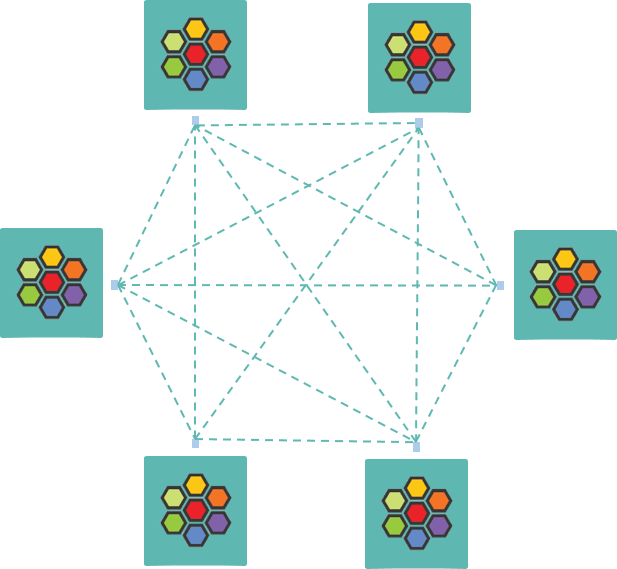
流程图:
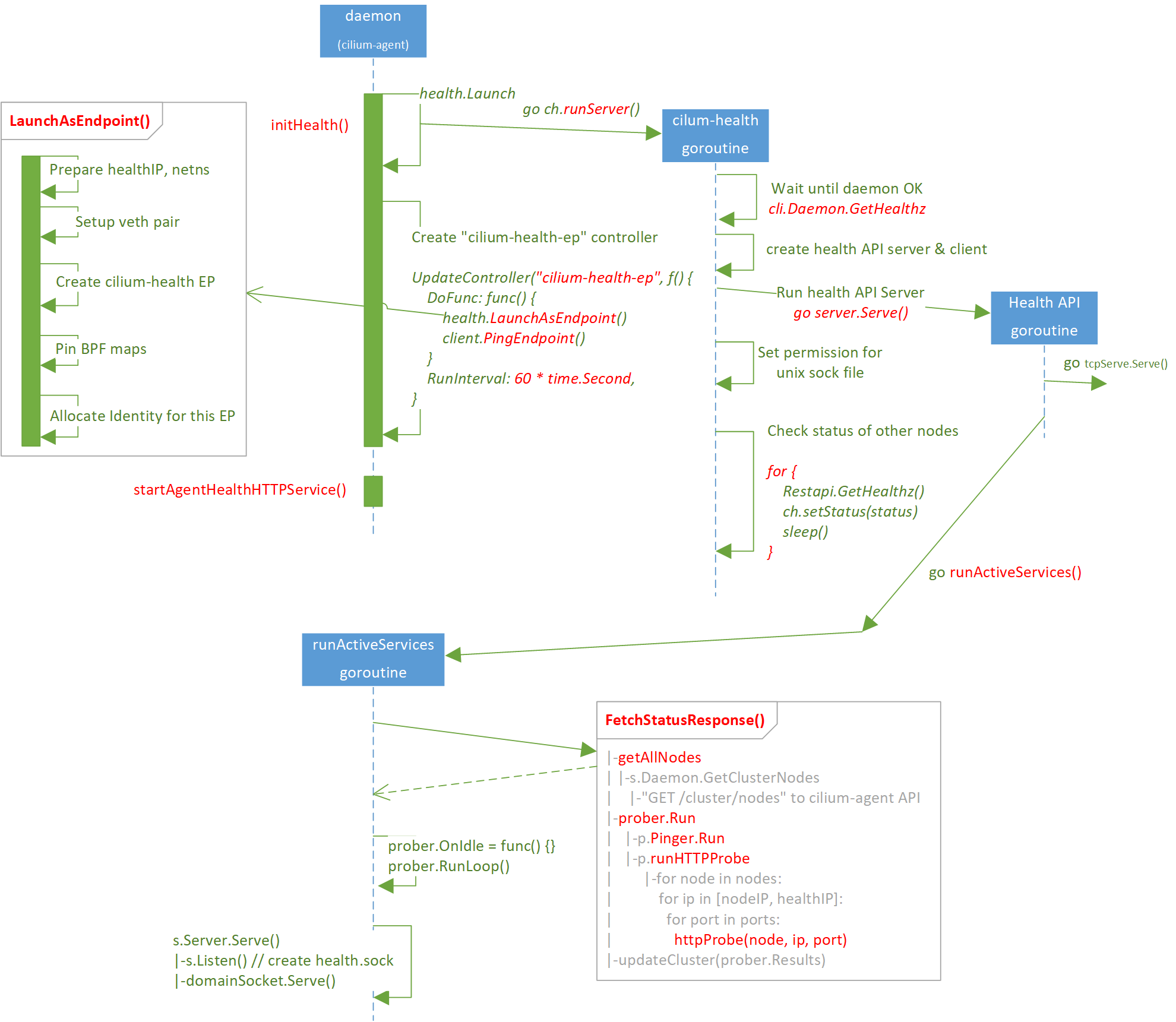
调用栈:
runDaemon // daemon/cmd/daemon_main.go
|-initHealth // daemon/cmd/health.go
| |-health.Launch // cilium-health/launch/launcher.go
| | |-ch.server = server.NewServer()
| | | |-newServer
| | | |-api := restapi.NewCiliumHealthAPI
| | | |-srv := healthApi.NewServer(api)
| | |-ch.client = client.NewDefaultClient()
| | |-go runServer() // cilium-health/launch/launcher.go
| | |-go ch.server.Serve()
| | | |-for { go tcpServer.Serve() }
| | | |-go runActiveServices()
| | | |-s.FetchStatusResponse
| | | | |-getAllNodes
| | | | | |-s.Daemon.GetClusterNodes
| | | | | |-"GET /cluster/nodes" to cilium-agent API
| | | | |-prober.Run
| | | | | |-p.Pinger.Run
| | | | | |-p.runHTTPProbe
| | | | | |-for node in nodes:
| | | | | for ip in [nodeIP, healthIP]:
| | | | | for port in ports:
| | | | | httpProbe(node, ip, port) // port=4240
| | | | |-updateCluster(prober.Results)
| | | |-s.getNodes
| | | |-prober.OnIdle = func() {
| | | | updateCluster(prober.Results)
| | | | nodesAdded, nodesRemoved := getNodes()
| | | | |-s.Daemon.GetClusterNodes
| | | | |-"GET /cluster/nodes" to cilium-agent API
| | | | prober.setNodes(nodesAdded, nodesRemoved)
| | | | }
| | | |-prober.RunLoop
| | | |-s.Server.Serve() // api/v1/health/server/server.go
| | | |-s.Listen() // listen at unix://xxx/health.sock
| | | |-if unix sock:
| | | |-domainSocket.Serve(l)
| | |-for {
| | ch.client.Restapi.GetHealthz()
| | ch.setStatus(status)
| | }
| |
| |-pidfile.Remove("/var/run/cilium/state/health-endpoint.pid")
| |-UpdateController("cilium-health-ep", func() {
| DoFunc: func() {
| LaunchAsEndpoint
| RunInterval: 60 * time.Second,
| }
| })
|
|-startAgentHealthHTTPService // daemon/cmd/agenthealth.go
|- mux.Handle("/healthz")
1.1 Full-mesh 健康探测
在 Cilium 的设计中,每个 node 都可以主动探测(probe)其他 node 的健康状态, 这样它们就能拿到第一手的全局健康状态信息(global health status of all nodes)。
默认情况下,任何两个 node 之间都会互相 probe,因此最终形成一张 full-mesh probe 网络,如下图所示:
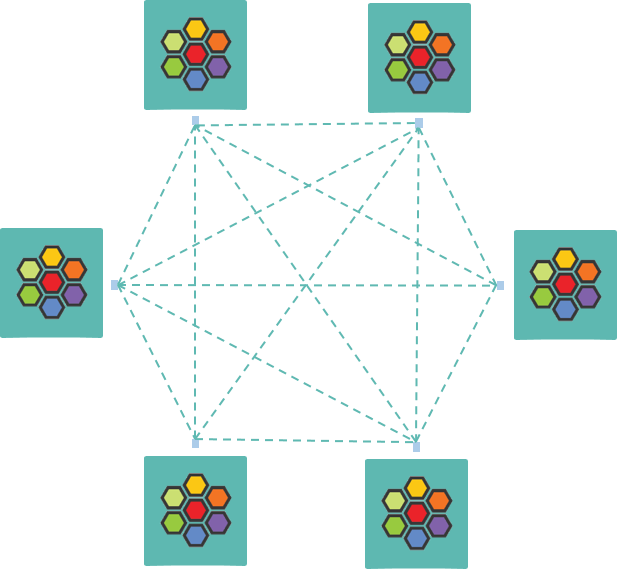
Fig. Full-mesh health probe among Cilium nodes
Probe 行为由 cilium-agent 的两个开关控制,默认都是开的,
enable-health-checking:probe 其他 node的健康状态。enable-endpoint-health-checking:probe 其他 node 上的cilium-health-ep的健康状态。稍后会介绍cilium-health-ep是什么。
1.2 四种 probe 类型
从网络层级的角度,probe 分两个维度:
- 三层(L3)探测:
ping(ICMP) - 七层(L7)探测:
GETAPI。
再结合以上两个开关,总共就有四种 probe:
-
enable-health-checking=true:- ICMP probe (L3):
ping <NodeIP> - HTTP probe (L7):
GET http://<NodeIP>:4240/hello
- ICMP probe (L3):
-
enable-endpoint-health-checking=true:- ICMP probe (L3):
ping <HealthIP> - HTTP probe (L7):
GET http://<HealthIP>:4240/hello
- ICMP probe (L3):
1.3 Probe results
Probe 结果会缓存到 cilium-agent 中,可以通过下面命令查看(# 开头的注释是后加的):
(node1) $ cilium-health status
Probe time: 2020-12-29T15:17:02Z
Nodes:
cluster1/node1 (localhost):
Host connectivity to 10.5.6.60: # <-- NodeIP
ICMP to stack: OK, RTT=9.557967ms
HTTP to agent: OK, RTT=405.072µs
Endpoint connectivity to 10.6.2.213: # <-- HealthIP
ICMP to stack: OK, RTT=9.951333ms
HTTP to agent: OK, RTT=468.645µs
cluster1/node2:
...
cluster2/node100:
Host connectivity to 10.6.6.100: # <-- NodeIP
ICMP to stack: OK, RTT=10.164048ms
HTTP to agent: OK, RTT=694.196µs
Endpoint connectivity to 10.22.1.3: # <-- HealthIP
ICMP to stack: OK, RTT=11.282117ms
HTTP to agent: OK, RTT=765.092µs
如果启用了 clustermesh,那 cilium-agent 也会对其他集群的 node 进行探测,所以我们看到上面的输出中有其他集群的 node 信息。
1.4 cilium-health-ep: cilium-health endpoint
简单来说,cilium-agent 会为每个 Pod 创建一个它所谓的 Endpoint 对象。而在这里,
cilium-health-ep 是个特殊的 endpoint:
(node) $ cilium endpoint list
ENDPOINT POLICY (ingress) POLICY (egress) IDENTITY LABELS (source:key[=value]) IPv4 STATUS
...
2399 Disabled Disabled 4 reserved:health 10.6.2.213 ready
...
它并不是一个 Pod,但可以看到,它有自己独立的
- Endpoint ID:随机分配,每台节点内唯一。
- Identity:reserved identity,固定值 4,也就是说每台节点上的 cilium-health identity 都是 4。
- IP address:cilium-agent 随机分配。
- Veth pair:
lxc_health@<peer>
也可以用下面的方式查看 cilium-health 使用的 IP 地址:
$ cilium status --all-addresses | grep health
10.6.2.213 (health)
1.5 小结
由以上内容可知,Cilium health probe 的整体设计还是非常简单直接的,并没有很高深的东西。
但到了实现层面,就要复杂很多了。
完整的流程图和调用关系见本文开篇。接下来分步介绍这个过程。
2.1 初始化流程
从 cilium-agent(daemon)初始化代码开始。
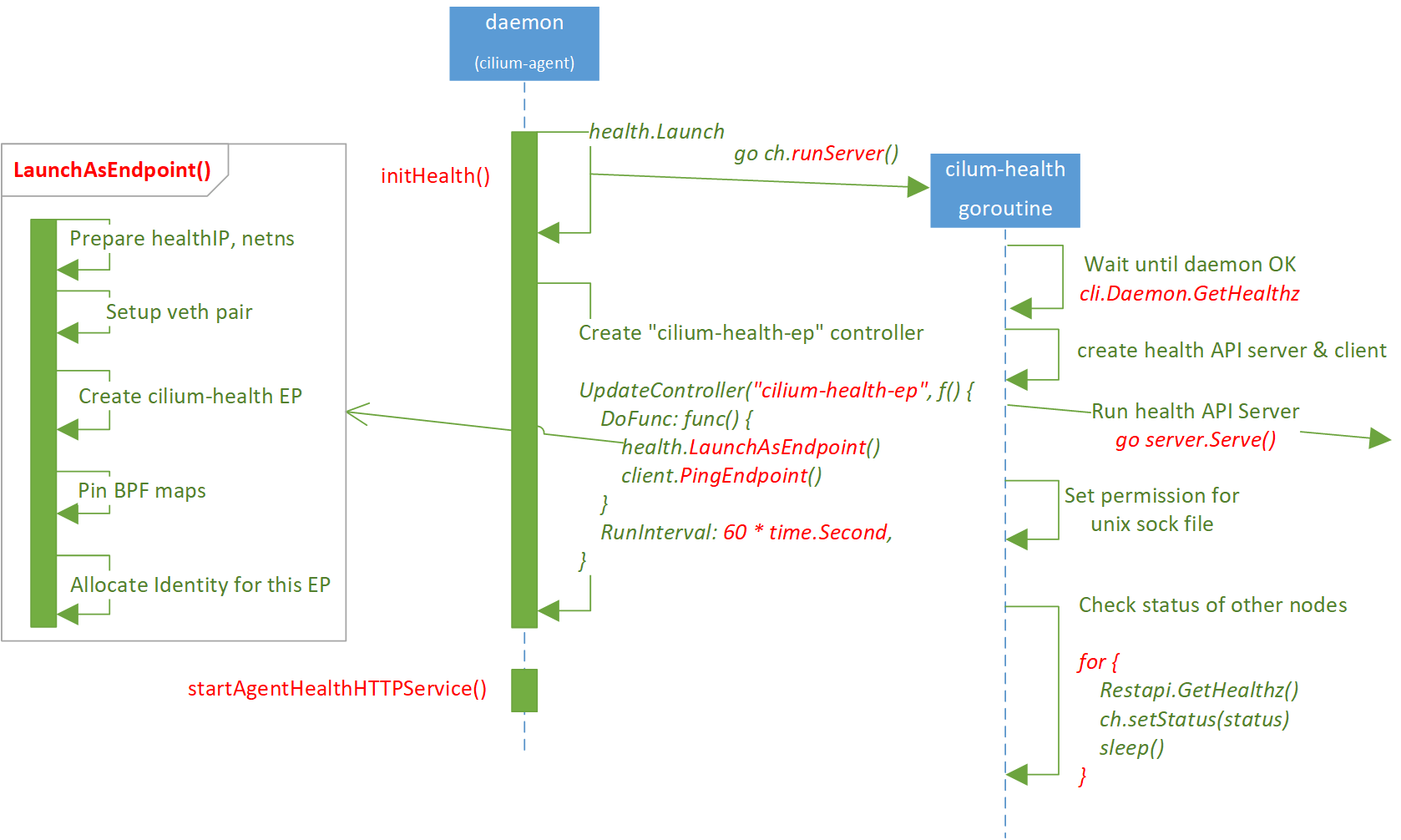
大致步骤:
-
调用
initHealth()完成 prober 的初始化工作,大部分工作都在这里面完成。- 初始化 prober,顺序对其他所有 node 执行 probe。
- 创建
cilium-health-ep,这一步不依赖上面 probe 的结果,二者是独立进行的。
-
注册 cilium-agent
/healthzAPI 并开始提供服务。- 这个 API 用于检测 cilium-agent 是否正常。
cilium status --brief返回的就是这个 API 的结果。
但这里要注意,以上两个步骤是异步进行的,initHealth() 中会创建很多 goroutine 异步执行。
也就是说,cilium-agent 的 /healthz 很快会进入 ready 状态,而并不会等待 initHealth()
对所有 node 执行完 health probe,因为后者可能需要几秒钟、几分钟,甚至几个小时。
大部分工作都在 initHealth() 中完成,接下来看这里的实现。
2.2 initHealth() -> Launch() -> runServer() -> server.Serve()
initHealth() 做的事情:
-
调用
health.Launch(),后者- 初始化
ch.server - 初始化
ch.client go ch.runServer(),接下来的大部分逻辑,都在这里面。
- 初始化
- 清理之前的 cilium-health pid 文件(
/var/run/cilium/state/health-endpoint.pid) -
创建一个名为
cilium-health-ep的 controller(定时任务),这里面会- 创建
cilium-healthendpoint, - 定期将该
cilium-healthendpoint 状态同步到 K8s。
- 创建
接下来看 go ch.runServer()。
2.3 runServer()
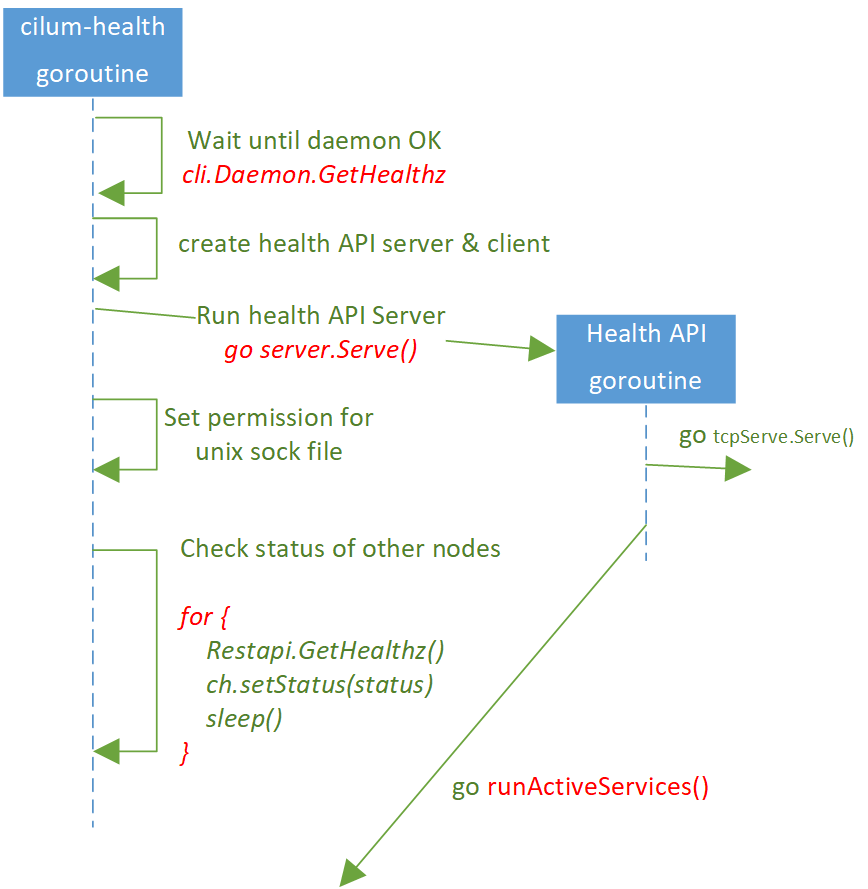
代码见 cilium-health/launch/launcher.go。
逻辑:
- 等待 cilium-agent 启动成功(
GET /healthz返回成功),然后转步骤 2 - 删除之前的
/var/run/cilium/health.sock文件。本地执行cilium-health命令时会用到这个 socket 文件。 -
go ch.server.Serve():创建一个 goroutine,在里面启动 cilium-health API server,主逻辑在这里面,包括:- 创建 TCP servers
- 运行
runActiveServices(),这里面会创建 prober 和 unix servers,其中 unix server 在Listen()时会创建新的health.sock文件。
-
等待,直到新的
health.sock文件 ready,然后给其设置合适的文件权限 - 以
statusProbeInterval的间隔,定时向 cilium-agent 发起GET /healthz,并将结果保存
ch.server.Serve() 实现:
// pkg/health/server/server.go
// Serve spins up the following goroutines:
// * TCP API Server: Responders to the health API "/hello" message, one per path
// * Prober: Periodically run pings across the cluster, update server's connectivity status cache.
// * Unix API Server: Handle all health API requests over a unix socket.
func (s *Server) Serve() (err error) {
for i := range s.tcpServers {
srv := s.tcpServers[i]
go func() {
errors <- srv.Serve()
}()
}
go func() {
errors <- s.runActiveServices()
}()
err = <-errors // Block for the first error, then return.
return err
}
这里面最重要的是 runActiveServices()。
2.4 runActiveServices()
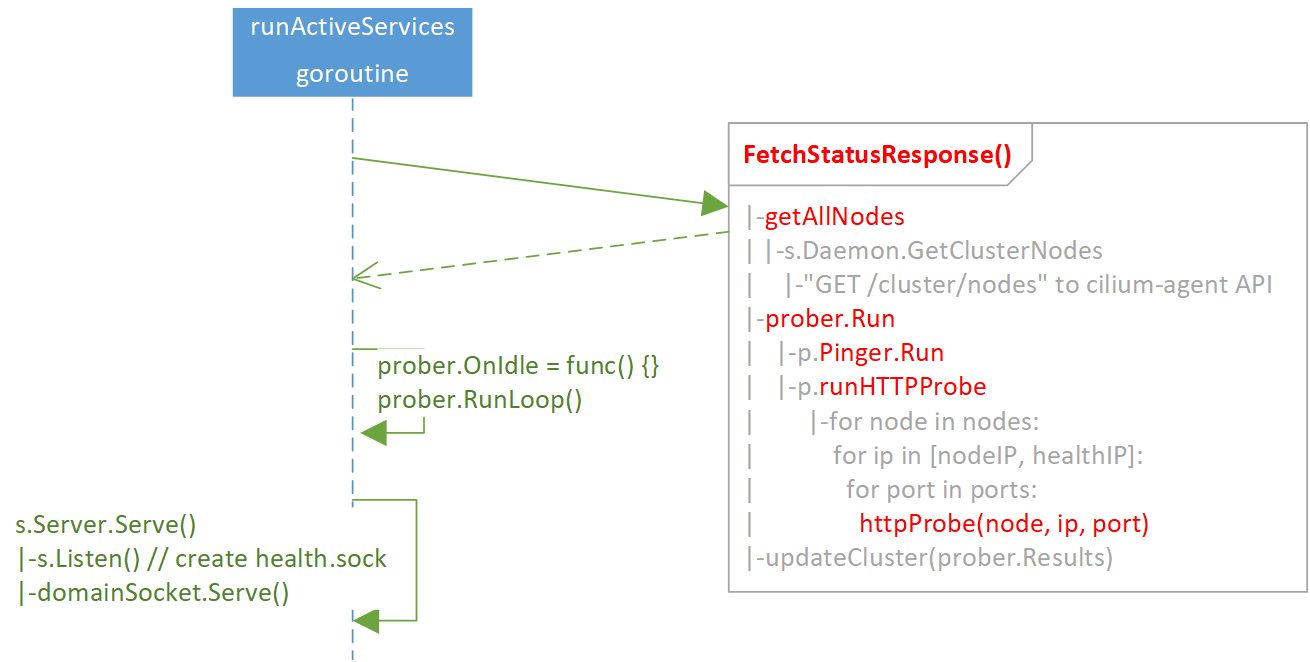
主要步骤:
- 执行
FetchStatusResponse(),这会用一个三层 for 循环对所有 node 顺序进行 probe; - 设置 prober
OnIdle()handler,然后启动prober.RunLoop(),定期更新 node 集 合; - 执行
s.Server.Seve(),开始接收 Unix、HTTP、HTTPS 请求。
注意其中的第一步,
- 对所有 node 的 probe 操作是顺序进行的。
- 每次 probe 如果不通,需要过
30s超时退出。
因此,如果有大量 node 不通,这里就会花费大量时间,导致后面的 UNIX server 迟
迟无法启动,具体表现就是宿主机执行 cilium-health 命令报以下错误:
$ cilium-health status
Error: Cannot get status: Get "http://%2Fvar%2Frun%2Fcilium%2Fhealth.sock/v1beta/status": dial unix /var/run/cilium/health.sock: connect: no such file or directory
因为这个文件是在第三步 s.Server.Serve() -> Listen() 里面才创建的。
代码
// pkg/health/server/server.go
// Run services that are actively probing other hosts and endpoints over ICMP and HTTP,
// and hosting the health admin API on a local Unix socket.
func (s *Server) runActiveServices() error {
s.FetchStatusResponse()
nodesAdded, _, _ := s.getNodes()
prober := newProber(s, nodesAdded)
prober.OnIdle = func() {
// Fetch results and update set of nodes to probe every ProbeInterval
s.updateCluster(prober.getResults())
if nodesAdded, nodesRemoved, err := s.getNodes(); err != nil {
log.WithError(err).Error("unable to get cluster nodes")
} else {
prober.setNodes(nodesAdded, nodesRemoved)
}
}
prober.RunLoop()
return s.Server.Serve()
}
最后一行 s.Server.Serve() 调用到下面这里:
// api/v1/server/server.go
// Serve the api
func (s *Server) Serve() (err error) {
if !s.hasListeners
s.Listen() // net.Listen(s.SocketPath) -> create sock file
if s.handler == nil // set default handler, if none is set
s.SetHandler(s.api.Serve(nil))
if s.hasScheme(schemeUnix) { // "Serving cilium at unix://%s", s.SocketPath
go func(l net.Listener) {
domainSocket.Serve(l)
}(s.domainSocketL)
}
if s.hasScheme(schemeHTTP) {
...
}
if s.hasScheme(schemeHTTPS) {
...
}
return nil
}
2.5 创建 cilium-health-ep
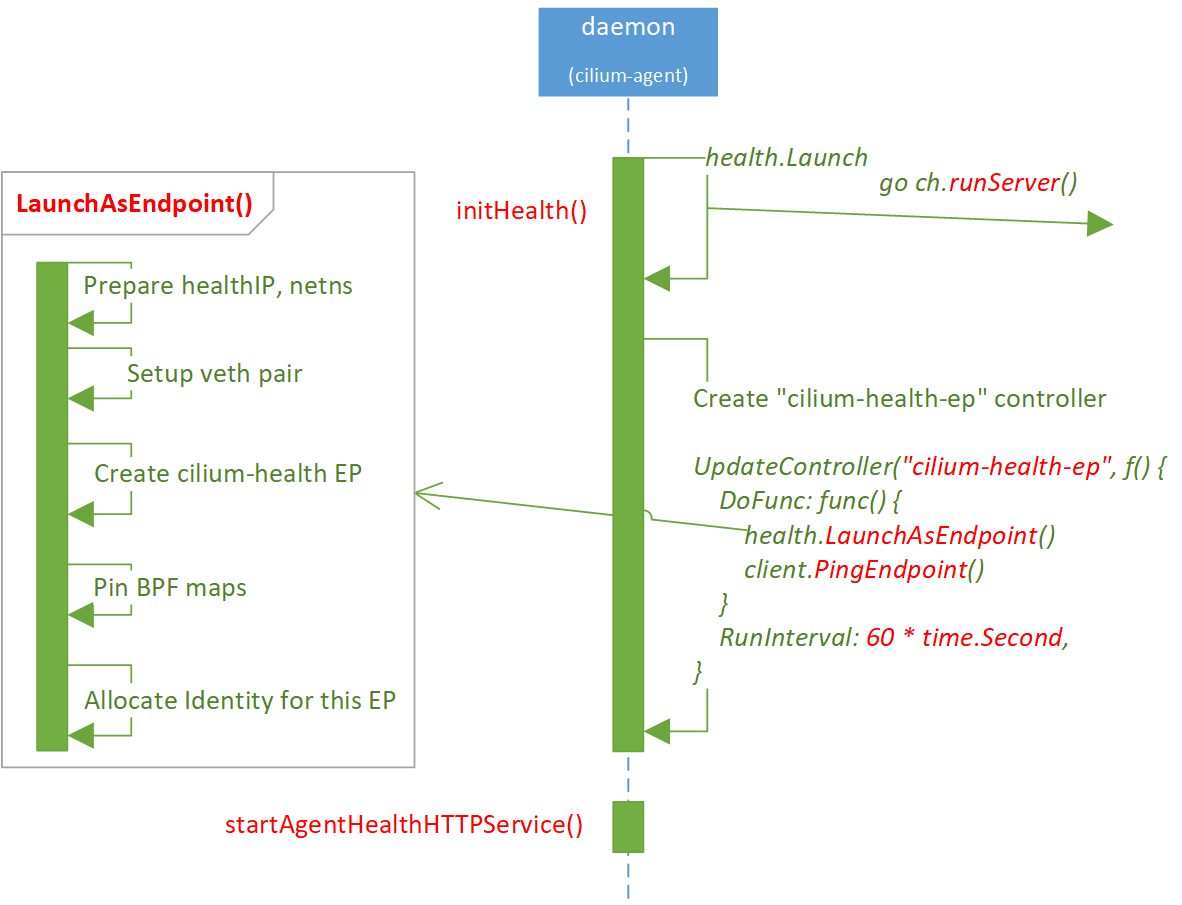
如上图所示,创建 cilium-health-ep 过程和 2.2~2.4 是异步的(从 go
runServer() 开始就是异步了),因此不用等待后者的完成。
cilium-health-ep 也是一个 Endpoint,因此会经历:
- 分配 IP
- 创建 netns
- 创建 veth pair(
lxc_health) - 创建 Endpoint
- 分配 Identity:注意 Cilium 里面都是先创建 Endpoint,再为 Endpoint 分配 Identity
- Regenerate BPF
等等过程,代码见 cilium-health/launch/endpoint.go。
一些相关的命令。
3.1 Check cilium agent status
cilium status --brief: brief output, which internally performs"GET /healthz"cilium status: normal outputcilium status --verbose: verbose output
3.2 Check connectivity results
$ cilium-health status
...
$ cilium status --verbose
...
Cluster health: 265/268 reachable (2020-12-31T09:00:03Z)
Name IP Node Endpoints
cluster1/node1 (localhost) 10.5.6.60 reachable reachable
cluster2/node2 10.6.9.132 reachable reachable
...
3.3 Check health info in CT/NAT tables
ICMP records in Conntrack (CT) table and NAT table:
$ cilium bpf ct list global | grep ICMP |head -n4
ICMP IN 10.4.9.12:0 -> 10.5.8.4:518 expires=1987899 RxPackets=1 RxBytes=50 RxFlagsSeen=0x00 LastRxReport=1987839 TxPackets=1 TxBytes=50 TxFlagsSeen=0x00 LastTxReport=1987839 Flags=0x0000 [ ] RevNAT=0 SourceSecurityID=2 IfIndex=0
ICMP OUT 10.5.2.101:47153 -> 10.4.9.11:0 expires=1987951 RxPackets=0 RxBytes=0 RxFlagsSeen=0x00 LastRxReport=0 TxPackets=1 TxBytes=50 TxFlagsSeen=0x00 LastTxReport=1987891 Flags=0x0000 [ ] RevNAT=0 SourceSecurityID=0 IfIndex=0
$ cilium bpf nat list | grep ICMP |head -n4
ICMP OUT 10.5.2.101:65204 -> 10.4.6.9:0 XLATE_SRC 10.5.2.101:65204 Created=1987884sec HostLocal=1
ICMP IN 10.4.4.11:0 -> 10.5.2.101:39843 XLATE_DST 10.5.2.101:39843 Created=1987884sec HostLocal=1
如有侵权请联系:admin#unsafe.sh