
Go语言具有开发效率高,运行速度快,跨平台等优点,因此正越来越多的被攻击者所使用,其生成的是可直接运行的二进制文件,因此对它的分析类似于普通C语言可执行文件分析,但是又有所不同,本文将会使用正向与逆向结合的方式描述这些区别与特征。
1 Compile与Runtime
Go语言类似于C语言,目标是一个二进制文件,逆向的也是native代码,它有如下特性:
强类型检查的编译型语言,接近C但拥有原生的包管理,内建的网络包,协程等使其成为一款开发效率更高的工程级语言。
作为编译型语言它有运行速度快的优点,但是它又能通过内置的运行时符号信息实现反射这种动态特性。
作为一种内存安全的语言,它不仅有内建的垃圾回收,还在编译与运行时提供了大量的安全检查。
可见尽管它像C编译的可执行文件但是拥有更复杂的运行时库,Go通常也是直接将这些库统一打包成一个文件的,即使用静态链接,因此其程序体积较大,且三方库、标准库与用户代码混在一起,需要区分,这可以用类似flirt方法做区分(特别是对于做了混淆的程序)。在分析Go语言编写的二进制程序前,需要弄清楚某一操作是发生在编译期间还是运行期间,能在编译时做的事就在编译时做,这能实现错误前移并提高运行效率等,而为了语言的灵活性引入的某些功能又必须在运行时才能确定,在这时就需要想到运行时它应该怎么做,又需要为它提供哪些数据,例如:
func main() {
s := [...]string{"hello", "world"}
fmt.Printf("%s %s\n", s[0], s[1]) // func Printf(format string, a ...interface{}) (n int, err error)
在第二行定义了一个字符串数组,第三行将其输出,编译阶段就能确定元素访问的指令以及下标访问是否越界,于是就可以去除s的类型信息。但是由于Printf的输入是interface{}类型,因此在编译时它无法得知传入的数据实际为什么类型,但是作为一个输出函数,希望传入数字时直接输出,传入数组时遍历输出每个元素,那么在传入参数时,就需要在编译时把实际参数的类型与参数绑定后再传入Printf,在运行时它就能根据参数绑定的信息确定是什么类型了。其实在编译时,编译器做的事还很多,从逆向看只需要注意它会将很多操作转换为runtime的内建函数调用,这些函数定义在cmd/compile/internal/gc/builtin/runtime.go,并且在src/runtime目录下对应文件中实现,例如:
a := "123" + b + "321"
将被转换为concatstring3函数调用:
0x0038 00056 (str.go:4) LEAQ go.string."123"(SB), AX 0x003f 00063 (str.go:4) MOVQ AX, 8(SP) 0x0044 00068 (str.go:4) MOVQ $3, 16(SP) 0x004d 00077 (str.go:4) MOVQ "".b+104(SP), AX 0x0052 00082 (str.go:4) MOVQ "".b+112(SP), CX 0x0057 00087 (str.go:4) MOVQ AX, 24(SP) 0x005c 00092 (str.go:4) MOVQ CX, 32(SP) 0x0061 00097 (str.go:4) LEAQ go.string."321"(SB), AX 0x0068 00104 (str.go:4) MOVQ AX, 40(SP) 0x006d 00109 (str.go:4) MOVQ $3, 48(SP) 0x0076 00118 (str.go:4) PCDATA $1, $1 0x0076 00118 (str.go:4) CALL runtime.concatstring3(SB)
我们将在汇编中看到大量这类函数调用,本文将在对应章节介绍最常见的一些函数。若需要观察某语法最终编译后的汇编代码,除了使用ida等也可以直接使用如下三种方式:
go tool compile -N -l -S once.go go tool compile -N -l once.go ; go tool objdump -gnu -s Do once.o go build -gcflags -S once.go
2 动态与类型系统
尽管是编译型语言,Go仍然提供了一定的动态能力,这主要表现在接口与反射上,而这些能力离不开类型系统,它需要保留必要的类型定义以及对象和类型之间的关联,这部分内容无法在二进制文件中被去除,否则会影响程序运行,因此在Go逆向时能获取到大量的符号信息,大大简化了逆向的难度,对此类信息已有大量文章介绍并有许多优秀的的工具可供使用,例如go_parser与redress,因此本文不再赘述此内容,此处推荐《Go二进制文件逆向分析从基础到进阶——综述》。
本文将从语言特性上介绍Go语言编写的二进制文件在汇编下的各种结构,为了表述方便此处定义一些约定:
1. 尽管Go并非面向对象语言,但是本文将Go的类型描述为类,将类型对应的变量描述为类型的实例对象。
2. 本文分析的样例是x64上的样本,通篇会对应该平台叙述,一个机器字认为是64bit。
3. 本文会涉及到Go的参数和汇编层面的参数描述,比如一个复数在Go层面是一个参数,但是它占16字节,在汇编上将会分成两部分传递(不使用xmm时),就认为汇编层面是两个参数。
4. 一个复杂的实例对象可以分为索引头和数据部分,它们在内存中分散存储,下文提到一种数据所占内存大小是指索引头的大小,因为这部分是逆向关注的点,详见下文字符串结构。
1 数值类型
数值类型很简单只需要注意其大小即可:

2 字符串string
Go语言中字符串是二进制安全的,它不以作为终止符,一个字符串对象在内存中分为两部分,一部分为如下结构,占两个机器字用于索引数据:
type StringHeader struct {
Data uintptr // 字符串首地址
Len int // 字符串长度
}
而它的另一部分才存放真正的数据,它的大小由字符串长度决定,在逆向中重点关注的是如上结构,因此说一个string占两个机器字,后文其他结构也按这种约定。例如下图使用printf输出一个字符串"hello world",它会将上述结构入栈,由于没有终止符ida无法正常识别字符串结束因此输出了很多信息,我们需要依靠它的第二个域(此处的长度0x0b)决定它的结束位置:

字符串常见的操作是字符串拼接,若拼接的个数不超过5个会调用concatstringN,否则会直接调用concatstrings,它们声明如下,可见在多个字符串拼接时参数形式不同:
func concatstring2(*[32]byte, string, string) string func concatstring3(*[32]byte, string, string, string) string func concatstring4(*[32]byte, string, string, string, string) string func concatstring5(*[32]byte, string, string, string, string, string) string func concatstrings(*[32]byte, []string) string
因此在遇到concatstringN时可以跳过第一个参数,随后入栈的参数即为字符串,而遇到concatstrings时,跳过第一个参数后汇编层面还剩三个参数,其中后两个一般相同且指明字符串个数,第一个参数则指明字符串数组的首地址,另外经常出现的是string与[]byte之间的转换,详见下文slice部分。提醒一下,可能是优化导致一般来说在栈内一个纯字符串的两部分在物理上并没有连续存放,例如下图调用macaron的context.Query("username")获取到的应该是一个代表username的字符串,但是它们并没有被连续存放:
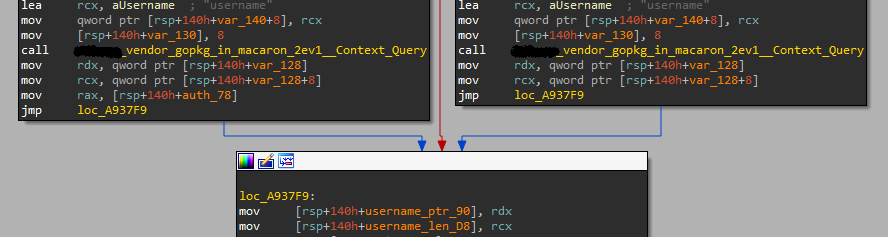
因此ida中通过定义本地结构体去解析string会遇到困难,其他结构也存在这类情况,气!
3 数组array
类似C把字符串看作char数组,Go类比知array和string的结构类似,其真实数据也是在内存里连续存放,而使用如下结构索引数据,对数组里的元素访问其地址偏移在编译时就能确定,总之逆向角度看它也是占两个机器字:
type arrayHeader struct {
Data uintptr
Len int
}
数组有三种存储位置,当数组内元素较少时可以直接存于栈上,较多时存于数据区,而当数据会被返回时会存于堆上。如下定义了三个局部变量,但是它们将在底层表现出不同的形态:
func ArrDemo() *[3]int {
a := [...]int{1, 2, 3}
b := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7}
c := [...]int{1, 2, 3}
if len(a) < len(b) {return &c}
return nil
}
变量a的汇编如下,它直接在栈上定义并初始化:

变量b的汇编如下,它的初始值被定义在了数据段并进行拷贝初始化:

事实上更常见的拷贝操作会被定义为如下这类函数,因此若符号信息完整遇到无法识别出的函数一般也就是数据拷贝函数:

变量c的汇编如下,尽管它和a的值一样,但是它的地址会被返回,如果在C语言中这种写法会造成严重的后果,不过Go作为内存安全的语言在编译时就识别出了该问题(指针逃逸)并将其放在了堆上,此处引出了runtime.newobject函数,该函数传入的是数据的类型指针,它将在堆上申请空间存放对象实例,返回的是新的对象指针:

经常会遇到的情况是返回一个结构体变量,然后将其赋值给newobject申请的新变量上。
4 切片slice
类似数组,切片的实例对象数据结构如下,可知它占用了三个机器字,与它相关的函数是growslice表示扩容,逆向时可忽略:
type SliceHeader struct {
Data uintptr // 数据指针
Len int // 当前长度
Cap int // 可容纳的长度
}
更常见的函数是与字符串相关的转换,它们在底层调用的是如下函数,此处我们依然不必关注第一个参数:
func slicebytetostring(buf *[32]byte, ptr *byte, n int) string func stringtoslicebyte(*[32]byte, string) []byte
例如下图:

可见传入的是两个参数代表一个string,返回了三个数据代表一个[]byte。
5 字典map
字典实现比较复杂,不过在逆向中会涉及到的内容很简单,字典操作常见的会转换为如下函数,一般fastrand和makemap连用返回一个map,它为一个指针,读字典时使用mapaccess1和mapaccess2,后者是使用,ok语法时生成的函数,runtime里还有很多以2结尾的函数代表同样的含义,后文不再赘述。写字典时会使用mapassign函数,它返回一个地址,将value写入该地址,另外还比较常见的是对字典进行遍历,会使用mapiterinit和mapiternext配合:
func fastrand() uint32 func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any) func mapaccess1(mapType *byte, hmap map[any]any, key *any) (val *any) func mapaccess2(mapType *byte, hmap map[any]any, key *any) (val *any, pres bool) func mapassign(mapType *byte, hmap map[any]any, key *any) (val *any) func mapiterinit(mapType *byte, hmap map[any]any, hiter *any) func mapiternext(hiter *any)
事实上更常见的是上面这些函数的同类函数,它们的后缀代表了对特定类型的优化,例如如下代码,它首先调用makemap_small创建了一个小字典并将其指针存于栈上,之后调用mapassign_faststr传入一个字符串键并获取一个槽,之后将数据写入返回的槽地址里,这里就是一个创建字典并赋值的过程:

如下是访问字典里数据的情况,调用mapaccess1_fast32传入了一个32位的数字作为键:

可以看到mapaccess和mapassign的第一个参数代表字典的类型,因此能很容易知道字典操作参数和返回值的类型。
6 结构体struct
类似于C语言,Go的结构体也是由其他类型组成的复合结构,它里面域的顺序也是定义的顺序,里面的数据对齐规则和C一致不过我们可以直接从其类型信息获得,不必自己算。在分析结构体变量时必须要了解结构体的类型结构了,其定义如下:
type rtype struct {
size uintptr // 该类型对象实例的大小
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
alg *typeAlg // algorithm table
gcdata *byte // garbage collection data
str nameOff // 名称
ptrToThis typeOff // 指向该类型的指针,如该类为Person,代码中使用到*Person时,后者也是一种新的类型,它是指针但是所指对象属于Person类,后者的类型位置存于此处
}
type structField struct {
name name // 属性名称
typ *rtype // 该域的类型
offsetEmbed uintptr // 该属性在对象中的偏移左移一位后与是否是嵌入类型的或,即offsetEmbed>>1得到该属性在对象中的偏移
}
type structType struct {
rtype
pkgPath name // 包名
fields []structField // 域数组
}
type uncommonType struct {
pkgPath nameOff // 包路径
mcount uint16 // 方法数
xcount uint16 // 导出的方法数
moff uint32 // 方法数组的偏移,方法表也是有需的,先导出方法后私有方法,而其内部按名称字符串排序
_ uint32 // unused
}
type structTypeUncommon struct {
structType
u uncommonType
}
如下为macaron的Context结构体的类型信息,可见它的实例对象占了0x90字节,这实际上会和下面fields中对象所占空间对应:
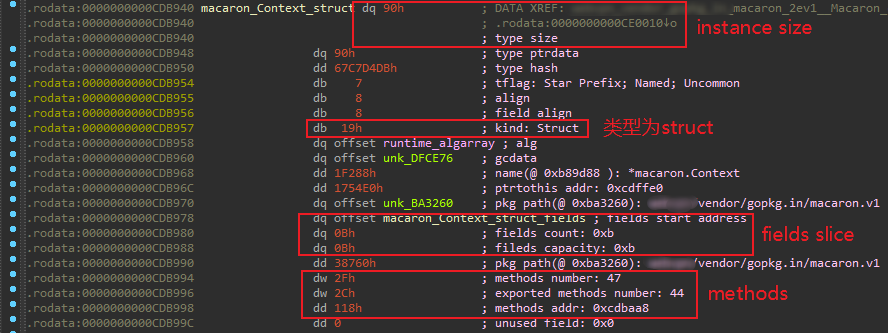
通过macaron_Context_struct_fields可转到每个域的定义,可见其域名称域类型,偏移等:

结构体类型作为自定义类型除了域之外,方法也很重要,这部分在后文会提到。
7 接口interface
接口和反射息息相关,接口对象会包含实例对象类型信息与数据信息。这里需要分清几个概念,一般我们是定义一种接口类型,再定义一种数据类型,并且在这种数据类型上实现一些方法,Go使用了类似鸭子类型,只要定义的数据类型实现了某个接口定义的全部方法则认为实现了该接口。前面提到的两个是类型,在程序运行过程中对应的是类型的实例对象,一般是将实例对象赋值给某接口,这可以发生在两个阶段,此处主要关注运行时阶段,这里在汇编上会看到如下函数:
// Type to empty-interface conversion. func convT2E(typ *byte, elem *any) (ret any) // Type to non-empty-interface conversion. func convT2I(tab *byte, elem *any) (ret any)
如上转换后的结果就是接口类型的实例对象,此处先看第二个函数,它生成的对象数据结构如下,其中itab结构体包含接口类型,转换为接口前的实例对象的类型,以及接口的函数表等,而word是指向原对象数据的指针,逆向时主要关注word字段和itab的fun字段,fun字段是函数指针数组,它里元素的顺序并非接口内定义的顺序,而是名称字符串排序,因此对照源码分析时需要先排序才能根据偏移确定实际调用的函数:
type nonEmptyInterface struct {
// see ../runtime/iface.c:/Itab
itab *struct {
ityp *rtype // 代表的接口的类型,静态static interface type
typ *rtype // 对象实例真实的类型,运行时确定dynamic concrete type
link unsafe.Pointer
bad int32
unused int32
fun [100000]unsafe.Pointer // 方法表,具体大小由接口定义确定
}
word unsafe.Pointer
}
这是旧版Go的实现,在较新的版本中此结构定义如下,在新版中它的起始位置偏移是0x18,因此我们可以直接通过调用偏移减0x18除以8获取调用的是第几个方法:
type nonEmptyInterface struct {
// see ../runtime/iface.go:/Itab
itab *struct {
ityp *rtype // static interface type
typ *rtype // dynamic concrete type
hash uint32 // copy of typ.hash
_ [4]byte
fun [100000]unsafe.Pointer // method table
}
word unsafe.Pointer
}
上面讲的是第二个函数的作用,解释第一个函数需要引入一种特殊的接口,即空接口,由于这种接口未定义任何方法,那么可以认为所有对象都实现了该接口,因此它可以作为所有对象的容器,在底层它和其他接口也拥有不同的数据结构,空接口的对象数据结构如下:
// emptyInterface is the header for an interface{} value.
type emptyInterface struct {
typ *rtype // 对象实例真实的类型指针
word unsafe.Pointer // 对象实例的数据指针
}
可见空接口两个域刚好指明原始对象的类型和数据域,而且所有接口对象是占用两个个机器字,另外常见的接口函数如下:
// Non-empty-interface to non-empty-interface conversion. func convI2I(typ *byte, elem any) (ret any) // interface type assertions x.(T) func assertE2I(typ *byte, iface any) (ret any) func assertI2I(typ *byte, iface any) (ret any)
例如存在如下汇编代码:

可以知道convI2I的结果是第一行所指定接口类型对应的接口对象,在最后一行它调用了itab+30h处的函数,根据计算可知是字母序后的第4个函数,这里可以直接查看接口的类型定义,获知第四个函数:

1 创建对象
Go不是面向对象的,此处将Go的变量当做对象来描述。函数调用栈作为一种结构简单的数据结构可以轻易高效的管理局部变量并实现垃圾回收,因此新建对象也优先使用指令在栈上分配空间,当指针需要逃逸或者动态创建时会在堆区创建对象,这里涉及make和new两个关键词,不过在汇编层面它们分别对应着makechan,makemap,makeslice与newobject,由于本文没有介绍channel故不提它,剩下的makemap和newobject上文已经提了,还剩makeslice,它的定义如下:
func makeslice(et *_type, len, cap int) unsafe.Pointer
如下,调用make([]uint8, 5,10)创建一个slice后,会生成此代码:

2 函数与方法
2.1 栈空间
栈可以分为两个区域,在栈底部存放局部变量,栈顶部做函数调用相关的参数与返回值传递,因此在分析时不能对顶部的var命名,因为它不特指某具体变量而是随时在变化的,错误的命名容易造成混淆,如下图,0xE60距0xEC0足够远,因此此处很大概率是局部变量可重命名,而0xEB8距栈顶很近,很大概率是用于传参的,不要重命名:

2.2 变参
类似Python的一般变参实际被转换为一个tuple,Go变参也被转换为了一个slice,因此一个变参在汇编级别占3个参数位,如下代码:
func VarArgDemo(args ...int) (sum int) {}
func main() {
VarArgDemo(1, 2, 3)
}
它会被编译为如下形式:

这里先将1,2,3保存到rsp+80h+var_30开始的位置,然后将其首地址,长度(3),容量(3)放到栈上,之后调用VarArgDeme函数。
2.3 匿名函数
匿名函数通常会以外部函数名_funcX来命名,除此之外和普通函数没什么不同,只是需要注意若使用了外部变量,即形成闭包时,这些变量会以引用形式传入,如在
os/exec/exec.go中如下代码:
go func() {
select {
case <-c.ctx.Done():
c.Process.Kill()
case <-c.waitDone:
}
}()
其中c是外部变量,它在调用时会以参数形式传入(newproc请见后文协程部分):

而在io/pipe.go中的如下代码:
func (p *pipe) CloseRead(err error) error {
if err == nil {
err = ErrClosedPipe
}
p.rerr.Store(err)
p.once.Do(func() { close(p.done) })
return nil
}
其中p是外部变量,它在调用时是将其存入外部寄存器(rdx)传入的:
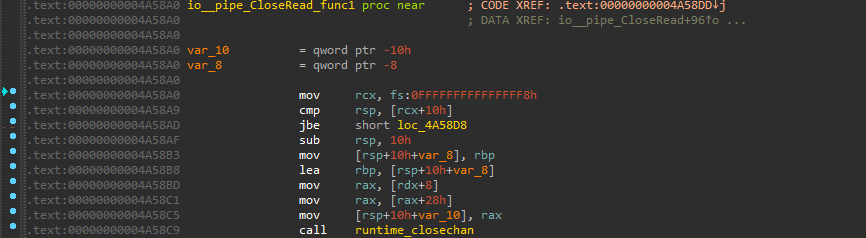
可见在使用到外部变量时它们会作为引用被传入并使用。
2.4 方法
Go可以为任意自定义类型绑定方法,方法将会被转换为普通函数,并且将方法的接收者转化为第一个参数,再看看上文结构体处的图:

如上可见Context含44个导出方法,3个未导出方法,位置已经被计算出在0xcdbaa8,因此可转到方法定义数组:


如上可见,首先是可导出方法,它们按照名称升序排序,之后是未导出方法,它们也是按名称升序排序,另外导出方法有完整的函数签名,而未导出方法只有函数名称。在逆向时不必关心这一部分结构,解析工具会自动将对应的函数调用重命名,此处仅了解即可。
在逆向时工具会将其解析为类型名__方法名或类型名_方法名,因此遇到此类名称时我们需要注意它的第一个参数是隐含参数,类似C++的this指针,但Go的方法定义不仅支持传引用,也支持传值,因此第一个参数可能在汇编层面不只占一个机器字,如:
type Person struct {
name string
age int
weight uint16
height uint16
}
func (p Person) Print() {
fmt.Printf("%t\n", p)
}
func (p *Person) PPrint() {
fmt.Printf("%t\n", p)
}
func main(){
lihua := Person{
name: "lihua",
age: 18,
weight: 60,
height: 160,
}
lihua.Print()
lihua.PPrint()
}
编译后如下所示:

根据定义两个方法都没有参数,但是从汇编看它们都有参数,如注释,在逆向时是更常见的是像PPrint这种方法,即第一个参数是对象的指针。
2.5 函数反射
函数在普通使用和反射使用时,被保存的信息不相同,普通使用不需要保存函数签名,而反射会保存,更利于分析,如下代码:
//go:noinline
func Func1(b string, a int) bool {
return a < len(b)
}
//go:noinline
func Func2(a int, b string) bool {
return a < len(b)
}
func main(){
fmt.Println(Func1("233", 2))
v := reflect.ValueOf(Func2)
fmt.Println(v.Kind()==reflect.Func)
}
编译后通过字符串搜索,可定位到被反射的函数签名(当然在逆向中并不知道应该搜什么,而是在函数周围寻找签名):


而普通函数的签名无法被搜到:

3 伸缩栈
由于go可以拥有大量的协程,若使用固定大小的栈将会造成内存空间浪费,因此它使用伸缩栈,初始时一个普通协程只分配几KB的栈,并在函数执行前先判断栈空间是否足够,若不够则通过一些方式扩展栈,这在汇编上的表现形式如下:

在调用runtime·morestack*函数扩展栈后会重新进入函数并进入左侧分支,因此在分析时直接忽略右侧分支即可。
4 调用约定
Go统一通过栈传递参数和返回值,这些空间由调用者维护,返回值内存会在调用前选择性的被初始化,而参数传递是从左到右顺序,在内存中从下到上写入栈,因此看到mov [rsp + 0xXX + var_XX], reg(栈顶)时就代表开始为函数调用准备参数了,继续向下就能确定函数的参数个数及内容:

如图,mov [rsp+108h+v_108], rdx即表示开始向栈上传第一个参数了,从此处到call指令前都是传参,此处可见在汇编层面传了3个参数,其中第2个和第3个参数为Go语言里的第二个参数,call指令之后为返回值,不过可能存在返回值未使用的情况,因此返回值的个数和含义需要从函数内部分析,比如此处的Query我们已知arg_0/arg_8/arg_10为参数,那么剩下的arg18/arg20即为返回值:

需要注意的是不能仅靠函数头部就断定参数个数,例如当参数为一个结构体时,可能头部的argX只代表了其首位的地址,因此需要具体分析函数retn指令前的指令来确定返回值大小。
5 写屏障
Go拥有垃圾回收,其三色标记法使用了写屏障的方法保证一致性,在垃圾收集过程中会将写屏障标志置位,此时会进入另一条逻辑,但是我们在逆向分析过程中可以认为该位未置位而直接分析无保护的情况:
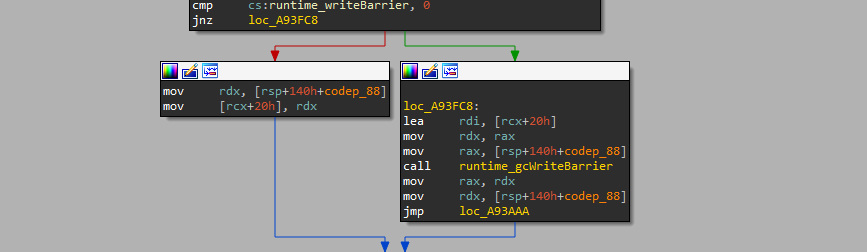
如上图,先判断标志,再决定是否进入,在分析时可以直接认为其永假并走左侧分支。
6 协程go
使用go关键词可以创建并运行协程,它在汇编上会被表现为由runtime_newproc(fn,args?),它会封装函数与参数并创建协程执行信息,并在适当时候被执行,如:

这里执行了go loop(),由于没有参数此处newproc只被传入了函数指针这一个参数,否则会传入继续传入函数所需的参数,在分析时直接将函数作为在新的线程里执行即可。
7 延迟执行defer
延迟执行一般用于资源释放,它会先注册到链表中并在当前调用栈返回前执行所有链表中注册的函数,在汇编层面会表现为runtime_deferproc,例如常见的锁释放操作:

这里它第一个参数代表延迟函数参数字节大小为8字节,第二个参数为函数指针,第三个参数为延迟执行函数的参数,若创建失败会直接返回,返回前会调用runtime_deferreturn去执行其他创建的延迟执行函数,一般我们是不需要关注该语句的,因此可以直接跳过相关指令并向左侧继续分析。
8 调用c库cgo
Go可以调用C代码,但调用C会存在运行时不一致,Go统一将C调用看作系统调用来处理调度等问题,另一方类型不一致才是我们需要关注的重点,为了解决类型与命名空间等问题cgo会为C生成桩代码来桥接Go,于是这类函数在Go语言侧表现为XXX_CFunc__YYY,它封装参数并调用runtime_cgocall转换状态,在中间表示为NNN_cgo_abcdef123456_CFunc__ZZZ,这里它解包参数并调用实际c函数,例如:

此处它调用了libc的void* realloc(void*, newsize),在Go侧它封装成了os_user__Cfunc_realloc,在该函数内部参数被封装成了结构体并作为指针与函数指针一起被传入了cgocall,而函数指针即_cgo_3298b262a8f6_Cfunc_realloc为中间层负责解包参数等并调用真正的C函数:
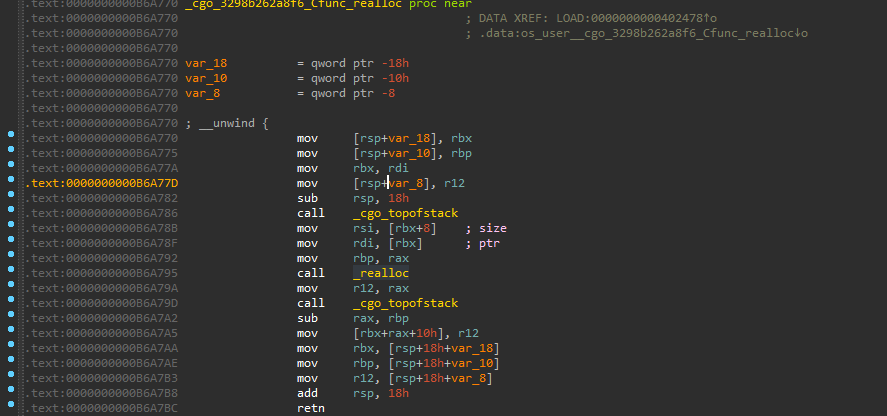
9 其他
还有些内容,如看到以panic开头的分支不分析等不再演示,分析时遇到不认识的三方库函数和标准库函数直接看源码即可。
https://draveness.me/golang/
https://tiancaiamao.gitbooks.io/go-internals/content/zh/02.3.html
https://www.pnfsoftware.com/blog/analyzing-golang-executables/
https://rednaga.io/2016/09/21/reversing_go_binaries_like_a_pro/
https://research.swtch.com/interface
本文作者:Further_eye
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/151339.html
如有侵权请联系:admin#unsafe.sh