最近一直在搞毕业设计,听说有个AI题,就水了一下。ctf中机器学习题很少(划掉 是会做的机器学习题很少),这次正好记录下解题步骤。
题目描述


题目附件
链接:https://share.weiyun.com/xumH06U5 密码:4nvuuk
打开附件,给了一个数据集,一个py脚本和一个pytorch的模型文件。
之前一直都是在用TensorFlow和Keras,头一次看pytorch框架的代码感觉很清晰,很容易上手(也可能只是这个题简单)
首先读一下题目给的py文件:

最开始导入了一些库,里面有一个库给了注释,打开链接居然是一个生成对抗图像的库。这么说通过阅读给的脚本,就能知道出题人如何生成对抗样本,然后找到他们,然后得到flag了。

接下来这部分一晃就是定义了一个卷积神经网络的模型结构,并从pt文件读取了模型的权重。
后面开始生成对抗样本,详细注释写在了注释里
pairs = []
for cl in range(10):#也就是递归数据集从0到9这几个文件夹
while True:
origin_image = random.choice(glob(f'test/{cl}/*.png'))#使用glob遍历test文件夹里的所有图片
image = transform(Image.open(origin_image)).to(device)[None, ...]#读取文件
label = torch.tensor(cl, device=device)#给图片正确标签放入tensor,方便生成对抗图片
adv_image = atk(image, label)#使用torchattacks生成对抗图片
origin_output = model(image)#用模型识别下原图,看看结果
adv_output = model(adv_image)#再识别下新生成的图片
origin_label = torch.argmax(origin_output, axis=1).item()#获取原图识别结果置信度最高的标签
adv_label = torch.argmax(adv_output, axis=1).item()#获取对抗图识别结果置信度最高的标签
if adv_label == origin_label:#如果生成的对抗图片和原图识别结果一样,就说明没生成好,重来
continue
transforms.ToPILImage()(adv_image[0]).save(f'adv_{origin_label}_{adv_label}.png')#如果不一样的话把对抗样本保存在工作目录
#这里再重新识别一遍刚刚保存的图片,确认下对抗样本是有效的
image = transform(Image.open(f'adv_{origin_label}_{adv_label}.png')).to(device)[None, ...]
output = model(image)
if torch.argmax(output, axis=1).item() != adv_label:
continue
#没问题的话把元组放进pairs,继续处理下一个类型图片
#元组:(原图路径,新图路径,原图正确标签,新图对抗样本的识别结果)
pairs.append((origin_image, f'adv_{origin_label}_{adv_label}.png', origin_label, adv_label))
break

后面的代码就是把数据集中的原图删除,把刚刚生成的对抗图片移到他伪造的新类型文件夹里。
重命名图片,改成数字,把对应的序号保存在adversarial_images中。(注意这里有个坑后面会提)
第97行告诉了hint1的含义,元组第一位代表原类型,第二位代表伪造后的新类型。
hint1: [(0, 1), (1, 0), (2, 6), (3, 4), (4, 3), (5, 6), (6, 5), (7, 8), (8, 7), (9, 1)]
所以这个的意思就是,在现在的数据集中,1号文件夹有一个原本是0号标签的图,0号文件夹有一个原本是1号标签的图,6号文件夹有一个原本是2号标签的图。
解题思路
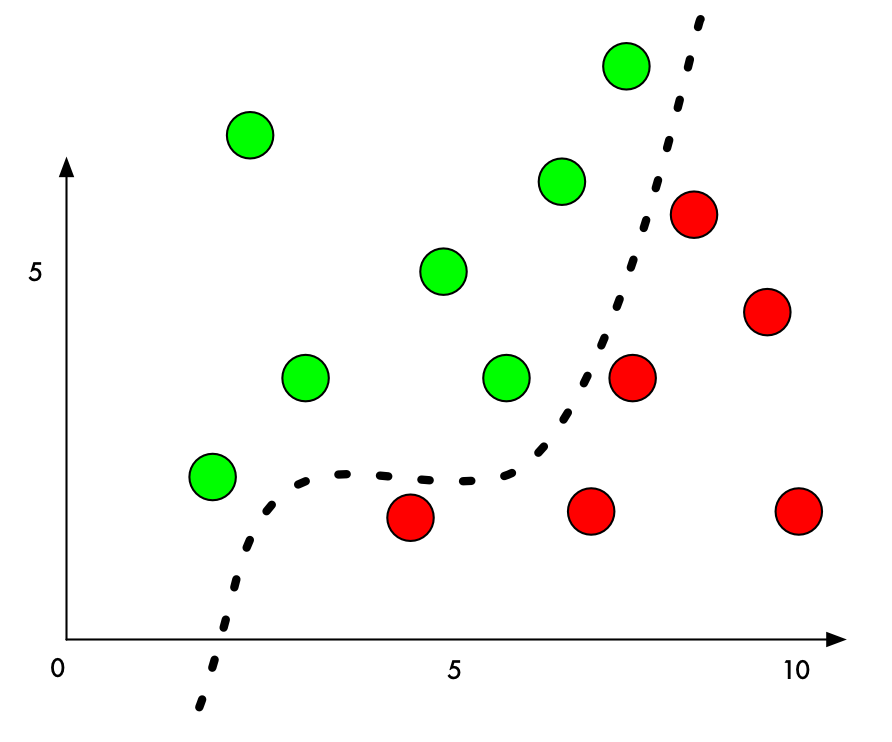
机器学习分类器的做法就是找出各个分类之间的分割线,如图

神经网络对抗的思想就是在数据上增加噪音,让他跨过这条分界线
![]()

所以我们可以想象本题生成的对抗样本的特征:
神经网络识别后打分最高的一定是伪造后的类型;第二高的极有可能是他的原类型
伪造的图片与原图差别不会太大(让人眼看不出区别),所以神经网络识别起来还是会认为他是原类型的,只是评分比伪造的类型低一点点
简单说:1.识别结果前两名评分差距小2.识别结果第二名评分高3.对照hint1,评分前两名是已知的
(在我做题过程中,单独使用条件1和条件2的结果都有一张图片提取错了,然后手搓得到的flag- -)用脚本实现的话只能把所有结果打印出来了- -
解题脚本
代码很好写,载入模型直接照抄题目给的代码就行了,我们只要按照hint1把图片全都识别一遍,按照上面的三条条件判断一下结果就行了
from glob import glob
import torch
from torch import nn, optim
import torch.nn.functional as F
from PIL import Image
import os
from torchvision import transforms
from glob import glob
from hashlib import md5
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 100, 5)
self.conv1_bn = nn.BatchNorm2d(100)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(100, 150, 3)
self.conv2_bn = nn.BatchNorm2d(150)
self.conv3 = nn.Conv2d(150, 250, 1)
self.conv3_bn = nn.BatchNorm2d(250)
self.fc1 = nn.Linear(250 * 3 * 3, 350)
self.fc1_bn = nn.BatchNorm1d(350)
self.fc2 = nn.Linear(350, 10)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = self.pool(F.elu(self.conv1(x)))
x = self.dropout(self.conv1_bn(x))
x = self.pool(F.elu(self.conv2(x)))
x = self.dropout(self.conv2_bn(x))
x = self.pool(F.elu(self.conv3(x)))
x = self.dropout(self.conv3_bn(x))
x = x.view(-1, 250 * 3 * 3)
x = F.elu(self.fc1(x))
x = self.dropout(self.fc1_bn(x))
x = self.fc2(x)
return x
# load pretrained model
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
transform = transforms.ToTensor()
model = Model().to(device)
check_point = torch.load('model.pt', map_location=device)
model.load_state_dict(check_point)
model.eval()
#确实,上面都是复制的↑↑↑↑↑
hint1= [(0, 1), (1, 0), (2, 6), (3, 4), (4, 3), (5, 6), (6, 5), (7, 8), (8, 7), (9, 1)]
adversarial_images=[]
out=[[]]
for ori,advcl in hint1:
diff1=[]#条件1
diff2=[]#条件2
diffnum=[]
for j in glob(f'./imgs/{advcl}/*.png'):
image = transform(Image.open(j)).to(device)[None, ...]
output = model(image)
label=output.data.numpy().squeeze()
score,typee=torch.sort(output,descending=True)
score=score.data.numpy().squeeze()
typee=typee.data.numpy().squeeze()
if not (typee[0]==advcl and typee[1]==ori):#判断条件3
continue
if abs(score[0]-score[1])<0.8:
diff1.append(score[0]-score[1])
diff2.append(score[0])
diffnum.append(j)
diff1=int(diffnum[diff1.index(min(diff1))].split('/')[-1].split('.')[0])
diff2=int(diffnum[diff2.index(max(diff2))].split('/')[-1].split('.')[0])
#同时判断条件1和2,不一样的话就生成一个副本
if diff1==diff2:
for i in range(len(out)):
out[i].append(diff1)
else:
ll=len(out)
for i in range(ll):
out.append(out[i].copy())
#out.append(copy.deepcopy(out[i]))
out[i].append(diff1)
for i in range(ll,len(out)):
out[i].append(diff2)
print(out)
#把每个副本打印出来,总会有一个是正确的
for adversarial_images in out:
print(adversarial_images)
flag = 'flag{' + md5(str(sorted(adversarial_images)).encode()).hexdigest() + '}'
print(flag)
非预期
哈哈哈 出题人还是太年轻了。上次WMCTF,我弄了700多张手写字符,里面有很多难以分辨的字符,居然还有师傅手搓出来。这次的很容易找出不同,很多师傅单纯靠眼睛解题,(不过这也是为了让题目更有现实意义。我想如果数据量更大一点可能会让人眼识别的师傅放弃。
还有一个问题就是按时间排序可以直接出结果,我认为出题的原始代码应该是先读取数据集,把所有图片写入到test目录,再生成对抗样本。所以对抗样本和普通数据集之间隔了几秒时间。出题师傅想到了用random.shuffle(images)来随机文件名,但是忽视了时间问题,直接使用os.rename(image, f'imgs/{cl}/{idx}.png')移动了图片。
把这个直接移动改成用pillow等库读取test目录图片再写入imgs目录的话就不会出现这个问题了。
本文作者:小帽
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/152955.html
如有侵权请联系:admin#unsafe.sh