
2019-07-28 11:20:00 Author: xz.aliyun.com(查看原文) 阅读量:138 收藏
这是内核漏洞挖掘技术系列的第十二篇。
第一篇:内核漏洞挖掘技术系列(1)——trinity
第二篇:内核漏洞挖掘技术系列(2)——bochspwn
第三篇:内核漏洞挖掘技术系列(3)——bochspwn-reloaded(1)
第四篇:内核漏洞挖掘技术系列(3)——bochspwn-reloaded(2)
第五篇:内核漏洞挖掘技术系列(4)——syzkaller(1)
第六篇:内核漏洞挖掘技术系列(4)——syzkaller(2)
第七篇:内核漏洞挖掘技术系列(4)——syzkaller(3)
第八篇:内核漏洞挖掘技术系列(4)——syzkaller(4)
第九篇:内核漏洞挖掘技术系列(4)——syzkaller(5)
第十篇:内核漏洞挖掘技术系列(5)——KernelFuzzer
第十一篇:内核漏洞挖掘技术系列(6)——TriforceAFL和KAFL
前言
之前在本系列的第二篇文章:内核漏洞挖掘技术系列(2)——bochspwn中和大家分享了double fetch漏洞原理和2013年Project Zero的j00ru开源的用bochs的插桩API实现的挖掘内核double fetch漏洞的工具bochspwn(https://github.com/googleprojectzero/bochspwn)。USENIX Security 2017上的一篇论文采用静态模式匹配的方法从Linux内核中发掘了6个未知的double fetch漏洞,这篇文章就和大家分享这篇论文中的内容。
源代码:https://github.com/UCL-CREST/doublefetch
论文地址:https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-wang.pdf
整体架构
github上的源代码含有三个文件夹。
- text-filter:文本过滤方法的源代码
- cocci:基于coccinelle引擎的模式匹配方法的源代码
- auto_fix:基于coccinelle引擎的double fetch漏洞修补工具的源代码

重点是cocci目录。cocci目录下有testdir,startcocci_linux.sh,startcocci_freebsd.sh,pattern_match_linux.cocci,pattern_match_freebsd.cocci,copy_files.py这些文件或目录。
- testdir:保存要解析的文件的目录
- startcocci_linux.sh\startcocci_freebsd.sh:启动解析的shell脚本,这个脚本将删除上次解析剩下的文件,并调用相应的cocci脚本(pattern_match_linux.cocci\pattern_match_fressbsd.cocci)来解析源文件
- pattern_match_linux.cocci\pattern_match_fressbsd.cocci:coccinelle脚本文件,它存储了我们为模式匹配添加的规则,日志记录到result.txt中
- copy_files.py:将可能存在漏洞的源代码文件复制到outcome目录,以便于人工分析

先apt-get install coccinelle安装coccinelle,然后将待解析的文件拷贝到testdir目录,运行startcocci_linux.sh或者startcocci_freebsd.sh,检查result.txt中的结果,在outcome目录下查看对应的源代码文件。
double fetch漏洞分类
在论文中,作者把double fetch漏洞分为3类:type selection,size checking和shallow copy。
将数据从用户态拷贝到内核态通常只需要调用一次转移函数。然而,如果数据含有可变的类型或者长度时就没有这么简单了。这样的数据通常由header和body两个部分组成。在接下来的部分中我们把这样的数据称为消息(message)。在拷贝消息时很容易产生double fetch漏洞。
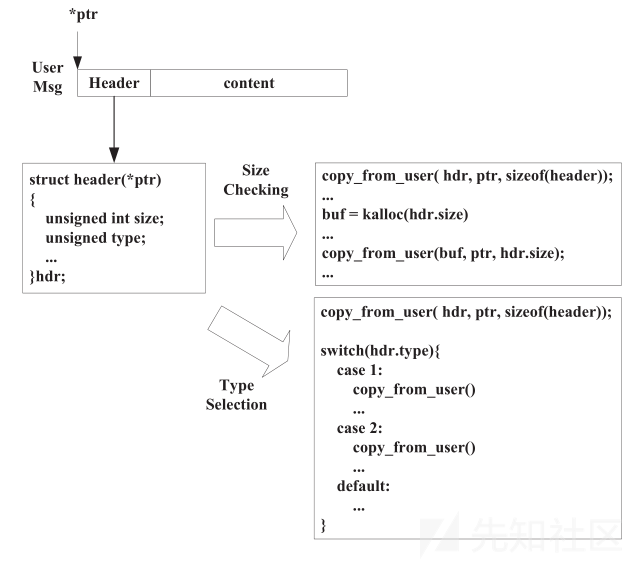
type selection
当消息头用于类型选择时,可能会出现double fetch。在此场景中,一般会首先获取消息头来识别消息类型,然后根据消息类型获取和处理整个消息。在linux内核中,一个驱动程序中的一个函数被设计成使用switch语句结构来处理多种类型的消息是非常常见的。第一次fetch的结果(消息类型)用于switch语句的条件,在switch语句的每个case中消息都通过第二次fetch复制到特定类型的本地缓冲区中进行处理。
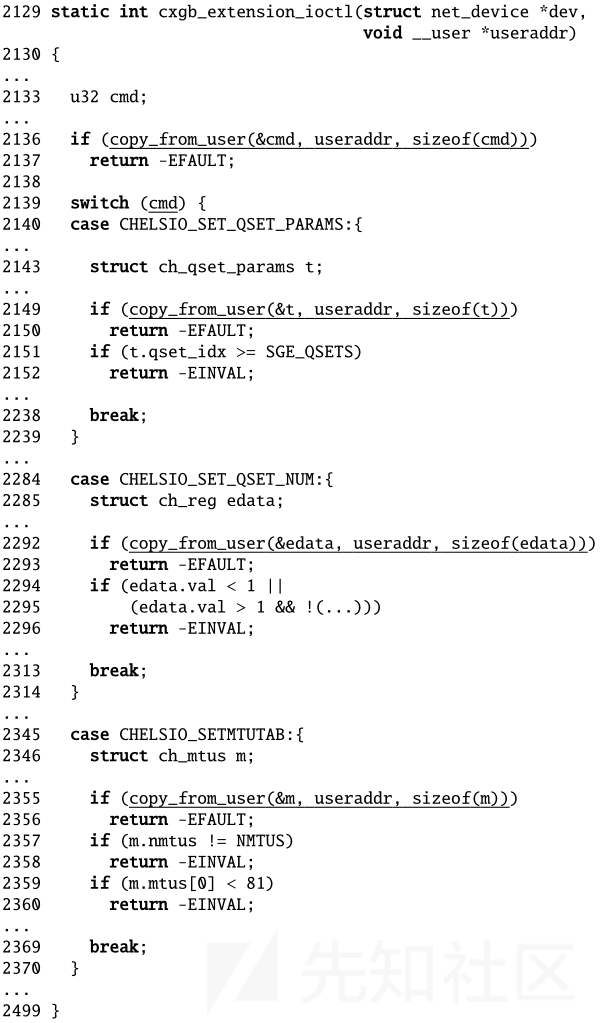
我们来看linux内核中的一个例子。cxgb_extension_ioctl函数从指向用户态的指针useraddr中获取消息类型cmd,在switch中根据cmd将整个消息拷贝到对应的结构体中。在获取整个m消息时消息类型会被第二次获取(第2149/2292/2355行)。不过因为在接下来的代码中没有用到消息类型,所以这里并不会造成漏洞。
size checking
当消息头用于标识消息大小时,可能会出现double fetch。在此场景中,一般会首先将消息头复制到内核中获取消息的大小,检查它的有效性,并分配一个必要大小的本地缓冲区,然后将整个消息(也包括消息头)复制到分配的缓冲区中。如果只使用第一次获取的消息的大小而不从第二次获取的消息中检索就不会产生漏洞。但是,如果从第二次获取的消息中检索大小并使用它就有可能产生漏洞,因为恶意用户可能已经更改了它。
我们来看linux内核中的一个例子(CVE-2016-6480)。ioctl_send_fib函数在第81行和第116行通过arg指针两次获取了用户态的数据。第一次用来计算缓冲区的大小,第二次通过计算出的大小获取整个消息。在获取整个消息之后使用了消息头中的多个元素(第121行和第129行),还使用了消息头中的Size(第130行),用户可能在两次fetch之间修改了Size的值。

shallow copy
当将用户空间中的缓冲区(第一个缓冲区)复制到内核空间,并且该缓冲区包含指向用户空间中的另一个缓冲区(第二个缓冲区)的指针时,就会发生用户空间和内核空间之间的浅拷贝。传递函数只复制第一个缓冲区,而第二个缓冲区必须通过第二次调用传递函数来复制。有时需要将数据从用户空间复制到内核空间,对数据进行操作,然后将数据复制回用户空间。此类数据通常包含在用户空间中的第二个缓冲区中,包含其它数据的用户空间中的第一个缓冲区中的指针指向它。使用只执行浅拷贝的传递函数执行深拷贝的复杂性可能会导致程序员引入漏洞。
我们来看linux内核中的一个例子(CVE-2016-6130)。sclp_ctl_ioctl_sccb函数在第61行将user_area指向的数据拷贝到ctl_sccb中,然后在第68行将ctl_sccb.sccb指向的消息头拷贝到sccb。经过第72行的检查之后在第74行将整个消息基于sccb->length拷贝到sccb。最后在第81行拷贝回用户态。第74行和第81行虽然都用的是sccb->length,但是第81行的sccb->length来源于第74行的拷贝。在第68行到第74行之间用户可能修改了sccb->length的值。不过在这里触发这个漏洞只会导致系统调用在第82行结束。

匹配模式
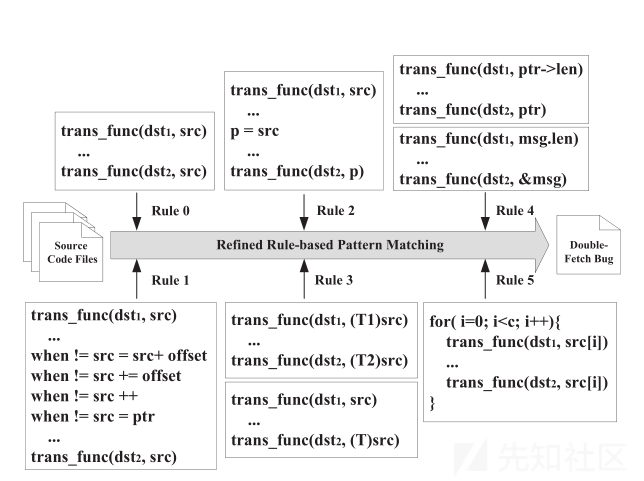
如图所示,论文一共实现了基于coccinelle引擎的6个double fetch检测的规则。感兴趣的话可以查看pattern_match_linux.cocci文件查看这些规则。Rule 0就是最基本的basic pattern,匹配对同一地址的两次读取。还有其它5个refined pattern提高精度。图中的trans_func函数表示所有从用户态获取数据的转移函数:get_user,__get_user,copy_from_user,__copy_from_user。
no pointer change
检测double fetch的最关键规则是在两次fetch操作之间保持用户指针不变。否则每次获取不同的数据而不是重复获取相同的数据可能会导致误报。从图中的规则1可以看出,这种更改可能包括自增、添加偏移量或分配另一个值的情况以及相应的减法情况。
pointer aliasing
指针混用在double fetch中很常见。在某些情况下,用户指针被分配给另一个指针,因为原始指针可能被更改(例如在循环中逐段处理长消息)。使用两个指针更方便,一个用于检查数据,另一个用于使用数据。从图中的规则2可以看出,这种赋值可能出现在函数的开头,也可能出现在两次fetch之间。
explicit type conversion
当内核从用户空间获取数据时,显式指针类型转换被广泛使用。例如,在size checking场景中,消息指针将转换为消息头指针,以便在第一次获取消息头,然后在第二次获取中再次用作消息指针。从图中的规则3可以看出,这两个源指针中的任何一个都可能涉及类型转换。
combination of element fetch and pointer fetch
在某些情况下,用户指针既可以获取整个数据结构,也可以通过将指针解引用到数据结构的元素来只获取一部分。例如,在size checking场景中,通过get_user(len,ptr->len)使用用户态指针获取消息长度,然后通过copy_from_user(msg,ptr,len)复制整个消息。两次fetch没有使用完全相同的指针,但是覆盖语义上相同的值。
loop involvement
coccinelle是路径敏感的,当一个循环出现在代码中时,循环中的一个传递函数调用将被报告为两个调用,这可能导致误报。此外,从图中的规则5可以看出,当一个循环中有两个fetch时,上一次迭代的第二个fetch和下一次迭代的第一个fetch将作为double fetch匹配。这种情况应该作为误报删除,因为这两次fetch将得到不同的值。此外,使用数组在循环中复制不同值的情况也会导致误报。
如何避免double fetch漏洞
论文作者最后也给出了几条避免double fetch漏洞的建议。
不要拷贝两次消息头
如果在第二次fetch的时候拷贝消息中除了消息头的内容而不是整个消息就不会产生漏洞了。
使用相同的值
由于攻击者可以在两次fetch之间更改数据,所以当两次fetch都使用相同的数据时就会引发漏洞。如果开发人员只使用其中一次fetch获取的数据,就可以避免问题。大多数double fetch最终都不会导致漏洞,因为它们通常只使用第一次fetch获取的数据。
覆盖数据
还有一些情况需要获取数据并使用两次,在这种情况下消除漏洞的一种方法是用第一次获取的头部覆盖第二次获取的头部。即使攻击者在两次fetch之间更改了头部,更改也不会产生影响。
比较数据
在使用前比较第一次fetch得到的数据和第二次fetch得到的数据。如果数据不相同,则必须中止操作。
同步fetch
可以使用锁或临界区这样的同步方法来保证两个不可分割操作的原子性。只要我们保证在两次fetch之间不能更改获取的值,那么就不会出现错误。但是,由于在关键部分引入了同步,这种方法会对内核造成性能损失。
总结
在IEEE S&P 2018的一篇论文Precise and Scalable Detection of Double-Fetch Bugs in OS Kernels中作者开发了一个名为DEADLINE的工具,同样基于静态方式从Linux/FreeBSD内核中发掘了多个未知的double fetch漏洞。首先使用静态分析收集内核代码中的multi-read操作,并对每一组有关联的multi-read进行符号化执行检查(符号化执行在LLVM IR层面上进行),确定是否满足double-fetch的形式化定义,一定程度上减少了本文中的工具带来的大量误报的情况。
源代码:https://github.com/sslab-gatech/deadline
论文地址:https://taesoo.kim/pubs/2018/xu:deadline.pdf
论文解读:https://zhuanlan.zhihu.com/p/59169689
有兴趣的读者可以自行查阅。
因为内核源码的变动和人工分析可能存在的疏忽,大家现在拿着这些工具去扫内核源码可能还是会扫出来一些东西的,有兴趣的读者可以自己尝试。不过我审计了一遍扫描的结果,没有发现什么有意思的问题。
之前大家分享的bochspwn采用动态方式挖掘double fetch漏洞,而这篇文章和大家分享的工具采用静态方式挖掘double fetch漏洞。简单总结一下两种方式的优劣。
1.动态挖掘由于已经导致了内核崩溃,所以大概率可以复现写出POC;静态匹配或多或少存在误报的情况,需要花费大量时间进行人工分析,并且不一定可以复现写出POC。在这种情况下,我们不一定能说服开发者修复问题。DEADLINE发现的一个double fetch就因为开发者认为虽然存在这样的条件竞争但是实际上并不能造成什么危害所以没有修复。从这一点上看动态挖掘占优势。

2.静态匹配只适用于开源系统,并且也不能发现编译优化等更深层次的原因导致的double fetch漏洞;而动态挖掘适用于开源系统和非开源系统,能够发现编译优化等深层次的原因导致的double fetch漏洞。但是动态挖掘需要用到其它fuzzer辅助提高代码覆盖率,而静态匹配能够扫描所有的源代码。从这一点上看两者各有优劣。
最后大家可以再思考一下windows系统的double fetch漏洞挖掘就真的不可以采用静态匹配的方法了么?在IDA中加载符号文件F5也能得到大致可以阅读的代码,而windows系统的double fetch漏洞也是存在一定模式的。当然这只是我一个突发奇想,大家有兴趣可以朝这个方向探索。
如有侵权请联系:admin#unsafe.sh