[This fragment is available in an audio version.]Grown-up software developers know perfectly well 2021-05-16 04:00:00 Author: www.tbray.org(查看原文) 阅读量:97 收藏
[This fragment is available in an audio version.]
Grown-up software developers know perfectly well that testing is important. But — speaking here from experience — many aren’t doing enough. So I’m here to bang the testing drum, which our profession shouldn’t need to hear but apparently does.
This was provoked by two Twitter threads (here and here) from Justin Searls, from which a couple of quotes: “almost all the advice you hear about software testing is bad. It’s either bad on its face or it leads to bad outcomes or it distracts by focusing on the wrong thing (usually tools)” and “Nearly zero teams write expressive tests that establish clear boundaries, run quickly & reliably, and only fail for useful reasons. Focus on that instead.” [Note: Justin apparently is in the testing business.]
Twitter threads twist and fork and are hard to follow, so I’m going to reach in and reproduce a couple of image grabs from one branch.

· · ·

Let me put a stake in the ground: I think those misshapen blobs are seriously wrong in important ways.
My prejudices · I’ve been doing software for money since 1979 and while it’s perfectly possible that I’m wrong, it’s not for lack of experience. Having said that, almost all my meaningful work has been low-level infrastructural stuff: Parsers, message routers, data viz frameworks, Web crawlers, full-text search. So it’s possible that some of my findings are less true once you get out of the infrastructure space.
History · In the first twenty years of my programming life, say up till the turn of the millennium, there was shockingly little software testing in the mainstream. One result was, to quote Gerald Weinberg’s often-repeated crack, “If builders built buildings the way programmers wrote programs, then the first woodpecker that came along would destroy civilization.”
Back then it seemed that for any piece of software I wrote, after a couple of years I started hating it, because it became increasingly brittle and terrifying. Looking back in the rear-view, I’m thinking I was reacting to the experience, common with untested code, of small changes unexpectedly causing large breakages for reasons that are hard to understand.
Sometime in the first decade of this millennium, the needle moved. My perception is that the initial impetus came at least partly out of the Ruby community, accelerated by the rise of Rails. I started to hear the term “test-infected”, and I noticed that code submissions were apt to be coldly rejected if they weren’t accompanied by decent unit tests.
Others have old me they initially got test-infected by the conversation around Martin Fowler’s Refactoring book, originally from 1999, which made the point that you can’t really refactor untested code.
In particular I remember attending the Scottish Ruby Conference in 2010 and it seemed like more or less half the presentations were on testing best-practices and technology. I learned lessons there that I’m still using today.
I’m pretty convinced that the biggest single contributor to improved software in my lifetime wasn’t object-orientation or higher-level languages or functional programming or strong typing or MVC or anything else: It was the rise of testing culture.
What I believe · The way we do things now is better. In the builders-and-programmers metaphor, civilization need not fear woodpeckers.
For example: In my years at Google and AWS, we had outages and failures, but very very few of them were due to anything as simple as a software bug. Botched deployments, throttling misconfigurations, cert problems (OMG cert problems), DNS hiccups, an intern doing a load test with a Python script, malfunctioning canaries, there are lots of branches in that trail of tears. But usually not just a bug.
I can’t remember when precisely I became infected, but I can testify: Once you are, you’re never going to be comfortable in the presence of untested code.
Yes, you could use a public toilet and not wash your hands. Yes, you could eat spaghetti with your fingers. But responsible adults just don’t do those things. Nor do they ship untested code. And by the way, I no longer hate software that I’ve been working on for a while.
I became monotonically less tolerant of lousy testing with every year that went by. I blocked promotions, pulled rank, berated senior development managers, and was generally pig-headed. I can get away with this (mostly) without making enemies because I’m respectful and friendly and sympathetic. But not, on this issue, flexible.
So, here’s the hill I’ll die on (er, well, a range of foothills I guess):
Unit tests are an essential investment in your software’s future.
Test coverage data is useful and you should keep an eye on it.
Untested legacy code bases can and should be improved incrementally
Unit tests need to run very quickly with a single IDE key-combo, and it’s perfectly OK to run them every few seconds like a nervous tic.
There’s no room for testing religions; do what works.
Unit tests empower code reviewers.
Integration tests are super important and super hard, particularly in a microservices context.
Integration tests need to pass 100%, it’s not OK for there to be failures that are ignored.
Integration tests need to run “fast enough“.
It’s good for tests to include benchmarks.
Now I’ll expand on the claims in that list. Some of them need no further defense (e.g. “unit tests should run fast”) and will get none. But first…
Can you prove it works? · Um, nope. I’ve looked around for high-quality research on testing efficacy, and didn’t find much.
Which shouldn’t be surprising. You’d need to find two substantial teams doing nontrivial development tasks where there is rough-or-better equivalence in scale, structure, tooling, skill levels, and work practices — in everything but testing. Then you’d need to study productivity and quality over a decade or longer. As far as I know, nobody’s ever done this and frankly, I’m not holding my breath. So we’re left with anecdata, what Nero Wolfe called “Intelligence informed by experience.”
So let’s not kid ourselves that our software-testing tenets constitute scientific knowledge. But the world has other kinds of useful lessons, so let’s also not compromise on what our experience teaches us is right.
Unit tests matter now and later · When you’re creating a new feature and implementing a bunch of functions to do it, don’t kid yourself that you’re smart enough, in advance, to know which ones are going to be error-prone, which are going to be bottlenecks, and which ones are going to be hard for your successors to understand. Nobody is smart enough! So write tests for everything that’s not a one-line accessor.
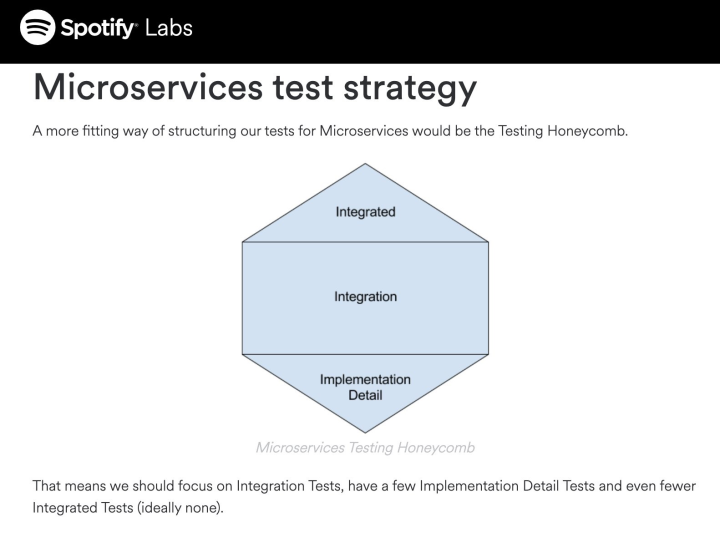
In case it’s not obvious, the graphic above from Spotify that dismisses unit testing with the label “implementation detail”
offends me. I smell Architecture Astronautics here, people who think all the work is getting the boxes and arrows right on the
whiteboard, and are above dirtying their hands with semicolons and if statements. If your basic microservice code
isn’t well-tested you’re building on sand.
Working in a well-unit-tested codebase gives developers courage. If a little behavior change would benefit from re-implementing an API or two you can be bold, can go ahead and do it. Because with good unit tests, if you screw up, you’ll find out fast.
And remember that code is read and updated way more often than it’s written. I personally think that writing good tests helps the developer during the first development pass and doesn’t slow them down. But I know, as well as I know anything about this vocation, that unit tests give a major productivity and pain-reduction boost to the many subsequent developers who will be learning and revising this code. That’s business value!
Exceptions · Where can we ease up on unit-test coverage? Back in 2012 I wrote about how testing UI code, and in particular mobile-UI code, is unreasonably hard, hard enough to probably not be a good investment in some cases.
Here’s another example, specific to the Java world, where in the presence of dependency-injection frameworks you have huge files with literally thousands of lines of config gibberish [*cough* Spring Boot *cough*] and life’s just too short.
A certain number of exception-handling scenarios are so far-fetched that you’d expect your data center to be in flames before
they happen, at which point an IOException is going to be the least of your troubles. So maybe don’t obsess about
those particular if err != nil clauses.
Coverage data · I’m not dogmatic about any particular codebase hitting any particular coverage number. But the data is useful and you should pay attention to it.
First of all, look for anomalies: Files that have noticeably low (or high) coverage numbers. Look for changes between check-ins.
And coverage data is more than just a percentage number. When I’m most of the way through some particular piece of programming, I like to do a test run with coverage on and then quickly glance at all the significant code chunks, looking at the green and red sidebars. Every time I do this I get surprises, usually in the form of some file where I thought my unit tests were clever but there are huge gaps in the coverage. This doesn’t just make me want to improve the testing, it teaches me something I didn’t know about how my code is reacting to inputs.
Having said that, there are software groups I respect immensely who have hard coverage requirements and stick to them. There’s one at AWS that actually has a 100%-coverage blocking check in their CI/CD pipeline. I’m not sure that’s reasonable, but these people are doing very low-level code on a crucial chunk of infrastructure where it’s maybe reasonable to be unreasonable. Also they’re smarter than me.
Legacy code coverage · I have never, and mean never, worked with a group that wasn’t dragging along weakly-tested legacy code. Even a testing maniac like me isn’t gong to ask anyone to retro-fit high-coverage unit testing onto that stinky stuff.
Here’s a policy I’ve seen applied successfully; It has two parts: First, when you make any significant change to a function that doesn’t have unit tests, write them. Second, no check-in is allowed to make the coverage numbers go down.
This works out well because, when you’re working with a big old code-base, updates don’t usually scatter uniformly around it; there are hot spots where useful behavior clusters. So if you apply this policy, the code’s “hot zone” will organically grow pretty good test coverage while the rest, which probably hasn’t been touched or looked at for years, is ignored, and that’s OK.
No religion · Testing should be an ultimately-pragmatic activity with no room for ideology.
Please don’t come at me with pedantic arm-waving about mocks vs stubs vs fakes; nobody cares. On a related subject, when I discovered that lots of people were using DynamoDB Local in their unit tests for code that runs against DynamoDB, I was shocked. But hey, it works, it’s fast, and it’s a lot less hassle than either writing yet another mock or setting up a linkage to the actual cloud service. Don’t be dogmatic!
Then there’s the TDD/BDD faith. Sometimes, for some people, it works fine. More power to ’em. It almost never works for me in a pure form, because my coding style tends to be chaotic in the early stages, I keep refactoring and refactoring the functions all the time. If I knew what I wanted them to do before I started writing them, then TDD might make sense. On the other hand, when I’ve got what I think is a reasonable set of methods sketched in and I’m writing tests for the basic code, I’ll charge ahead and write more for stuff that’s not there yet. Which doesn’t qualify me for a membership of the church of TDD but I don’t care.
Here’s another religion: Java doesn’t make it easy to unit-test private methods. Java is wrong. Some people claim you shouldn’t want to test those methods because they’re not part of the class contract. Those people are wrong. It is perfectly reasonable to compromise encapsulation and make a method non-private just to facilitate testing. Or to write an API to take an interface rather than a class object for the same reason.
When you’re running a bunch of tests against a complicated API, it’s tempting to write a runTest() helper
that puts the arguments in the right shape and runs standardized checks against the results. If you don’t do this, you end up
with a lot of repetitive cut-n-pasted code.
There’s room for argument here, none for dogma. I’m usually vaguely against doing this. Because when I change something and a unit test I’ve never seen before fails, I don’t want to have to go understand a bunch of helper routines before I can figure out what happened.
Anyhow, if your engineers are producing code with effective tests, don’t be giving them any static about how it got that way.
The reviewer’s friend · Once I got a call out of the blue from a Very Important Person saying “Tim, I need a favor. The [REDACTED] group is spinning their wheels, they’re all fucked up. Can you have a look and see if you can help them?” So I went over and introduced myself and we talked about the problems they were facing, which were tough.
Then I got them to show me the codebase and I pulled up a few review requests. The first few I looked at had no unit tests but did have notes saying “Unit tests to come later.” I walked into their team room and said “People, we need to have a talk right now.”
[Pause for a spoiler alert: The unit tests never come along later.]
Here’s the point: The object of code reviewing is not correctness-checking. A reviewer is entitled to assume that the code works. The reviewer should be checking for O(N3) bottlenecks, readability problems, klunky function arguments, shaky error-handling, and so on. It’s not fair to ask a reviewer to think about that stuff if you don’t have enough tests to demonstrate your code’s basic correctness.
And it goes further. When I’m reviewing, it’s regularly the case that I have trouble figuring out what the hell the developer is trying to accomplish in some chunk of code or another. Maybe it’s appropriate to put in a review comment about readability? But first, I flip to the unit test and see what it’s doing, because sometimes that makes it obvious what the dev thought the function was for. This also works for subsequent devs who have to modify the code.
Integration testing · The people who made the pictures up above all seem to think it’s important. They’re right, of course. I’m not sure the difference between “integration” and “end-to-end” matters, though.
The problem is that moving from monoliths to microservices, which makes these tests more important, also makes them harder to build. Which is another good reason to stick with a nice simple monolith if you can. No, I’m not kidding.
Which in turn means you have to be sure to budget time, including design and maintenance time, for your integration testing. (Unit testing is just part of the basic coding budget.)
Complete and fast · I know I find these hard to write and I know I’m not alone because I’ve worked with otherwise-excellent teams who have crappy integration tests.
One way they’re bad is that they take hours to run. This is hardly controversial enough to worth saying but, since it’s a target that’s often missed, let’s say it: Integration tests don’t need to be as quick as unit tests but they do need to be fast enough that it’s reasonable to run them every time you go to the bathroom or for coffee, or get interrupted by a chat window. Which, once again, is hard to achieve.
Finally, time after time I see integration-test logs show failures and some dev says “oh yeah, those particular tests are flaky, they just fail sometimes.” For some reason they think this is OK. Either the tests exercise something that might fail in production, in which case you should treat failures as blockers, or they don’t, in which case you should take them out of the damn test suite which will then run faster.
Benchmarks · Since I’ve almost always worked on super-performance-sensitive code, I often end up writing benchmarks, and after a while I got into the habit of leaving a few of them live in the test suite. Because I’ve observed more than a few outages caused by a performance regression, something as dumb as a config tweak pushing TLS compute out of hardware and into Java bytecodes. You’d really rather catch that kind of thing before you push.
Tooling · There’s plenty. It’s good enough. Have your team agree on which they’re going to use and become expert in it. Then don’t blame tools for your shortcomings.
Where we stand · The news is I think mostly good, because most sane organizations are starting to exhibit pretty good testing discipline, especially on server-side code. And like I said, this old guy sees a lot less bugs in production code than there used to be.
And every team has to wrestle with those awful old stagnant pools of untested legacy. Suck it up; dealing with that is just part of the job. Anyhow, you probably wrote some of it.
But here and there every day, teams lose their way and start skipping the hand-wash after the toilet visit. Don’t. And don’t ship untested code.
如有侵权请联系:admin#unsafe.sh