In the late 1990s, the Windows Shell and Internet Explorer teams introduced a lot of brilliant a 2021-06-03 02:25:05 Author: textslashplain.com(查看原文) 阅读量:125 收藏
In the late 1990s, the Windows Shell and Internet Explorer teams introduced a lot of brilliant and intricate designs that allowed intricate extension of the shell and the browser to handle scenarios beyond what those built by Microsoft itself. For instance, Internet Explorer supported the notion of pluggable protocols (“What if some protocol, say, FTPS becomes as important as HTTP?”) and the Windows Shell offered an extremely flexible set of abstract browsing of namespaces, enabling third parties to build browsable “folders” not backed by the file system– everything from WebDAV (“your HTTP-server is a folder“) to CAB Folders (“your CAB archive is a folder“). As a PM on the clipart team in 2004, I built a .NET-based application to browse clipart from the Office web services, and I sketched out an initial design for a Windows Shell extension that would make it look like Microsoft’s enormous web-based clipart archive were installed in a local folder on your system.
Perhaps the most popular (or infamous) example of a shell namespace extension is the Windows ZIP Folders extension, which handles the exploration of ZIP files. First introduced in the Windows 95 Plus Pack and later included with Windows itself, ZIP Folders allows billions of Windows users to interact with ZIP files without downloading third-party software. Perhaps surprisingly, the feature was itself was acquired from two third-parties — Microsoft acquired the Explorer integration from Dave Plummer’s “side project”, while a company called InnerMedia claims credit for the “DynaZIP” engine underneath.
Unfortunately, the code hasn’t really been updated in a while. A long while. The timestamp in the module claims it was last updated on Valentine’s Day 1998, and while I suspect there may’ve been a fix here or there since then (and one feature, extract-only Unicode filename support), it’s no secret that the code is, as Raymond Chen says: “stuck at the turn of the century.” That means that it doesn’t support “modern” features like AES encryption, and its performance (runtime, compression ratio) is known to be dramatically inferior to modern 3rd-party implementations.
So, why hasn’t it been updated? Well, “if it aint broke, don’t fix it” accounts for part of the thinking– the ZIP Folders implementation has survived in Windows for 23 years without the howling of customers becoming unbearable, so there’s some evidence that users are happy enough.
Unfortunately, there are degenerate cases where the ZIP Folders support really is broken. I ran across one of those yesterday. I had seen an interesting Twitter thread about hex editors that offer annotation (useful for exploring file formats) and decided to try a few out (I decided I like ReHex best). But in the process, I downloaded the portable version of ImHex and tried to move it to my Tools folder.
I did so by double-clicking the 11.5mb ZIP to open it. I then hit CTRL+A to select all of the files within, and (spoiler alert) CTRL+X to cut the files to my clipboard.

I then created a new subfolder in my Tools folder and hit CTRL+V to paste. And here’s where everything went off the rails– Windows spent well over a minute showing “Calculating…” with no visible progress beyond the creation of a single subfolder with a single 5k file within:

Huh? I knew that the ZIP engine beneath ZIP Folders wasn’t well-optimized, but I’d never seen anything this bad before. After waiting a few more minutes, another file extracted, this one 6.5 mb:

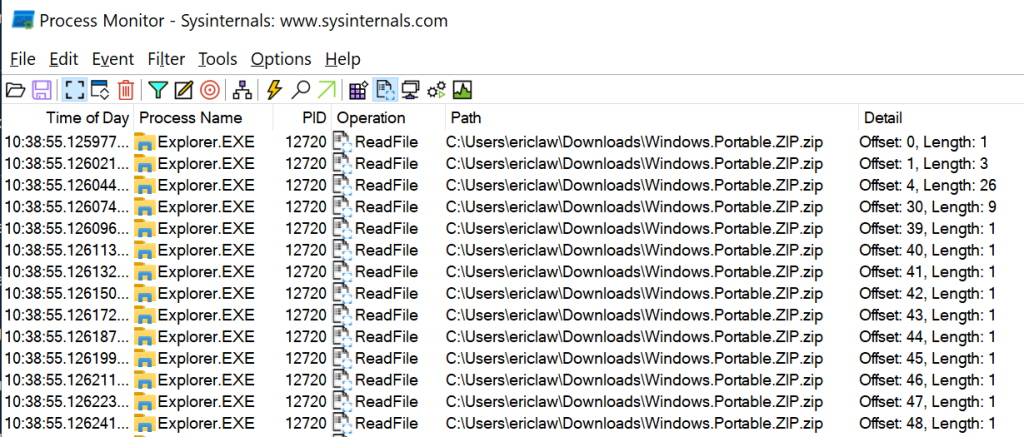
This is madness. I opened Task Manager, but nothing seemed to be using up much of my 12 thread CPU, my 64gb of memory, or my NVMe SSD. Finally, I opened up SysInternals’ Process Monitor to try to see what was going on and the root cause of the problem was quickly seen. After some small reads from the end of the file (where the ZIP file keeps its index), the entire 11 million byte file was being read from disk a single byte at a time:

Looking more closely, I realized that the reads were almost all a single byte, but every now and then, after a specific 1 byte read, a 15 byte read was issued:

What’s at those special bytes (330, 337)? 0x50, aka the letter P.

Having written some trivial ZIP-recovery code in the past, I know what’s special about the character P in ZIP files– it’s the first byte of the ZIP format’s block markers, each of which start with 0x50 0x4B. So what’s plainly happening here is that the code is reading the file from start to finish looking for a particular block header, 16 bytes in size. Each time it hits a P, it looks at the next 15 bytes to see if they match the correct signature, but if not, it continues scanning byte-by-byte, looking for the next P.
Making matters worse, this “read the file, byte by byte” pattern doesn’t just happen once– it happens at least once for every file extracted. Eventually, after about 85 million single byte reads, Process Monitor hangs:

After restarting and configuring Process Monitor with Symbols, we can examine the one-byte reads and get a hint of what’s going on:

The GetSomeBytes function is getting hammered with calls passing a single byte buffer, in a tight loop inside the readzipfile function. But look down the stack and the root cause of the madness becomes clear– this is happening because after each file is “moved” from the ZIP to the target folder, the ZIP file must be updated to delete the file that was “moved.” This deletion process is inherently not fast (because it results in shuffling all of the subsequent bytes of the file and updating the index), and as implemented in the readzipfile function (with its one-byte read buffer) is atrociously slow.
Back up in my repro steps, note that I hit CTRL+X to “Cut” the files, resulting in a Move operation. Had I instead hit CTRL+C to “Copy” the files, resulting in a Copy operation, the ZIP folder would not have performed a delete operation as each file was extracted. The time required to unpack the ZIP file drops from over thirty minutes to four seconds. For perspective, 7-Zip unpacks the file in under a quarter of a second, although it cheats a little.
And here’s where the abstraction leaks— from a user’s point-of-view, copying files out of a ZIP file (then deleting the ZIP) vs. moving the files from a ZIP file seems like it shouldn’t be very different. Unfortunately, the abstraction fails to fully paper over the reality that deleting from a ZIP file is an extremely slow operation, while deleting a file from a disk is usually trivial. As a consequence, the Zip Folder abstraction works well for tiny ZIPs, but fails for the larger ZIP files that are becoming increasingly common.
While it’s relatively easy to think of ways to dramatically improve the performance of this scenario, precedent suggests that the code in Windows is unlikely to be improved anytime soon. Perhaps for its 25th Anniversary? 🤞
– Eric
如有侵权请联系:admin#unsafe.sh