2019-08-12 18:30:00 Author: paper.seebug.org(查看原文) 阅读量:207 收藏
Author:Longofo@Knownsec 404 Team
Time: August 8, 2019
Chinese Version: https://paper.seebug.org/1009/
Introduction
On August 1st, 2019, Apache Solr officially released a vulnerability. The DataImportHandler, an optional but popular module to pull in data from databases and other sources, has a feature in which the whole DIH configuration can come from a request's "dataConfig" parameter. The debug mode of the DIH admin screen uses this to allow convenient debugging / development of a DIH config. Since a DIH config can contain scripts, this parameter is a security risk. Starting with version 8.2.0 of Solr, use of this parameter requires setting the Java System property "enable.dih.dataConfigParam" to true.
I made an emergency for this vulnerability. The constructed PoC is not so good, because it needs a database driver to connect the database and there is no echo. So it is difficult to use. Later, new PoCs were gradually constructed. After several versions of PoC upgrades, these problem were all fixed. I have recorded the PoC upgrade process and some of the problems I have encountered. At last, I'd like to thank @Badcode and @fnmsd for their help.
Environment
The Solr-related environment involved in the analysis is as follows:
- Solr-7.7.2
- JDK 1.8.0_181
At first, I didn't go through the related information of Solr carefully. I just flipped through the document and made recurrence. At that time, I thought that the data should be able to be echoed. So I started debugging and tried to construct the echo, but it didn't work. Later, I saw the new PoC. I felt that I had not really understood the principle of this vulnerability and went to blind debugging. So I went back and looked at those documentation. Here are some concepts related to the vulnerability.
Mechanism
1.Solr is encapsulated on the basis of the Lucene toolkit and provides external indexing functions in the form of web services.
2.When the business system needs to create indexes and search by indexes, it can send http request and parse returned data.
(1) Construction of index data
According to the configuration file, extract some data for searching (packaged into various Fields), repackage each field into document, and analyze the document (separating every fields) to get some index directories. The document itself will also be written to a information database.
(2) Query of index data
Parse query condition (Termquery) according to the key word, use the tool (indexSearcher) to obtain the document id from index library, and then use this id to obtain document information from the database.
Solr DataImportHandler
Solr DataImportHandler can import data into the index library in batches. According to the description in Solr Document, DataImportHandler has The following functions:
- Read data residing in relational databases
- Build Solr documents by aggregating data from multiple columns and tables according to configuration
- Update Solr with such documents
- Provide ability to do full imports according to configuration
- Detect inserts/update deltas (changes) and do delta imports (we assume a last-modified timestamp column for this to work)
- Schedule full imports and delta imports
- Read and Index data from xml/(http/file) based on configuration
- Make it possible to plugin any kind of datasource (ftp,scp etc) and any other format of user choice (JSON,csv etc)
Through the official documentation and information I researched, I made a general flow chart of DataImport processing as follows (only the main parts related to the vulnerability are drawn):
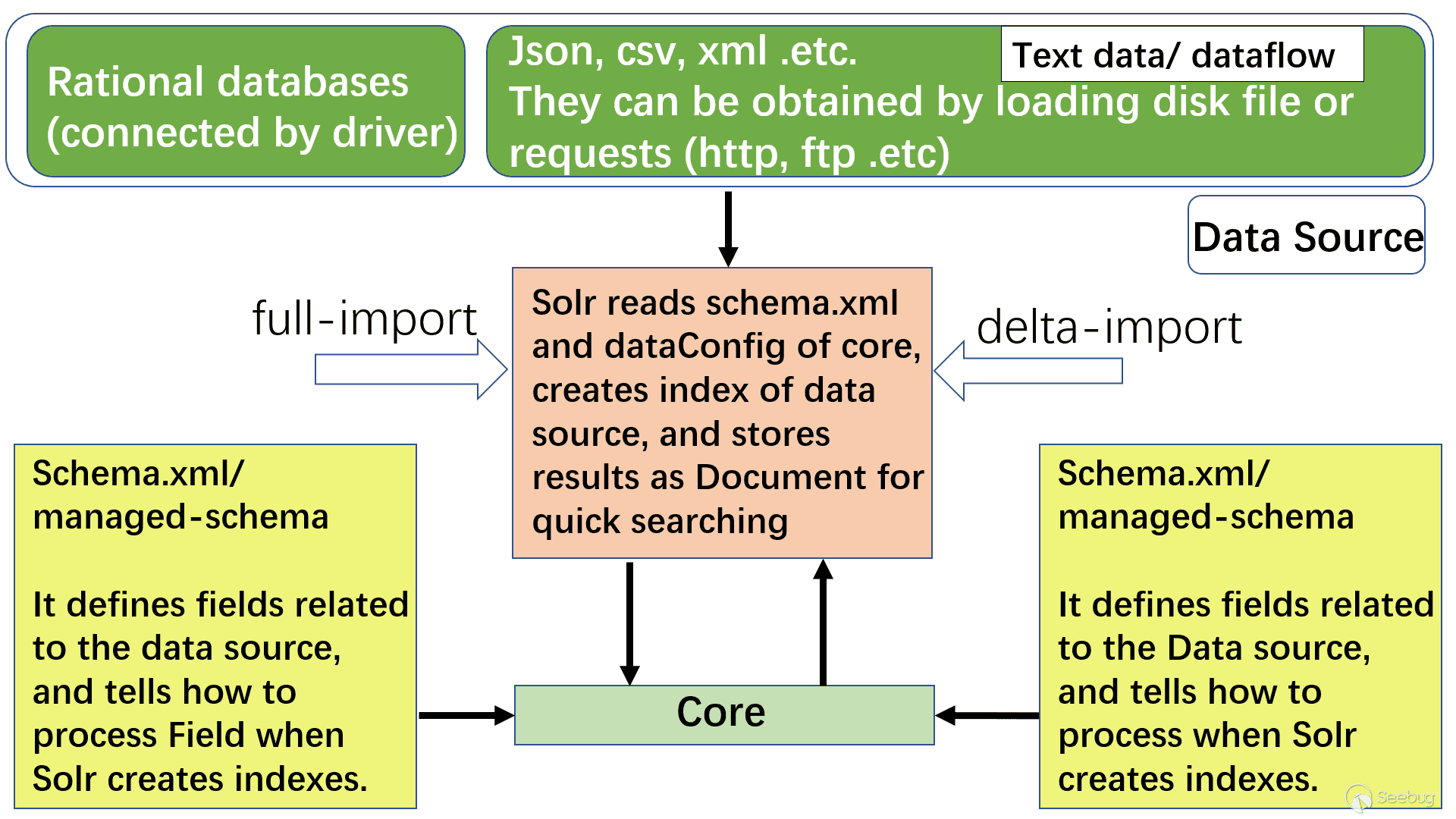
A few nouns explain:
- Core: Core is an index library which contains schema.xml/managed-schema. Schema.xml is the traditional name of the schema file, which can be manually edited by the user. Managed-schema is the name of the schema file used by Solr, which can be changed dynamically at runtime. The data-config file can be configured as xml or passed by request parameter (can be passed through the dataConfig parameter when dataimport is in debug mode)
Create a core:

The -d parameter is the specified configuration template. Under solr 7.7.2, there are two templates: _default and sample_techproducts_configs
Create a core via a web page
At first I thought that I couldn't create a core from the web page. Although there is an Add Core, the core directory created by clicking on it is empty. I can't find the configuration file. I have to create the corresponding core in the solr directory and add it in the web interface. Then try to use the absolute path configuration, the absolute path can also be seen in the web interface, but solr does not allow the configuration file other than the created core directory by default, if this switch is set to true, you can use the configuration outside the corresponding core file:
Later, when I look back, I found in the Solr Guide 7.5 document that the core can also be created by the configSet parameter. configSet can Specified as _default and sample_techproducts_configs, the following indicates that the creation was successful, but the core created in this way has no conf directory, and its configuration is equivalent to linking to the configSet template instead of using the copy template:

Core can be created in the above two ways, but to use the dataimport function, you still need to edit the configuration solrconfig.xml file. If you can change the configuration file through web request to configure the dataimport function, you can make better use of this vulnerability.
- Schema.xml/managed-schema: This defines the field associated with the data source (Field) and how to handle Field when Solr builds the index. You can open the schema.xml/managed-schema under the newly created core to watch its content. The content is too long, I don't paste it.
explaining several elements related to the vulnerability:
Field: The definition of the domain, equivalent to the field of the data source
Name: the name of the domain
Type: the type of the domain
Indexed: Whether to index
Stored: Whether to store
multiValued: whether it has multiple values, if yes, it can maintain multiple values in one domain
example:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
dynamicField: dynamic domain, the last stage of PoC is echoed according to this. Dynamic field definitions allow the use of conventions over configuration. Field names were matched by pattern specification.
Example: name ="*_i" will match any field in dataConfig that ends with _i (eg myid_i, z_i)
Restriction: Patterns like glob in the name attribute must have "*" only at the beginning or end.
The meaning is that when dataConfig inserts data and finds that a domain is not defined, you can use the dynamic domain as the field name for data storage. This will be seen in the evolution of PoC later.
example:
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>- ataConfig: This configuration item can be passed through file configuration or by request (you can pass dataConfig parameter when dataimport starts Debug mode). How to get data (query statement, url, etc.) when reading how to read data (relationship) The column in the database, or the domain of the xml), what kind of processing (modification/add/delete), etc. Solr creates an index for the data and saves the data as a Document.
an index for the data and saves the data as a Document.
You need to understand the following elements of dataConfig:
Transformer: Every set of fields fetched by the entity can be either consumed directly by the indexing process or they can be massaged using transformers to modify a field or create a totally new set of fields, it can even return more than one row of data. The transformers must be configured on an entity level
RegexTransformer: It helps in extracting or manipulating values from fields (from the source) using Regular Expressions
ScriptTransformer: It is possible to write transformers in Javascript or any other scripting language supported by Java
DateFormatTransformer: It is useful for parsing date/time strings into java.util.Date instances
NumberFormatTransformer: Can be used to parse a number from a String
TemplateTransformer: Can be used to overwrite or modify any existing Solr field or to create new Solr fields
HTMLStripTransformer: Can be used to strip HTML out of a string field
ClobTransformer: Can be used to create a String out of a Clob type in database
LogTransformer: Can be used to Log data to console/logs
EntityProcessor: Each entity is handled by a default Entity processor called SqlEntityProcessor. This works well for systems which use RDBMS as a datasource
SqlEntityProcessor: This is the defaut. The DataSource must be of type DataSource<Iterator<Map<String, Object>>> . JdbcDataSource can be used with this
XPathEntityProcessor: Used when indexing XML type data
FileListEntityProcessor: A simple entity processor which can be used to enumerate the list of files from a File System based on some criteria. It does not use a DataSource
CachedSqlEntityProcessor: This is an extension of the SqlEntityProcessor. This EntityProcessor helps reduce the no: of DB queries executed by caching the rows. It does not help to use it in the root most entity because only one sql is run for the entity
PlainTextEntityProcessor: This EntityProcessor reads all content from the data source into an single implicit field called 'plainText'. The content is not parsed in any way, however you may add transformers to manipulate the data within 'plainText' as needed or to create other additional fields
LineEntityProcessor: This EntityProcessor reads all content from the data source on a line by line basis, a field called 'rawLine' is returned for each line read. The content is not parsed in any way, however you may add transformers to manipulate the data within 'rawLine' or to create other additional fields
SolrEntityProcessor: This EntityProcessor imports data from different Solr instances and cores
DataSource:A class can extend org.apache.solr.handler.dataimport.DataSource and can be used as a DataSource.
JdbcDataSource: This is the default.
URLDataSource: This datasource is often used with XPathEntityProcessor to fetch content from an underlying file:// or http:// location
HttpDataSource: is being deprecated in favour of URLDataSource in Solr1.4. There is no change in functionality between URLDataSource and HttpDataSource, only a name change.
FileDataSource: This can be used like an URLDataSource but used to fetch content from files on disk. The only difference from URLDataSource, when accessing disk files, is how a pathname is specified
FieldReaderDataSource: This can be used like an URLDataSource
ContentStreamDataSource: Use this to use the POST data as the DataSource. This can be used with any EntityProcessor that uses a DataSource <Reader>
The entity for an xml/http data source can have the following attributes over and above the default attributes
processor (required) : The value must be "XPathEntityProcessor"
url (required) : The url used to invoke the REST API. (Can be templatized). if the data souce is file this must be the file location
stream (optional) : set this to true , if the xml is really big
forEach(required) : The xpath expression which demarcates a record. If there are multiple types of record separate them with " | " (pipe) . If useSolrAddSchema is set to 'true' this can be omitted
xsl(optional): This will be used as a preprocessor for applying the XSL transformation. Provide the full path in the filesystem or a url
useSolrAddSchema(optional): Set it's value to 'true' if the xml that is fed into this processor has the same schema as that of the solr add xml. No need to mention any fields if it is set to true
flatten (optional) : If this is set to true, text from under all the tags are extracted into one field , irrespective of the tag name.
The entity fields can have the following attributes (over and above the default attributes):
xpath (optional) : The xpath expression of the field to be mapped as a column in the record . It can be omitted if the column does not come from an xml attribute (is a synthetic field created by a transformer). If a field is marked as multivalued in the schema and in a given row of the xpath finds multiple values it is handled automatically by the XPathEntityProcessor. No extra configuration is required
commonField : can be (true| false) . If true, this field once encountered in a record will be copied to other records before creating a Solr document PoC Evolution
The first phase -- database driver + external connection + no echo
According to the official vulnerability warning description, a DIH config can contain scripts. There is an example of a ScriptTransformer I found in [Documents] (https://cwiki.apache.org/confluence/display/SOLR/DataImportHandler):
We can see that the java code can be executed in the script. Construct PoC (see the related error message through logs to view the problem of the PoC structure). This database can be externally connected, so the related information of the database can be controlled by itself.
In the example of ScriptTransformer, you can see the word row.put. Maybe we can get the echo. Test it:
Here we can see the id field but cannot see the name field. There is no error in logs. I tried to put the data into the id:

We can see the information that is echoed. At first I didn't know why putting to name failed, but when I saw the PoC in the third stage and then went back to find information, I realized that dataConfig and schema should be used together. The name field is not configured in the schema, but the fileid id is defined by default, so solr does not put the name field data into the Document but it will put the id field. In the third phase of PoC, the name attribute in each Field has "_s". I searched to find that dynamicField can be configured in the schema configuration file. The following is the default configured dynamicField:
In the above related concepts, this field is introduced. And it passed the test:
As long as the dynamicField can match the name attribute of the field in the dataConfig, Solr will be automatically added to the document. If the schema is configured with the corresponding field, the configured field will take precedence. If there is no configuration, it will match according to the dynamicField.
The second phase -- external connection + no echo
In the documentation, JdbcDataSource can use JNDI,
Test if we can do the injection:
There is a malicious demo of JNDI+LDAP and it does not require the goal CLASSPATH to have a database driver.
The third phase -- no external connection + echo
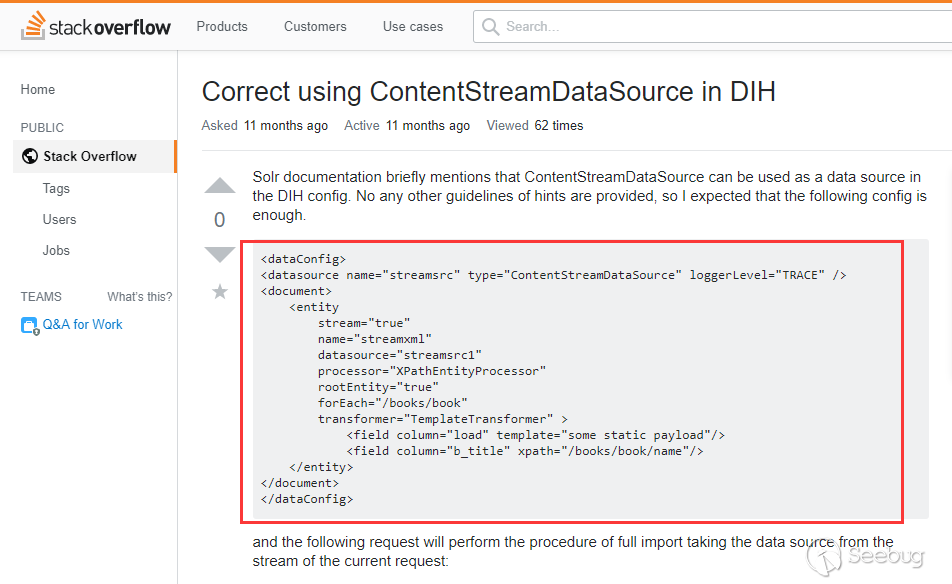
@fnmsd made this PoC by using [ContentStreamDataSource] (https://cwiki.apache.org/confluence/display/SOLR/DataImportHandler#), which is not described in the documentation. I found an example in stackoverflower
The ContentStreamDataSource can receive Post data as a data source. We can get a echo by combining it with the dynamicField mentioned in the first stage.
And here is the result.
After going back to look at other types of DataSources, you can also use URLDataSource/HttpDataSource. An example is provided in the documentation:

Constructing a test is also possible, you can use protocols such as http, ftp, etc.
Reference link
- https://cwiki.apache.org/confluence/display/SOLR/DataImportHandler#DataImportHandler-URLDataSource
- https://lucene.apache.org/solr/guide/7_5/
- https://stackoverflow.com/questions/51838282/correct-using-contentstreamdatasource-in-dih
- https://www.cnblogs.com/peaceliu/p/7786851.html
Beijing Knownsec Information Technology Co., Ltd. was established by a group of high-profile international security experts. It has over a hundred frontier security talents nationwide as the core security research team to provide long-term internationally advanced network security solutions for the government and enterprises.
Knownsec's specialties include network attack and defense integrated technologies and product R&D under new situations. It provides visualization solutions that meet the world-class security technology standards and enhances the security monitoring, alarm and defense abilities of customer networks with its industry-leading capabilities in cloud computing and big data processing. The company's technical strength is strongly recognized by the State Ministry of Public Security, the Central Government Procurement Center, the Ministry of Industry and Information Technology (MIIT), China National Vulnerability Database of Information Security (CNNVD), the Central Bank, the Hong Kong Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of security vulnerability and offensive and defensive technology in the fields of Web, IoT, industrial control, blockchain, etc. 404 team has submitted vulnerability research to many well-known vendors such as Microsoft, Apple, Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the industry.
The most well-known sharing of Knownsec 404 Team includes: KCon Hacking Conference, Seebug Vulnerability Database and ZoomEye Cyberspace Search Engine.
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1010/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1010/
如有侵权请联系:admin#unsafe.sh