JS 思考题 —— 如何获取闭包内 key 变量的值:
// 挑战目标:获取 key 的值
(function() {
// 一个内部变量,外部无法获取
var key = Math.random()
console.log('[test] key:', key)
// 一个内部函数
function internal(x) {
return x
}
// 对外暴露的函数
apiX = function(x) {
try {
return internal(x)
} catch (err) {
return key
}
}
})()
// 你的代码写在此处:
// ...
咋一看,似乎无解。毕竟 internal 函数里啥也没做,连报错的机会都没有,所以 apiX 也不可能泄露 key 的值。
既然 internal 函数不可能报错,那么在调用这个函数时,是否会报错呢?
事实上 JS 中调用任何一个函数,都存在报错的可能。例如:
F1()
function F1() { F2() }
function F2() { F3() }
function F3() { F4() }
...
只要层次足够深,总会遇到一个函数 Fn 在调用 Fn+1 时报错。原因很简单,大量的调用消耗了栈空间,导致无法再往下调用。
因此,上述问题就有一种全新的解决思路:我们在调用接口前,先消耗大量栈空间,直到快饱和时再调接口,这样接口函数就没有足够的栈空间了,执行 internal() 就会抛出栈溢出错误,从而进入异常流程!
当然实现要比想象的简单。因为该接口没有限制调用次数,所以只需不断递归测试,即可获得我们想要的结果:
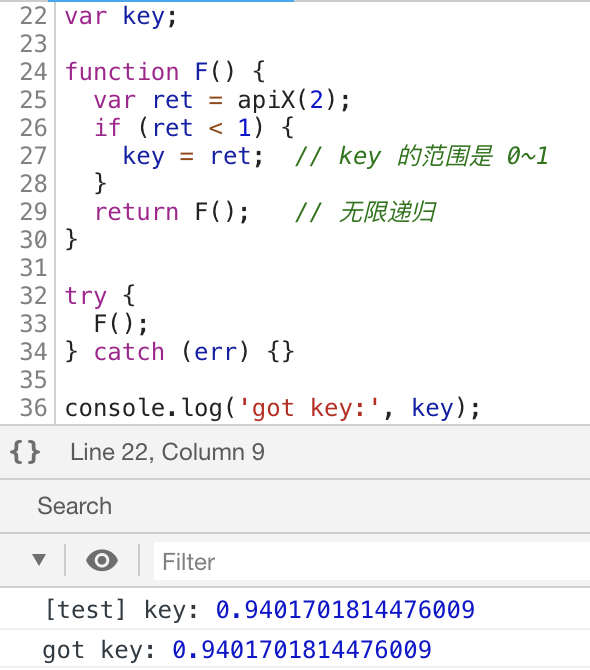
var key;
function F() {
var ret = apiX(2);
if (ret < 1) {
key = ret; // key 的范围是 0~1
}
return F(); // 无限递归
}
try {
F();
} catch (err) {}
console.log('got key:', key);
演示:https://www.etherdream.com/FunnyScript/stack-detect.html

这样,我们就拿到了闭包中 key 的值!
类似的思路,还可以用在其他场景,例如检测某个操作是否被 Proxy 拦截。
由于 Proxy 是透明的,常规手段很难检测其存在:
// 给 Math 对象套一层代理
self.Math = new Proxy(Math, {
get(obj, prop) {
return obj[prop];
}
});
Math.sin // ƒ sin() { [native code] }
'sin' in Math // true
Reflect.ownKeys(Math) // ["abs", "acos", ...]
...
但既然使用 Proxy,多少会对某些操作进行拦截。例如上述拦截了 get 操作,因此读取 Math 对象任何属性时,都会先经过该函数。
这意味着,每次属性读取都会触发一个 JS 函数,从而消耗额外的栈空间 —— 假如当前栈空间不足,那么回调函数就无法触发了!
而普通对象的属性读取,显然不会消耗栈空间,因此在栈空间不足的情况下也能正常读取。
根据这个思路,我们就可以实现 Proxy 的检测:
演示: https://jsfiddle.net/4jrytL6s/
优化
考虑到频繁读取 Proxy 可能会影响性能,因此放弃之前那种不断尝试的方法,而是先算出 JS 引擎的栈大小,然后通过递归对栈进行填充,直到快饱和再检测:
// 计算 JS 引擎栈大小
var max = 0;
function getStackMax() {
max++;
getStackMax();
}
try {
getStackMax();
} catch (err) {
}
console.log('max:', max);
// 填充栈
var num = 0;
function fill() {
if (++num === max - 1) {
// 快饱和状态
}
fill();
}
try {
fill();
} catch (err) {
}
使用这种方案,在 Chrome 浏览器下只需 4ms 左右。事实上还可以再优化,例如 Chrome 的 JS 引擎会把函数的局部变量也存放在栈上,例如:
var max = 0;
function F() {
max++;
var a0,a1,a2,a3,a4,a5,a6,a7,a8,a9;
return F();
}
try {
F();
} catch (err) {}
console.log('deep:', max);
当我们在函数中定义 10 个变量之后,最大调用深度从原先的 15656 层降到了 6958 层。由于减少了调用次数,执行时间也降低了近一半。
如果将变量继续增加到 100 个,那么最大深度只有 1159 层,而耗时又减少了一大半。
| 局部变量 | 最大调用层数 | 调用耗时(ms) |
|---|---|---|
| 0 | 15656 | 1.85 |
| 10 | 6958 | 0.76 |
| 100 | 1159 | 0.42 |
| 1000 | 124 | 0.71 |
(测试环境:Chrome/70 OSX/10.14 LPDDR3/2133MHz i7-7660U/2.50GHz)
演示:https://jsfiddle.net/pzhs1wg4/
不过不同的 JS 引擎细节都不一样,例如 Safari 的测试一次栈大小需耗费几十至上百 ms,而对于 FireFox,本文所有的案例甚至都无法得到正确结果,因为它的栈容量是不固定的!
如有侵权请联系:admin#unsafe.sh