2021-08-01 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:187 收藏
Published at 2021-08-01 | Last Update 2021-08-01
译者序
本文翻译自 2018 年 ACM CoNEXT 大会上的一篇文章:
The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel
作者阵容豪华,包括来自 Cilium 的 Daniel Borkmann、John Fastabend 等。
论文引用信息:
Toke Høiland-Jørgensen, Jesper Dangaard Brouer, Daniel Borkmann, John Fastabend, Tom Herbert, David Ahern, and David Miller. 2018. The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel. In CoNEXT ’18: International Conference on emerging Networking EXperiments and Technologies, December 4–7, 2018, Heraklion, Greece. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/3281411.3281443
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
近些年业界流行通过内核旁路(kernel bypass)的方式实现 可编程的包处理过程(programmable packet processing)。实现方式是 将网络硬件完全交由某个专门的用户空间应用(userspace application) 接管,从而避免内核和用户态上下文切换的昂贵性能开销。
内核收包时,硬中断(Interrupt)和软中断(SoftIRQ)相关的逻辑,见: (译) Linux 网络栈监控和调优:接收数据(2016)。 译注。
但是,操作系统被旁路(绕过)之后,它的应用隔离(application isolation) 和安全机制(security mechanisms)就都失效了;一起失效的还有各种经过已经 充分测试的配置、部署和管理工具。
为解决这个问题,我们提出一种新的可编程包处理方式:eXpress Data Path (XDP)。
- XDP 提供了一个仍然基于操作系统内核的安全执行环境,在设备驱动上下文 (device driver context)中执行,可用于定制各种包处理应用。
- XDP 是主线内核(mainline Linux kernel)的一部分,与现有的内核 网络栈(kernel’s networking stack)完全兼容,二者协同工作。
- XDP 应用(application)通过 C 等高层语言编写,然后编译成特定字节码;出于安 全考虑,内核会首先对这些字节码执行静态分析,然后再将它们翻译成 处理器原生指令(native instructions)。
- 测试结果显示,XDP 能达到 24Mpps/core 的处理性能。
为展示 XDP 灵活的编程模型,本文还将给出三个程序示例,
- layer-3 routing(三层路由转发)
- inline DDoS protection(DDoS 防护)
- layer-4 load balancing(四层负载均衡)
软件实现高性能包处理的场景,对每个包的处理耗时有着极高的要求。通用目的操作系统中 的网络栈更多是针对灵活性的优化,这意味着它们花在每个包上 的指令太多了,不适合网络高吞吐的场景。
因此,随后出现了一些专门用于包处理的软件开发工具,例如 Data Plane Development Kit (DPDK) [16]。这些工具一般都会完全绕过内核,将网络硬件直接交 给用户态的网络应用,并需要独占一个或多个 CPU。
1.1 现有方案(kernel bypass)存在的问题
内核旁路方式可以显著提升性能,但缺点也很明显:
- 很难与现有系统集成;
- 上层应用必须要将内核中已经非常成熟的模块在用户态重新实现一遍,例如路由表、高层协议栈等;
- 最坏的情况下,这种包处理应用只能工作在一个完全隔绝的环境,因为内核提供的常见工具和部署方式在这种情况下都不可用了。
- 导致系统越来越复杂,而且破坏了操作系统内核在把控的安全边界。 在基础设施逐渐迁移到 Kubernetes/Docker 等容器环境的背景下,这一点显得尤其严重, 因为在这种场景下,内核担负着资源抽象和隔离的重任。
1.2 新方案:给内核网络栈添加可编程能力
对此,本文提供了另一种解决方案:给内核网络栈添加可编程能力。这使得我们能在 兼容各种现有系统、复用已有网络基础设施的前提下,仍然实现高速包处理。 这个框架称为 XDP,
- XDP 定义了一个受限的执行环境(a limited execution environment),运行在一个 eBPF 指令虚拟机中。eBPF 是 BSD Packet Filter (BPF) [37] 的扩展。
- XDP 程序运行在内核上下文中,此时内核自身都还没有接触到包数据( before the kernel itself touches the packet data),这使得我们能在网卡收到包后 最早能处理包的位置,做一些自定义数据包处理(包括重定向)。
- 内核在加载(load)时执行静态校验,以确保用户提供的 XDP 程序的安全。
- 之后,程序会被动态编译成原生机器指令(native machine instructions),以获得高性能。
XDP 已经在过去的几个内核 release 中逐渐合并到内核,但在本文之前,还没有关于 XDP 系统的 完整架构介绍。本文将对 XDP 做一个高层介绍。
1.3 新方案(XDP)的优点
我们的测试结果显示 XDP 能取得 24Mpps/core 的处理性能,这虽然与 DPDK 还有差距,
但相比于后者这种 kernel bypass 的方式,XDP 有非常多的优势。
本文是 2018 年的测试结果,更新的一些性能(及场景)对比可参考 (译) 为容器时代设计的高级 eBPF 内核特性(FOSDEM, 2021)。 译注。
具体地,XDP:
-
与内核网络栈协同工作,将硬件的控制权完全留在内核范围内。带来的好处:
- 保持了内核的安全边界
- 无需对网络配置或管理工具做任何修改
-
无需任何特殊硬件特性,任何有 Linux 驱动的网卡都可以支持, 现有的驱动只需做一些修改,就能支持 XDP hooks。
-
可以选择性地复用内核网络栈中的现有功能,例如路由表或 TCP/IP 协议栈,在保持配置接口不变的前提下,加速关键性能路径(critical performance paths)。
-
保证 eBPF 指令集和 XDP 相关的编程接口(API)的稳定性。
-
与常规 socket 层交互时,没有从用户态将包重新注入内核的昂贵开销。
-
对应用透明。这创造了一些新的部署场景/方式,例如直接在应用所 在的服务器上部署 DoS 防御(而非中心式/网关式 DoS 防御)。
-
服务不中断的前提下动态重新编程(dynamically re-program), 这意味着可以按需加入或移除功能,而不会引起任何流量中断,也能动态响应系统其他部分的的变化。
-
无需预留专门的 CPU 做包处理,这意味着 CPU 功耗与流量高低直接相关,更节能。
1.4 本文组织结构
接下来的内容介绍 XDP 的设计,并做一些性能分析。结构组织如下:
- Section 2 介绍相关工作;
- Section 3 介绍 XDP 系统的设计;
- Section 4 做一些性能分析;
- Section 5 提供了几个真实 XDP 场景的程序例子;
- Section 6 讨论 XDP 的未来发展方向;
- Section 7 总结。
XDP 当然不是第一个支持可编程包处理的系统 —— 这一领域在过去几年发展势头良好, 并且趋势还在持续。业内已经有了几种可编程包处理框架,以及基于这些框架的新型应用,包括:
- 单一功能的应用,如 switching [47], routing [19], named-based forwarding [28], classification [48], caching [33] or traffic generation [14]。
- 更加通用、且高度可定制的包处理解决方案,能够处理从多种源收来的数据包 [12, 20, 31, 34, 40, 44]。
要基于通用(Common Off The Shelf,COTS)硬件实现高性能包处理,就必须解决 网卡(NIC)和包处理程序之间的所有瓶颈。由于性能瓶颈主要来源于内核和用户态应用之 间的接口(系统调用开销非常大,另外,内核功能丰富,但也非常复杂), 低层(low-level)框架必须通过这样或那样的方式来降低这些开销。
现有的一些框架通过几种不同的方式实现了高性能,XDP 构建在其中一些技术之上。 接下来对 XDP 和它们的异同做一些比较分析。
2.1 用户态轮询 vs. XDP
- DPDK [16] 可能是使用最广泛的高性能包处理框架。它最初只支持 Intel 网卡,后来逐 步扩展到其他厂商的网卡。DPDK 也称作内核旁路框架(kernel bypass framework), 因为它将网络硬件的控制权从内核转移到了用户态的网络应用,完全避免了内核-用户态 之间的切换开销。
- 与 DPDK 类似的还有 PF_RING ZC module [45] 和 hardware-specific Solarflare OpenOnload [24]。
在现有的所有框架中,内核旁路方式性能是最高的 [18];但如引言中指 出,这种方式在管理、维护和安全方面都存在不足。
XDP 采用了一种与内核旁路截然相反的方式:相比于将网络硬件的控制权上移到用户空间, XDP 将性能攸关的包处理操作直接放在内核中,在操作系统的网络栈之前执行。
- 这种方式同样避免了内核-用户态切换开销(所有操作都在内核),
-
但仍然由内核来管理硬件,因此保留了操作系统提供的管理接口和安全防护能力。
这里的主要创新是:使用了一个虚拟执行环境,它能对加载的 程序进行校验,确保它们不会对内核造成破坏。
2.2 内核模块 vs. XDP
在 XDP 之前,以内核模块(kernel module)方式实现包处理功能代价非常高, 因为程序执行出错时可能会导致整个系统崩溃,而且内核的内部 API 也会随着时间发生变化。 因此也就不难理解为什么只有很少的系统采用了这种方式。其中做的比较好包括
- 虚拟交换机 Open vSwitch [44]
- Click [40]
- 虚拟机路由器 Contrail [41]
这几个系统都支持灵活的配置,适用于多种场景,取得比较小的平摊代价。
XDP 通过:
-
提供一个安全的执行环境,以及内核社区支持,提供与那些暴露到用户空间一样稳定的内核 API
极大地降低了那些将处理过程下沉到内核的应用(applications of moving processing into the kernel)的成本。
-
此外,XDP 程序也能够完全绕过内核网络栈(completely bypass), 与在内核网络栈中做 hook 的传统内核模块相比,性能也更高。
-
XDP 除了能将处理过程下沉到内核以获得最高性能之外,还支持在程序中执行重定向 (redirection)操作,完全绕过内核网络栈,将包送到特殊类型的用户空间 socket; 甚至能工作在 zero-copy 模式,进一步降低开销。
- 这种模式与 Netmap [46] 和 PF_RING [11] 方式类似,但后者是在没有完全绕过内 核的情况下,通过降低从网络设备到用户态应用(network device to userspace application)之间的传输开销,实现高性能包处理。
内核模块方式的另一个例子是 Packet I/O engine,这是 PacketShader [19] 的组成部分, 后者专用于 Arrakis [43] and ClickOS [36] 之类的特殊目的操作系统。
2.3 可编程硬件 vs. XDP
可编程硬件设备也是一种实现高性能包处理的方式。
- 一个例子是 NetFPGA [32],通过对它暴露的 API 进行编程,能够在这种基于 FPGA 的专 用设备上运行任何包处理任务。
- P4 编程语言 [7] 致力于将这种可编程能力扩展到更广泛的包处理硬件上 (巧合的是,它还包括了一个 XDP backend [51])。
某种意义上来说,XDP 可以认为是一种 offload 方式:
- 性能敏感的处理逻辑下放到网卡驱动中,以提升性能;
- 其他的处理逻辑仍然走内核网络栈;
- 如果没有用到内核 helper 函数,那整个 XDP 程序都可以 offload 到网卡(目前 Netronome smart-NICs [27] 已经支持)。
2.4 小结
XDP 提供了一种高性能包处理方式,与已有方式相比,在性能、与现有系统的集成、灵活性 等方面取得了更好的平衡。
接下来介绍 XDP 是如何取得这种平衡的。
XDP 的设计理念:
- 高性能包处理,
- 集成到操作系统内核(kernel)并与之协同工作,同时,
- 确保系统其它部分的安全性(safety)和完整性(integrity)
这种与内核的深度集成显然会给设计带来一些限制,在 XDP 组件合并到 Linux 的过程中,我们也收到了许多来自社区的反馈,促使我们不断调整 XDP 的设计,但 这些设计反思不在本文讨论范围之内。
3.0 XDP 系统架构
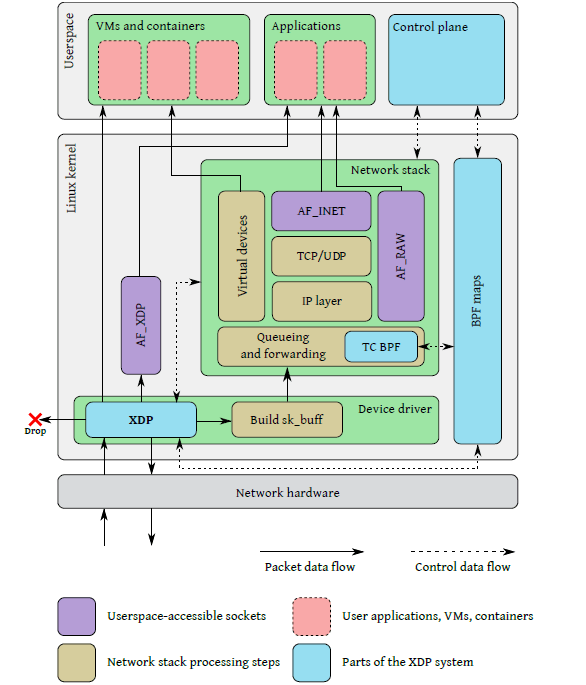
图 1 描绘了整个 XDP 系统,四个主要组成部分:
- XDP driver hook:XDP 程序的主入口,在网卡收到包执行。
- eBPF virtual machine:执行 XDP 程序的字节码,以及对字节码执行 JIT 以提升性能。
- BPF maps:内核中的 key/value 存储,作为图中各系统的主要通信通道。
- eBPF verifier:加载程序时对其执行静态验证,以确保它们不会导致内核崩溃。
Fig 1. XDP 与 Linux 网络栈的集成。这里只画了 ingress 路径,以免图过于复杂。
上图是 ingress 流程。网卡收到包之后,在处理包数据(packet data)之前,会先执行 main XDP hook 中的 eBPF 程序。 这段程序可以选择:
- 丢弃(drop)这个包;或者
- 通过当前网卡将包再发送(send)出去;或者
- 将包重定向(redirect)到其他网络接口(包括虚拟机的虚拟网卡),或者通过 AF_XDP socket 重定向到用户空间;或者
-
放行(allow)这个包,如果后面没有其他原因导致的 drop,这个包就会进入常规的内核网络栈。
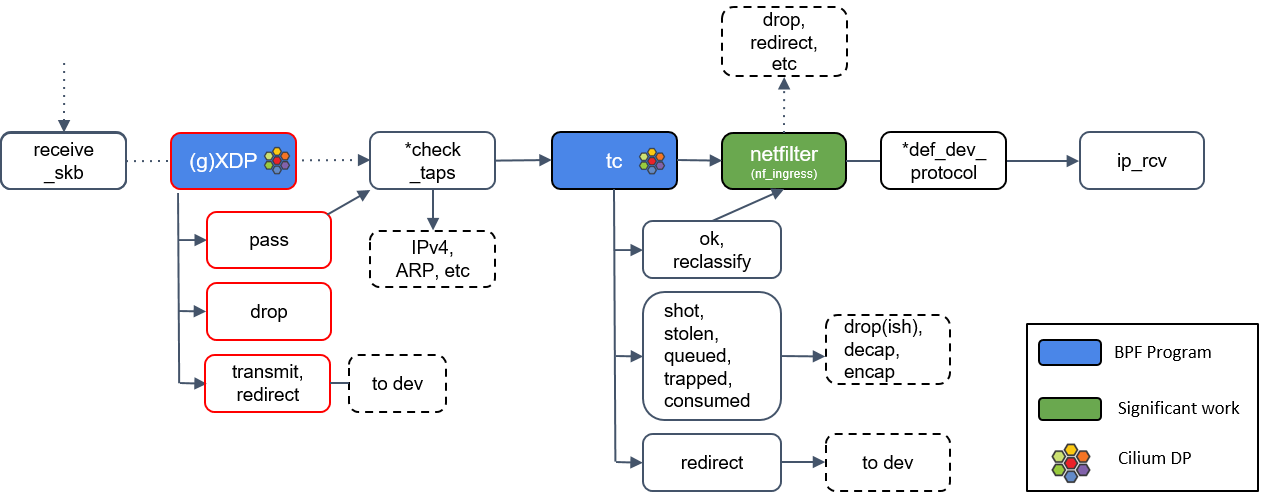
如果是这种情况,也就是放行包进入内核网络栈,那接下来在将包放到发送队列之前(before packets are queued for transmission), 还有一个能执行 BPF 程序的地方:TC BPF hook。
更多信息,可参考 (译) [论文] 迈向完全可编程 tc 分类器(cls_bpf)(NetdevConf,2016)。 译注。
此外,图 1 中还可以看出,不同的 eBPF 程序之间、eBPF 程序和用户空间应用之间,都能够通过 BPF maps 进行通信。
3.1 XDP driver hook
在设备驱动中执行,无需上下文切换
XDP 程序在网络设备驱动中执行,网络设备每收到一个包,程序就执行一次。
相关代码实现为一个内核库函数(library function),因此程序直接 在设备驱动中执行,无需切换到用户空间上下文。
在软件最早能处理包的位置执行,性能最优
回到上面图 1 可以看到:程序在网卡收到包之后最早能处理包的位置
执行 —— 此时内核还没有为包分配 struct sk_buff 结构体,
也没有执行任何解析包的操作。
XDP 程序典型执行流
下图是一个典型的 XDP 程序执行流:
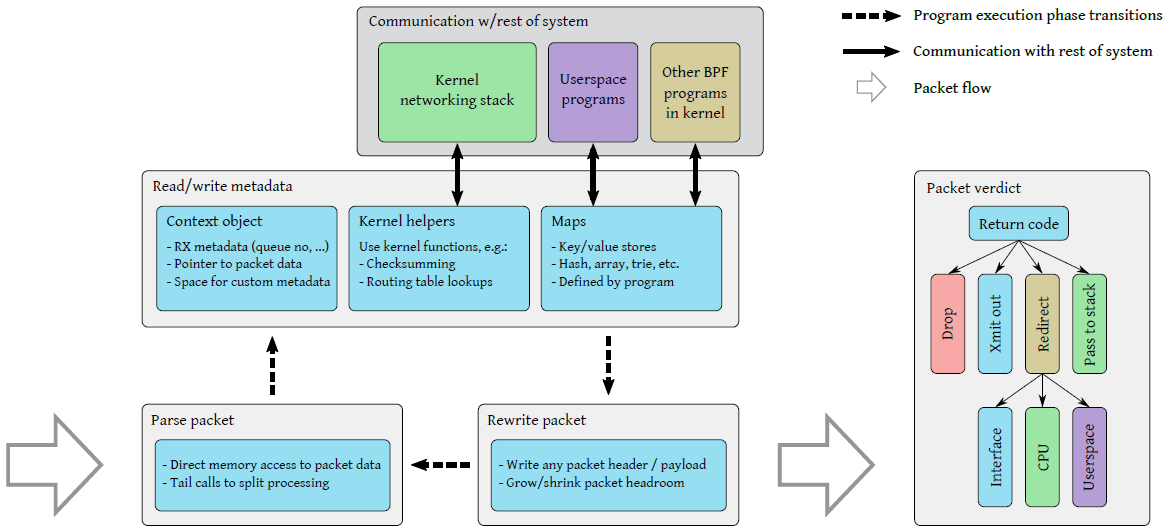
Fig 2. 典型 XDP 程序的执行流。
网卡收到一个包时,XDP 程序依次执行:
-
提取包头中的信息(例如 IP、MAC、Port、Proto 等),
执行到程序时,系统会传递给它一个上下文对象(context object)作为参赛 (即
struct xdp_md *ctx,后面有例子),其中包括了指向原 始包数据的指针,以及描述这个包是从哪个网卡的哪个接口接收上来的等元数据字段。 -
读取或更新一些资源的元信息(例如更新统计信息);
解析包数据之后,XDP 程序可以读取
ctx中的包元数据(packet metadata) 字段,例如从哪个网卡的哪个接口收上来的(ifindex)。除此之外,ctx对象还允许 程序访问与包数据毗邻的一块特殊内存区域(cb, control buffer), 在包穿越整个系统的过程中,可以将自定义的数据塞在这里。除了 per-packet metadata,XDP 程序还可以通过 BPF map 定义和访问自己的持久数据 ,以及通过各种 helper 函数访问内核基础设施。
- BPF map 使 BPF 程序能与系统的其他部分之间通信;
- Helpers 使 BPF 程序能利用到某些已有的内核功能(例如路由表), 而无需穿越整个内核网络栈。
-
如果有需要,对这个包进行 rewrite header 操作,
程序能修改包数据的任何部分,包括添加或删除包头。这使得 XDP 程序能执行封装/接封装操作,以及重写(rewrite)地址字段然后转发等操作。
内核 helper 函数各有不同用途,例如修改一个包之后,计算新的校验和(checksum)。
-
进行最后的判决(verdict),确定接下来对这个包执行什么操作;
判决结果包括:
- 三种简单返回码:丢弃这个包、通过接收时的网卡将包重新发送出去、允许这个包进入内核网络栈;
- 第四种返回码 redirect:允许 XDP 程序指定网卡、CPU、用户态 socket 等,将包重定向过去。
重定向功能的用途:
- 将原始包通过另一个网卡(包括虚拟机的虚拟网卡)发送出去;
- 转发给指定 CPU 做进一步处理;
- 转发给 AF_XDP 类型的 socket 做进一步处理;
这些不同的路径,在图 1 对应的是几条实线。
将重定向判决(verdict)与重定向目标(target)分开,使得重定向目标类型很容易扩展; 另外,由于重定向参数(目标)是通过 BPF map 查询的,因此无需修 改 XDP 程序,就能动态修改重定向目标。
程序还能通过尾调用(tail call),将控制权交给另一个 XDP 程序; 通过这种方式,可以将一个大程序拆分成几个逻辑上的小程序(例如,根据 IPv4/IPv6)。
由于 XDP 程序可包含任意指令,因此前三步(读取包数据、处理元数据、重写包数据) 顺序可以是任意的,而且支持多层嵌套。 但实际中为了获得高性能,大部分情况下还是将执行结构组织成这顺序的三步。
3.2 eBPF 虚拟机
XDP 程序在 Extended BPF (eBPF) 虚拟机中执行。 eBPF 是早期 BSD packet filter (BPF) [37] 的扩展,后者在过去的几十年中广泛 应用于各种包处理工具。
BPF 使用 基于寄存器的(register-based) virtual machine 来描述 过滤动作(filtering actions)。
(其他几段,略)。
这一小节的内容有些已经过滤,限于篇幅,描述也并不全面。
更多关于 eBPF 虚拟机和指令架构的内容,可参考: (译) Cilium:BPF 和 XDP 参考指南(2021) 译注。
eBPF 虚拟机支持动态加载(loading)和重加载(re-loading)程序,内核管理所有 BPF 程序的生命周期。
3.3 BPF maps
eBPF 程序在触发内核事件时执行(例如,触发 XDP 程序执行的,是收包事件)。 程序每次执行时,初始状态都是相同的(即程序是无状态的),它们无法直接访问 内核中的持久存储(BPF map)。为此,内核提供了访问 BPF map 的 helper 函数。
BPF map 是 key/value 存储,在加载 eBPF 程序时定义(defined upon loading an eBPF program)。
BPF map 的类型和一些细节实现,可参考:
译注。
用途:
- 持久存储。例如一个 eBPF 程序每次执行时,都会从里面获取上一次的状态。
- 用于协调两个或多个 eBPF 程序。例如一个往里面写数据,一个从里面读数据。
- 用于用户态程序和内核 eBPF 程序之间的通信。
3.4 eBPF verifier
唯一加载入口:bpf() 系统调用
由于 eBPF 代码直接运行在内核地址空间,因此它能直接访问 —— 也可
能是破坏 —— 任何内存。为防止这种情况发生,内核规定只能通过唯一入口(
bpf() 系统调用)加载 BPF 程序。
加载 BPF 程序时,位于内核中的校验器首先会对字节码程序进行静态分析,以确保
- 程序中没有任何不安全的操作(例如访问任意内存),
-
程序会终止(terminate)。通过下面这两点来实现:
- 禁止循环操作
- 限制程序最大指令数
校验器工作原理:two-pass DAG
校验器的工作原理:首先根据程序的控制流构建一个有向无环图(DAG), 然后对 DAG 执行如下校验:
-
首先,对 DAG 进行一次深度优先搜索(depth-first search),以 确保它是无环的(acyclic),例如,没有循环,也不包含不支持或无法执行到的指令。
-
然后,再扫描一遍,这次会遍历 DAG 的所有可能路径。这次扫描的目的是:
- 确保程序的内存访问都是安全的,
- 调用 helper 函数时传的参数类型是对的。
程序执行
load或call指令时,如果参数不合法,就会在这里被拒绝。参数合法 性是通过在程序执行期间跟踪所有寄存器和栈变量的状态(states of registers and stack variables)来实现的。
内存越界和空指针检查:职责上移到程序自身/开发者
这种跟踪寄存器状态的机制是为了在无法预知内存边界的情况下,仍然确保程序 的内存访问不会越界。无法预知内存边界是因为:
- 包的大小是不固定的;
- map 的内容也无法提前预知,因此也无法判断一次 map 查找操作是否会成功。
为解决这个问题,校验器会检查已加载的程序自身是否会做如下检查:
- 解引用指针前做了内存边界检查,
- 查询 map 之前是检查了 map 指针是否为空。
这种方式将处理逻辑中的安全检查和遇到错误时如何处理的控制权都 交给了 BPF 程序的编写者。
跟踪数据访问操作和值范围
为跟踪数据访问,校验器会跟踪
- 数据类型
- 指针偏置(pointer offsets)
- 所有寄存器的可能值范围
程序开始时,
- R1 寄存器中存储的是指向 context metadata 的指针(
struct xdp_md *ctx), - R10 是栈指针(stack pointer),
- 其他所有寄存器都是未初始化状态。
接下来程序每执行一步,寄存器状态就会更新一次。当寄存器中存入一个新值时,这个寄存器 还会继承与这个值相关的状态变量(inherits the state variables from the source of the value)。
算术操作会影响标量类型的值的范围(value ranges of scalar types),以及指针类型的 offset。
可能的最大范围(max possible range)存储在状态变量中,例如往寄存器中 load 一个字节时,
这个寄存器的可能值范围就设置为 0~255。指令图(instruction graph)中的
各逻辑分支就会根据操作结果更新寄存器状态。例如,比较操作 R1 > 10,
- 校验器在一个分支
if R1 > 10中会将 R1 最小值设为 11, - 在另一个
else分支中将其最大值设为 10。
不同类型数据的校验信息来源(source of truth)
利用状态变量中存储的范围信息,校验器就能预测每个 load 指令能访问的所有 内存范围,确保它执行的都是合法内存访问。
- 对于包数据(packet data)的访问,会与 context 对象中的
data_end变量做比较; - 对于 BPF map 中获取的值,或用到 map 定义中声明的 data size 信息;
- 对于栈上存储的值,会检查状态变量中记录的值范围;
- 对于指针算术操作(pointer arithmetic)还会施加额外的限制,指针通常不能被转换成整形值。
只要校验器无法证明某个操作是安全,该 BPF 程序在加载时(load time)就会被拒绝。 除此之外,校验器还会利用范围信息确保内存的对齐访问(enforce aligned memory access)。
校验器的目的
需要说明的是,校验器的目的是避免将内核内部(the internals of the kernel )暴露给恶意或有缺陷的 eBPF 程序,而非确保程序中函数的实现已经是最高效的。
换句话说,如果 XDP 程序中处理逻辑过多,也可能会导致机器变慢 ;如果代码写的有问题,也可能会破坏包数据。出于这些原因,加载 BPF 程序需要 管理员权限(root)。避免这些 bug 的责任在程序员,但选择将哪些程序加载 到系统的权限在管理员。
3.5 XDP 程序示例
下面是一个简单的 XDP 程序,展示了前面介绍的一些特性。 程序会解析包数据,判断如果是 UDP 包,直接交换源和目的 MAC 地址,然后将包从相同网卡再发送回去,
虽然这是一个非常简单的例子,但真实世界中的 XDP 程序用到的组件和特性,这里基本都具备了。
// 从内核 BPF 代码示例 xdp2_kern.c 修改而来。
1 // 用于统计包数
2 struct bpf_map_def SEC("maps") rxcnt = {
3 .type = BPF_MAP_TYPE_PERCPU_ARRAY,
4 .key_size = sizeof(u32), // IP 协议类型,即 IPv4/IPv6
5 .value_size = sizeof(long), // 包数
6 .max_entries = 256,
7 };
8
9 // 直接操作包数据(direct packet data access),交换 MAC 地址
10 static void swap_src_dst_mac(void *data)
11 {
12 unsigned short *p = data;
13 unsigned short dst[3];
14 dst[0] = p[0]; dst[1] = p[1]; dst[2] = p[2];
15 p[0] = p[3]; p[1] = p[4]; p[2] = p[5];
16 p[3] = dst[0]; p[4] = dst[1]; p[5] = dst[2];
17 }
18
19 static int parse_ipv4(void *data, u64 nh_off, void *data_end)
20 {
21 struct iphdr *iph = data + nh_off;
22 if (iph + 1 > data_end)
23 return 0;
24 return iph->protocol;
25 }
26
27 SEC("xdp1") // marks main eBPF program entry point
28 int xdp_prog1(struct xdp_md *ctx)
29 {
30 void *data_end = (void *)(long)ctx->data_end;
31 void *data = (void *)(long)ctx->data;
32 struct ethhdr *eth = data; int rc = XDP_DROP;
33 long *value; u16 h_proto; u64 nh_off; u32 ipproto;
34
35 nh_off = sizeof(*eth);
36 if (data + nh_off > data_end)
37 return rc;
38
39 h_proto = eth->h_proto;
40
41 /* check VLAN tag; could be repeated to support double-tagged VLAN */
42 if (h_proto == htons(ETH_P_8021Q) || h_proto == htons(ETH_P_8021AD)) {
43 struct vlan_hdr *vhdr;
44
45 vhdr = data + nh_off;
46 nh_off += sizeof(struct vlan_hdr);
47 if (data + nh_off > data_end)
48 return rc;
49 h_proto = vhdr->h_vlan_encapsulated_proto;
50 }
51
52 if (h_proto == htons(ETH_P_IP))
53 ipproto = parse_ipv4(data, nh_off, data_end);
54 else if (h_proto == htons(ETH_P_IPV6))
55 ipproto = parse_ipv6(data, nh_off, data_end);
56 else
57 ipproto = 0;
58
59 /* lookup map element for ip protocol, used for packet counter */
60 value = bpf_map_lookup_elem(&rxcnt, &ipproto);
61 if (value)
62 *value += 1;
63
64 /* swap MAC addrs for UDP packets, transmit out this interface */
65 if (ipproto == IPPROTO_UDP) {
66 swap_src_dst_mac(data);
67 rc = XDP_TX;
68 }
69 return rc;
70 }
具体地:
- 定义了一个 BPF map 存储统计信息。用户态程序可以 poll 这个 map 来获取统计信息。
- context 对象
struct xdp_md *ctx中有包数据的 start/end 指针,可用于直接访问包数据。 - 将数据指针和
data_end比较,确保内存访问不会越界。 - 程序必须自己解析包,包括 VLAN headers 等东西。
- 直接通过指针(direct packet data access)修改包头。
- 内核提供的 map lookup helper。这是程序中唯一的真实函数调用;其他函数都是内联,包括
htons()。 - 最终针对这个包的判决通过程序返回值传递给调用方。
将这段程序安装到网卡接口上时,它首先会被编译成 eBPF 字节码,然后经受校验器检查。 这里的检查项包括:
- 无循环操作;程序大小(指令数量);
- 访问包数据之前,做了内存边界检查;
- 传递给 map lookup 函数的参数,类型与 map 定义相匹配;
- map lookup 的返回值(value 的内存地址)在使用之前,检查了是否为 NULL。
3.6 小结
XDP 系统由四个主要部分组成:
- XDP device driver hook:网卡收到包之后直接运行;
- eBPF 虚拟机:执行 XDP 程序(以及内核其他模块加载的 BPF 程序);
- BPF maps:使不同 BPF 程序之间、BPF 程序与用户空间应用之间能够通信;
- eBPF verifier:确保程序不包含任何可能会破坏内核的操作。
这四部分加在一起,创造了一个编写自定义包处理应用的强大环境,它能加速包处理的关键 路径,同时还与内核及现有基础设施密切集成。
接下来看一下 XDP 应用的性能。
DPDK 是目前性能最高的包处理框架 [18],因此本文将 XDP 与 DPDK 及 Linux 内核网络 栈的性能做一个对比。测试机器环境:
- CPU:一块 hexa-core Intel Xeon E5-1650 v4 CPU running at 3.60GHz, 支持 Intel Data Direct I/O (DDIO) 技术,网络硬件通过 DMA 能直接将包放到 CPU 缓存。
- 关闭超线性(Hyperthreading)。
- 网卡:两块 Mellanox ConnectX-5 Ex VPI dual-port 100Gbps,mlx5 驱动。
- 内核:Linux 4.18
- 使用基于 DPDK 的 TRex packet generator [9] 生成测试流量。所有测试脚本位于 [22]。
在测试中,我们主要关心三个 metric:
-
直接弃包(packet drop)性能。
为展示最高的包处理性能,我们将用最简单的操作 —— 丢弃接收到的包 —— 来测试。 这个测试能有效测量系统的整体开销,也是真正的包处理应用能达到的性能上限。
-
CPU 使用量。
如引言中指出,XDP 的优点之一是 CPU 使用量与流量大小是正相关的,而无需预留专 门的 CPU 给它用。我们通过测量 CPU 利用率随网络负载的变化来量化这个指标。
-
包转发性能。
转发的复杂性要更高一些,例如,涉及到与多块网卡的交互、重写二层头等等。 这里会将转发延迟也考虑进去。
我们已经验证,使用 MTU(1500 字节)包时,我们的系统单核就能达到线速(100 Gbps), 而且 CPU 有 50% 是空闲的。显然,真正的挑战在于 PPS,而非带宽,其他一些测试也已经指出了这一点 [46]。 出于这个原因,我们用最小包(64 字节)测试,衡量指标是 PPS。
对于 XDP 和 Linux 内核网络栈的测试,由于它们没有显式指定某些 CPU 来处理网络包的方式,因此我们通过配置硬件 RSS(Receive Side Scaling)来讲流量定向到指定 CPU。
对网卡、内核的一些配置调优,见代码仓库 [22]。
4.1 直接弃包(packet drop)性能
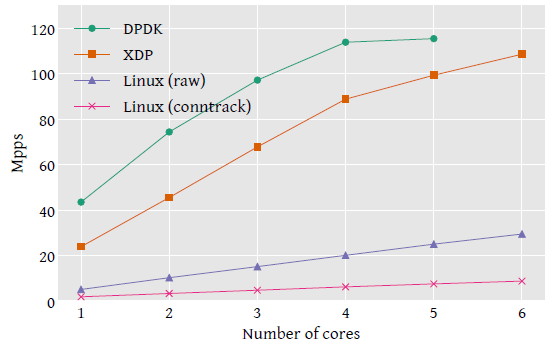
Fig 3. 直接弃包(packet drop)性能。DPDK 需要预留一个 CPU 运行控制任务,因此只剩下 5 个 CPU 做包处理。
上图是性能与 CPU 数量的关系。
- XDP 基准性能是
24Mpps/core,DPDK 是43.5Mpps/core。 - 二者在分别达到各自的峰值之前,PPS 都是随 CPU 数量线性增长的。
- 最终全局性能受限于 PCI 总线,启用 PCI descriptor compression(在 CPU cycles 和 PCI 总线带宽之间取舍)之后,能达到 115Mpps。
再看图中 Linux 网络栈在两种配置下的性能:
- 通过 iptables 的 raw table 丢弃流量,这是 Linux 网络栈中最早能丢弃包的地方;
- 通过 conntrack(连接跟踪)模块,这个模块的开销非常大,但在很多 Linux 发行版中都是默认开启的。
conntrack 模式达到了 1.8Mpps/core,raw 模式是 4.8Mpps/core ;这两种模式均未达到硬件瓶颈。 最终的性能,XDP 比常规网络栈的最快方式快了 5 倍。
Linux raw mode test 中,我们还测量了 XDP 程序不丢弃包,而是更新包数统计然后将包 送到内核网络栈的场景。 这种情况下,XDP 单核的处理性能会下降到 4.5Mpps/core,有 13.3ns 处理延迟。 图中并未给出这个测试结果,因为这个开销太小了。
4.2 CPU Usage
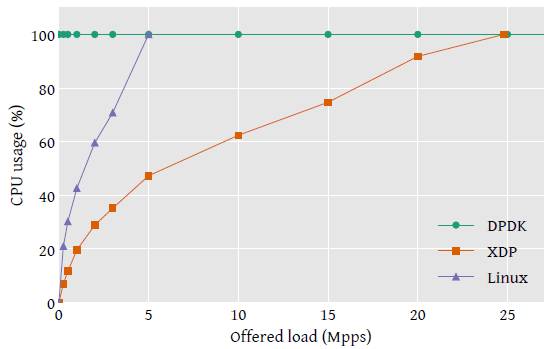
Fig 4. 直接弃包(packet drop)场景下的 CPU 利用率。
用系统提供的 mpstat 命令测量 CPU 利用率。结果如图 4 。
- DPDK 是 busy poll 模式,因此 CPU 永远是 100%。
-
XDP 和 Linux 内核网络栈都是随流量平滑增长:前面一小段是非线性的,后面基本是线性的。
前面非线性主要是硬中断带来的固定开销,在流量很小时这一部分占比较大。
4.3 包转发性能
这个测试中,转发应用执行非常简单的 MAC 地址重写:直接交换源和目的 MAC 地址,然后转发。 这是转发场景下最精简的步骤了,因此结果代表了所有真实转发应用的性能上限。
- 图中包括了同网卡转发和不同网卡转发(XDP 程序返回码不同)的结果。
- DPDK 示例程序只支持通过另一个网卡转发,因此这里只列出了这种情况下的性能。
- Linux 网络栈不支持这种极简转发模式(minimal forwarding mode),需要设置完整的 桥接或路由查找(bridging or routing lookup)才能转发包;路由查找是非常耗时的 ,由于其他几种应用并没有这一步,因此结果直接对比是没意义的。因此这里略去了 Linux 网络栈的结果。
转发吞吐(pps)
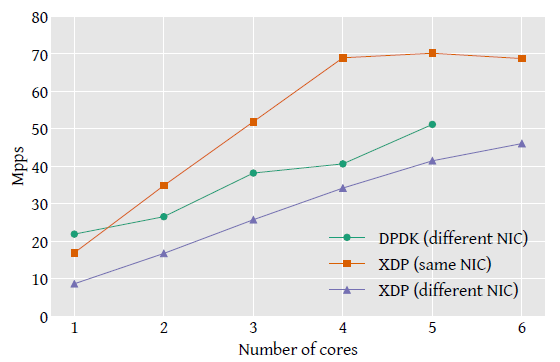
Fig 5. 转发性能。在同一网卡接口上收发会占用同一 PCI port 的带宽, 这意味着在 70Mpps XDP same-nic 组就已经达到了 PCI 总线的瓶颈
如图 5 所示,性能随 CPU 数量线性扩展,直到达到全局性能瓶颈。 XDP 在同网卡转发的性能远高于 DPDK 异网卡性能,原因是内存处理方式不同:
- packet buffer 是设备驱动分配的,与接收接口(receiving interface)相关联。
- 因此,异网卡场景下,当包转发到另一个接口时,memory buffer 需要还给与之关联的接口。
转发延迟
表 1. 转发延迟。机器网卡的两个接口直连,在转发速率分别为 100pps 和 1Mpps 的条件下,持续 50s 测量端到端延迟
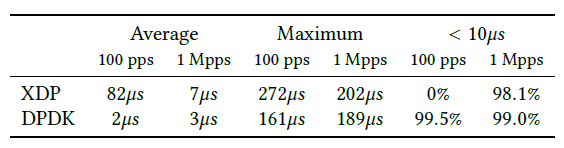
高 pps 场景下,XDP 的延迟已经接近 DPDK。但在低 pps 场景下,XDP 延迟比 DPDK 大的多,原因是 XDP 是基于中断的,中断处理时间( interrupt processing time)此时占大头;而 DPDK 是轮询模式,延迟相对比较固定。
4.4 讨论:XDP 性能与 DPDK 还有差距的原因
XDP 未做底层代码优化
上一节已经看到,XDP 相比于常规 Linux 网络栈性能有了显著提升。但对于大部分 XDP 场景来说,性能还是与 DPDK 有差距。我们认为,这是主要是因为 DPDK 做了相当多的底层 代码优化。举个例子来解释,考虑 packet drop 例子:
- XDP 24Mpps/core,对应
41.6ns/packet - DPDK 43.5Mpps,对应
22.9ns/packet
多出来的 18.7ns 在我们的 3.6GHz 机器上对应 67 个时钟周期。因此,很显然
每个很小的优化在这里都会产生很大的影响。例如,我们测量出在测试
机器上,每次函数调用需要 1.3ns。 mlx5 驱动处理每个包都有 10 次
函数调用,总计就是 13ns。
通用目的操作系统,首要目标:更好的扩展和配置,而非极致性能
另外,在 Linux 这样的通用目的操作系统中,某些开销是不可避免的, 因为设备驱动或子系统的组织方式是为了实现更好的扩展和配置,而非极致性能。
但是,我们认为有些优化还是有必要的。例如,我们尝试将内核中与测试网卡无关的 DMA 函数调用删掉,
这样将前面提到的 10 个函数调用降低到了 6 个,测试结果显示这将单核性能提升到了 29Mpps/core。
依此推测的话,将另外 6 个函数调用也优化掉,能将 XDP 的性能提升到 37.6Mpps。
实际上我们不可能将 6 个全部去掉,但去掉其中几个,再加上一些其他优化,我
们相信 XDP 和 DPDK 的性能差距将越来越小。
其他驱动的测试结果也是类似的,例如 i40e driver for 40 Gbps Intel cards。
基于以上讨论,我们相信未来 XDP 与 DPDK 的性能差距将越来越小。
另一方面,考虑到 XDP 在灵活性和与内核集成方面的优势, XDP 已经是很多实际场景中的非常有竞争力的方式。下文给出几个例子。
本节给出三个例子来具体展示 XDP 在真实世界中的应用。 这几个案例都是已经真实在用的,但本文出于解释目的,将使用简化的版本。 同时也建议读者参考 [38],后者是独立的文章,介绍使用 XDP 解决实际工作中网络服务所面临的一些挑战。
本节目的是展示真实 XDP 方案的可行性,因此不会将重点放在与业界最新的实现做详尽性能对比上。 我们会拿常规的 Linux 内核网络栈的性能作为 baseline,来对比 XDP 应用的性能。
5.1 案例一:软件路由(software routing)
内核数据平面 & 控制平面(BIRD/FRR)
Linux 内核实现了一个功能完整的路由表,作为数据平面,支持
- policy routing
- source-specific routing
- multipath load balancing, and more.
对于控制平面,Bird [10] 或 FRR [17] 这样的路由守护进程( routing daemons)实现了多种路由控制平面协议。Linux 提供的这套生态系统功能如此丰富 ,因此再在另一个包处理框架中重新实现一套类似的路由栈代价将非常高, 更实际的方式是对 Linux 内核的数据平面进行优化。
XDP:直接查询内核路由表并转发
XDP 非常适合做这件事情,尤其是它提供了一个 helper 函数,能从 XDP 程序中直接查询内核路由表。
- 如果查询成功,会返回 egress interface 和下一跳 MAC 地址, XDP 程序利用这些信息足够将包立即转发出去。
- 如果下一跳 MAC 还是未知的(因为之前还没进行过 neighbour lookup),XDP 程序就 能将包传给内核网络栈,后者会解析 neighbor 地址,这样随后的包 就能直接被 XDP 程序转发了。
测试:XDP routing + 全球 BGP 路由表
为展示 XDP 路由的性能,我们用 Linux 内核代码中的 XDP routing 例子 [1],与常规 Linux 内核网络栈的性能做对比。 两组测试:
- 路由表中只有一条路由;
-
路由表中有从 routeviews.org 中 dump 而来的全球 BGP 路由表(global BGP routing table)。 包含 752,138 条路由。随机生成 4000 个目的 IP 地址,以确保能充分利用到这种路由表。
如果目的 IP 地址少于 4000 个,实际用到的路由表部分会较小,能够保存在 CPU 缓存中,使得结果不准确。 增大 IP 数量至 4000 个以上,不会对转发性能造成影响,但可以避免缓存导致的结果不准问题。
对于两组测试,下一跳 MAC 地址都是与我们的发送网卡直接相关的接口的地址。
性能:2.5x
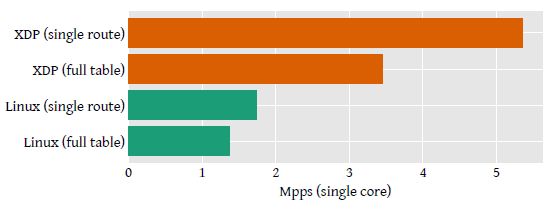
Fig 6. 软件路由的性能。由于性能随核数线性增加,这里只给出单核的结果。
测试结果如上图所示。
- full table lookup 性能提升了 2.5 倍;
- smaller routing table 组,提升了 3 倍。
这说明,XDP 路由程序 + 单核 + 10Gbps 网卡 的软硬件配置,就能 处理整张全球 BGP 路由表(保守估计每个包平均 300 字节)。
5.2 案例二:Inline DoS Mitigation
DoS 攻击还是像瘟疫一样纠缠着互联网,现在通常的方式是:通过已经入侵的大量设备发起分布式(DDoS)攻击。
有了 XDP 之后,我们能直接在应用服务器(application servers)上 部署包过滤程序来防御此类攻击(inline DoS mitigation), 无需修改应用代码。如果应用是部署在虚拟机里,那 XDP 程序还可以 部署在宿主机(hypervisor)上,这样单个程序就能保护机器上所有的虚拟机。
模拟 Cloudflare 防御架构
为展示工作原理,我们用 XDP 作为过滤机制,模拟 Cloudflare 的 DDoS 防御架构 [6]。 他们的 Gatebot architecture ,首先在各 PoP 点机器上采样,然后统一收起来做分析, 根据分析结果生成防御规则。
防御规则的形式是对包数据(payload)进行一系列简单检查, 能直接编译成 eBPF 代码然后分发到 PoP 点的所有服务器上。这里说的代码是 XDP 程序 ,它会将匹配到规则的所有流量丢弃,同时将统计信息更新到 BPF map。
程序逻辑
为验证这种方案的性能,我们编写一个 XDP 程序,它
- 解析包头,执行一些简单验证。对每个包:执行四次读取操作,以解析外层包头。
- 将符合攻击特性的流量丢弃。具体:丢弃 UDP + 特定端口的流量。
- 将其他流量通过 CPU redirect 方式重定向给另一个 CPU 做进一步处理;
性能
我们用 netperf 做性能压测 [26]。
-
用 netperf TCP round-trip benchmark,单个 TCP 连接来回小的 request/reply,统计 transactions/second。
模拟的是交互式应用,例如小的远程过程调用(RPC)。
-
实验在单核上进行,模拟多个流量(正常流量+攻击流量)竞争同一物理资源的场景。
-
在 beseline 35K 业务 TPS(transactions per second)基础上,打少量 UDP 流量作为攻击流量。逐渐加大攻击流量,观察 TPS 的变化。
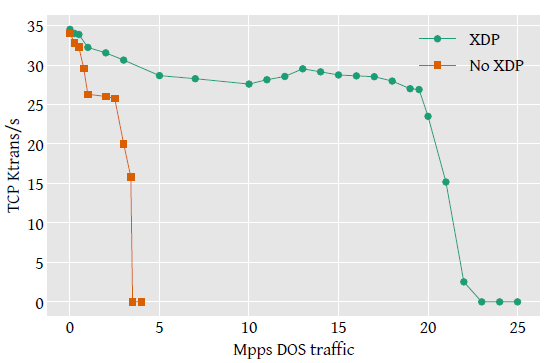
Fig 7. DDoS 性能。业务吞吐(TPS)随攻击流量的变化。
结果如上图所示,
- 没有 XDP 的一组,性能急剧下降:攻击流量在 3Mpps 时性能减半,3.5Mpps 时基本跌零;
- 有 XDP 程序的一组,攻击流量达到 19.5Mpps 之前,业务吞吐保持在 28.5K TPS 以上,过了这个临界点性能才开始急剧下降。
以上结果表明,XDP 防御 DDoS 攻击在实际中是完全可行的,单核就能轻松处理 10Gbps 的、都是最小包(minimum-packet)的 DoS 流量。 这种 DDoS 防御的部署更加灵活,无需硬件或应用做任何改动。
5.3 案例三:负载均衡(load balancing)
Facebook Katran
负载均衡的场景,我们用 Facebook 开源的 Katran 作为例子 [15]。 Katran 的工作原理是对外通告服务的 IP,这样目标是这个 IP 的流量就会被路由到 XDP 实现的负载均衡器。
- 负载均衡器对包头(source packet header)进行哈希,以此选择目标应用服务器。
- 然后将对包进行封装(encap),发送给应用服务器;
- 应用服务器解封装(decap),处理请求,然后直接将回包发给客户端(DSR 模式)。
在这个过程中,XDP 程序负责哈希、封装以及将包从接收网卡再发出去的任务。 配置信息存储在 BPF map 中,整个封装逻辑是完全在 eBPF 中实现的。
性能
为测试性能,我们给 Katran XDP 程序配置几个固定的目标机器。 对照组是 IPVS,它是 Linux 内核的一部分。性能如表 2 所示,随 CPU 数量线性增长, XDP 比 IPVS 性能高 4.3 倍。
表 2. 负载均衡器性能(Mpps)
配置:1 VIP/core, 100 DstIPs/VIP.
XDP 已经能用于解决真实问题,但作为 Linux 内核的一部分,XDP 还在快速开发过程中。
6.1 eBPF 程序的限制
前面提到,加载到 eBPF 虚拟机的程序必须保证其安全性(不会破坏内核),因此对 eBPF 程序作了一下限制,归结为两方面:
- 确保程序会终止:在实现上是通过禁止循环和限制程序的最大指令数(max size of the program);
- 确保内存访问的安全:通过 3.4 小结介绍的寄存器状态跟踪(register state tracking)来实现。
校验逻辑偏保守
由于校验器的首要职责是保证内核的安全,因此其校验逻辑比较保守, 凡是它不能证明为安全的,一律都拒绝。有时这会导致假阴性(false negatives), 即某些实际上是安全的程序被拒绝加载;这方面在持续改进。
- 校验器的错误提示也已经更加友好,以帮助开发者更快定位问题。
- 近期已经支持了 BPF 函数调用(function calls)。
- 正在计划支持有限循环(bounded loops)。
- 正在提升校验器效率,以便处理更大的 BPF 程序。
缺少标准库
相比于用户空间 C 程序,eBPF 程序的另一个限制是缺少标准库,包括 内存分配、线程、锁等等库。
- 内核的生命周期和执行上下文管理(life cycle and execution context management )部分地弥补了这一不足,(例如,加载的 XDP 程序会为每个收到的包执行),
- 内核提供的 helper 函数也部分地弥补了一不足。
一个网卡接口只能 attach 一个 XDP 程序
这个限制其实也是可以绕过的:将 XDP 程序组织成程序数组,通过尾 调用,根据包上下文在程序之间跳转,或者是将几个程序做 chaining。
6.2 用户体验和调试
XDP 程序运行在内核,因此常规的用户空间 debug 工具是用不了的,但内核自带的 debug 和 introspection 功能是可以用在 XDP (及其他 eBPF 程序)上的。 包括:
- tracepoints and kprobes [13]
- performance counters that are part of the perf subsystem [42]
但不熟悉内核生态系统的开发者可能会对这些工具感到非常陌生,难以使用。因此,也出 现了一些更方便普通开发者的工具,包括 BCC [50]、bpftool [8]、libbpf 函数库 [30] 等等。
6.3 驱动支持
设备要支持 XDP,需要实现内核核心网络栈暴露出的一个 API。 写作本文时 Linux 4.18 已经有 12 种驱动支持 XDP,包括了大部分高速网卡。 最新列表见 [2]。
随着 XDP 系统的不断成熟,核心代码逐渐上移到内核中,驱动需要维护的代码越 来越少。例如,redirection action 支持新的 target 时,无需驱动做任何改动。
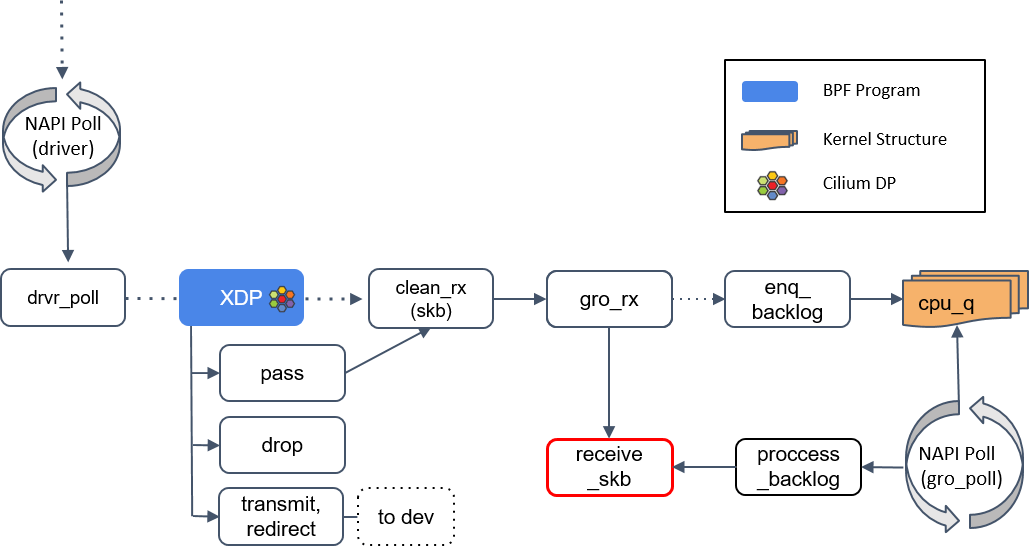
最后,对于那些不支持 XDP 的驱动,内核提供了 Generic XDP feature [39],这是软件实现的 XDP,性能会低一些, 在实现上就是将 XDP 的执行上移到了核心网络栈(core networking stack)。
XDP 在内核收包函数 receive_skb() 之前,
Generic XDP 在 receive_skb() 之后,
更多关于 Generic XDP,可参考参考: (译) 深入理解 Cilium 的 eBPF 收发包路径(datapath)(KubeCon, 2019)。 译注。
6.4 性能提升
XDP 和 DPDK 之间还有一些性能差距,一些改进工作正在进行中:
- 驱动代码 micro-optimisations
- 删除核心 XDP 代码中的非必要操作
- 通过批处理平摊处理开销
6.5 QoS 和 Rate Transitions
当前,XDP 还没有任何 QoS 机制。 尤其是,如果对端已经过载(例如两端的网络速度或特性不匹配),XDP 程序是收不到任何背压(back-pressure)的,
虽然 XDP 中缺少 QoS,但 Linux 内核网络栈中却有很多业界最佳的 Active Queue Management (AQM) 特性和 packet scheduling algorithms [23]。 这些特性中,部分并不适用于 XDP,但我们相信能够 以一种对包处理应用完全透明的方式,选择其中部分集成到 XDP。 我们计划对这一方向进行更深入研究。
6.6 加速传输层协议
我们已经证明 XDP 能在保留操作系统原有功能的前提下,集成到操作系统中,实现高速包数据。
目前的 XDP 还是用于无状态包处理(stateless packet processing) ,如果将这个模型扩展到有状态传输层协议(stateful transport protocols),例如 TCP,它能给依赖可靠/有状态传输的应用提供类似的性能提升。
实际上,已经有一些研究证明,相比于操作系统的协议栈,accelerated transport protocols 能显著提升性能[5, 25, 35, 52]。其中的一个解决方案 [52] 表明,在保留内 核 TCP 协议栈的的前提下,原始包处理性能(raw packet processing)存在巨大的提升 空间。
XDP 非常适用于这种场景,目前也已经有一些关于如何实现的初步讨论 [21], 虽然离实际使用还很远,但仍然是一个令人振奋的、扩展 XDP 系统 scope 的方向。
6.7 内核-用户空间零拷贝(zero-copy to userspace)
3.1 小节提到,XDP 程序能将数据包重定向到用户空间应用(userspace application)打 开的特殊类型 socket。这可以用于加速客户端和服务端在同一台机器 的网络密集型应用(network-heavy applications running on the local machine)。
更多信息可参考: (译) 利用 ebpf sockmap/redirection 提升 socket 性能(2020)。 这里使用的是 BPF 而非 XDP,但核心原理是一样的,只是程序执行的位置(hook)不同。 译注。
但在目前的实现中,这种方式在底层仍然需要拷贝包数据,因此性能会打折扣。
目前已经有工作在进行,通过 AF_XDP 实现真正的数据零拷贝。但这项工作需要 对网络设备的内存处理过程有一些限制,因此需要设备驱动的显式支持。 第一个支持这个功能的 patch 已经合并到 4.19 内核,更多驱动的支持 正在添加中。初步的性能测试结果还是很乐观的,显示能达到 20Mpps/core 的内核到用户 空间传递(transfer)速度。
6.8 XDP 作为基础构建模块(XDP as a building block)
正如 DPDK 用于高层包处理框架的底层构建模块(例如 [31]),XDP 有望成为高层应用的运行时环境 (runtime environment for higher-level applications)。
实际上,我们看到一些基于 XDP 的应用和框架已经出现了。包括
- Cilium security middle-ware [3]
- Suricata network monitor [4]
- Open vSwitch [49]
- P4-to-XDP compiler project [51]
甚至还有人尝试将 XDP 作为 DPDK 的一种底层驱动 [53]。
本文描述了 XDP,一个安全、快速、可编程、集成到操作系统内核的包处理框架。 测试结果显示,XDP 能提供 24Mpps/core 的高处理性能,这一数字虽然与基于 kernel bypass 的 DPDK 仍有差距,但提供了其他一些非常有竞争力的优势:
- 兼容内核安全和管理框架(kernel bypass 方式在 bypass 内核网络栈的同时,也将安全和设备管理等这些极其重要的基础设施 bypass 了);
- 兼容内核网络栈,可选择性利用内核已有的基础设施和功能;
- 提供与内核 API 一样稳定的编程接口;
- 对应用完全透明;
- 更新、替换程序的过程不会引起服务中断;
- 无需专门硬件,无需独占 CPU 等资源。
相比于 kernel bypass 这种非此即彼、完全绕开内核的方式,我们相信 XDP 有更广阔的的应用前景。 Facebook、Cloudflare 等公司实际落地的 XDP 应用,更加增强了我们的这种信心。
最后,XDP 系统还在快速发展,前面也列出了一些正在未来可能会做的开发/优化工作。
XDP has been developed by the Linux networking community for a number of years, and the authors would like to thank everyone who has been involved. In particular,
- Alexei Starovoitov has been instrumental in the development of the eBPF VM and verifier;
- Jakub Kicinski has been a driving force behind XDP hardware offloading and the bpftool utility;
- Björn Töpel and Magnus Karlsson have been leading the AF_XDP and userspace zero-copy efforts.
We also wish to extend our thanks to the anonymous reviewers, and to our shepherd Srinivas Narayana, for their helpful comments.
- [1] David Ahern. 2018. XDP forwarding example. https://elixir.bootlin.com/linux/ v4.18-rc1/source/samples/bpf/xdp_fwd_kern.c
- [2] Cilium Authors. 2018. BPF and XDP Reference Guide. https://cilium.readthedocs.io/en/latest/bpf/
- [3] Cilium Authors. 2018. Cilium software. https://github.com/cilium/cilium
- [4] Suricata authors. 2018. Suricata - eBPF and XDP. https://suricata.readthedocs.io/en/latest/capture-hardware/ebpf-xdp.html
- [5] Adam Belay, George Prekas, Ana Klimovic, Samuel Grossman, Christos Kozyrakis, and Edouard Bugnion. 2014. IX: A protected dataplane operating system for high throughput and low latency. In Proceedings of the 11th USENIX Symposium on Operating System Design and Implementation (OSDI ’14). USENIX.
- [6] Gilberto Bertin. 2017. XDP in practice: integrating XDP in our DDoS mitigation pipeline. In NetDev 2.1 - The Technical Conference on Linux Networking.
- [7] Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, et al. 2014. P4: Programming protocol-independent packet processors. ACM SIGCOMM Computer Communication Review 44, 3 (2014).
- [8] bpftool authors. 2018. bpftool manual. https://elixir.bootlin.com/linux/v4.18-rc1/source/tools/bpf/bpftool/Documentation/bpftool.rst
- [9] Cisco. 2018. TRex Traffic Generator. https://trex-tgn.cisco.com/
- [10] CZ.nic. 2018. BIRD Internet Routing Daemon. https://bird.network.cz/
- [11] Luca Deri. 2009. Modern packet capture and analysis: Multi-core, multi-gigabit, and beyond. In the 11th IFIP/IEEE International Symposium on Integrated Network Management (IM).
- [12] Mihai Dobrescu, Norbert Egi, Katerina Argyraki, Byung-Gon Chun, Kevin Fall, Gianluca Iannaccone, Allan Knies, Maziar Manesh, and Sylvia Ratnasamy. 2009. RouteBricks: exploiting parallelism to scale software routers. In Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. ACM.
- [13] Linux documentation authors. 2018. Linux Tracing Technologies. https://www.kernel.org/doc/html/latest/trace/index.html
- [14] Paul Emmerich, Sebastian Gallenmüller, Daniel Raumer, Florian Wohlfart, and Georg Carle. 2015. Moongen: A scriptable high-speed packet generator. In Proceedings of the 2015 Internet Measurement Conference. ACM.
- [15] Facebook. 2018. Katran source code repository. https://github.com/facebookincubator/katran
- [16] Linux Foundation. 2018. Data Plane Development Kit. https://www.dpdk.org/
- [17] The Linux Foundation. 2018. FRRouting. https://frrouting.org/
- [18] Sebastian Gallenmüller, Paul Emmerich, Florian Wohlfart, Daniel Raumer, and Georg Carle. 2015. Comparison of Frameworks for High-Performance Packet IO. In Proceedings of the Eleventh ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS ’15). IEEE Computer Society, 29–38.
- [19] Sangjin Han, Keon Jang, KyoungSoo Park, and Sue Moon. 2010. PacketShader: a GPU-accelerated software router. In ACM SIGCOMM Computer Communication Review, Vol. 40. ACM.
- [20] Sangjin Han, Scott Marshall, Byung-Gon Chun, and Sylvia Ratnasamy. 2012. MegaPipe: ANewProgramming Interface for Scalable Network I/O. In Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’12).
- [21] Tom Herbert. 2016. Initial thoughts on TXDP. https://www.spinics.net/lists/ netdev/msg407537.html
- [22] Toke Høiland-Jørgensen, Jesper Dangaard Brouer, Daniel Borkmann, John Fastabend, Tom Herbert, David Ahern, and David Miller. 2018. XDP-paper online appendix. https://github.com/tohojo/xdp-paper
- [23] Toke Høiland-Jørgensen, Per Hurtig, and Anna Brunstrom. 2015. The Good, the Bad and the WiFi: Modern AQMs in a residential setting. Computer Networks 89 (Oct. 2015).
- [24] Solarflare Communications Inc. 2018. OpenOnload. https://www.openonload.org/
- [25] EunYoung Jeong, ShinaeWoo, Muhammad Asim Jamshed, Haewon Jeong, Sunghwan Ihm, Dongsu Han, and KyoungSoo Park. 2014. mTCP: a Highly Scalable User-level TCP Stack for Multicore Systems.. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’14), Vol. 14. 489–502.
- [26] Rick Jones. 2018. Netperf. Open source benchmarking software. http://www. netperf.org/
- [27] Jakub Kicinski and Nic Viljoen. 2016. eBPF/XDP hardware offload to SmartNICs. In NetDev 1.2 - The Technical Conference on Linux Networking.
- [28] Davide Kirchner, Raihana Ferdous, Renato Lo Cigno, Leonardo Maccari, Massimo Gallo, Diego Perino, and Lorenzo Saino. 2016. Augustus: a CCN router for programmable networks. In Proceedings of the 3rd ACM Conference on Information- Centric Networking. ACM.
- [29] Chris Lattner and Vikram Adve. 2004. LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the international symposium on Code generation and optimization: feedback-directed and runtime optimization. IEEE Computer Society.
- [30] libbpf authors. 2018. libbpf source code. https://elixir.bootlin.com/linux/v4.18-rc1/source/tools/lib/bpf
- [31] Leonardo Linguaglossa, Dario Rossi, Salvatore Pontarelli, Dave Barach, Damjan Marjon, and Pierre Pfister. 2017. High-speed software data plane via vectorized packet processing. Technical Report. Telecom ParisTech.
- [32] John W Lockwood, Nick McKeown, Greg Watson, Glen Gibb, Paul Hartke, Jad Naous, Ramanan Raghuraman, and Jianying Luo. 2007. NetFPGA–an open platform for gigabit-rate network switching and routing. In IEEE International Conference on Microelectronic Systems Education. IEEE.
- [33] Rodrigo B Mansilha, Lorenzo Saino, Marinho P Barcellos, Massimo Gallo, Emilio Leonardi, Diego Perino, and Dario Rossi. 2015. Hierarchical content stores in high-speed ICN routers: Emulation and prototype implementation. In Proceedings of the 2nd ACM Conference on Information-Centric Networking. ACM.
- [34] Tudor Marian, Ki Suh Lee, and Hakim Weatherspoon. 2012. NetSlices: scalable multi-core packet processing in user-space. In Proceedings of the eighth ACM/IEEE symposium on Architectures for networking and communications systems. ACM.
- [35] Ilias Marinos, Robert NM Watson, and Mark Handley. 2014. Network stack specialization for performance. In ACM SIGCOMM Computer Communication Review, Vol. 44. ACM, 175–186.
- [36] Joao Martins, Mohamed Ahmed, Costin Raiciu, Vladimir Olteanu, Michio Honda, Roberto Bifulco, and Felipe Huici. 2014. ClickOS and the art of network function virtualization. In Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation. USENIX Association.
- [37] Steven McCanne and Van Jacobson. 1993. The BSD Packet Filter: A New Architecture for User-level Packet Capture. In USENIX winter, Vol. 93.
- [38] Sebastiano Miano, Matteo Bertrone, Fulvio Risso, Massimo Tumolo, and Mauricio Vásquez Bernal. 2018. Creating Complex Network Service with eBPF: Experience and Lessons Learned. In IEEE International Conference on High Performance Switching and Routing.
- [39] David S. Miller. 2017. Generic XDP. https://git.kernel.org/torvalds/c/ b5cdae3291f7
- [40] Robert Morris, Eddie Kohler, John Jannotti, and M Frans Kaashoek. 1999. The Click modular router. ACM SIGOPS Operating Systems Review 33, 5 (1999).
- [41] Juniper Networks. 2018. Juniper Contrail Virtual Router. https://github.com/Juniper/contrail-vrouter
- [42] perf authors. 2018. perf: Linux profiling with performance counters. https://perf.wiki.kernel.org/index.php/Main_Page
- [43] Simon Peter, Jialin Li, Irene Zhang, Dan RK Ports, Doug Woos, Arvind Krishnamurthy, Thomas Anderson, and Timothy Roscoe. 2016. Arrakis: The operating system is the control plane. ACM Transactions on Computer Systems (TOCS) 33, 4 (2016).
- [44] Ben Pfaff, Justin Pettit, Teemu Koponen, Ethan J Jackson, Andy Zhou, Jarno Rajahalme, Jesse Gross, Alex Wang, Joe Stringer, Pravin Shelar, et al. 2015. The Design and Implementation of Open vSwitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15).
- [45] Ntop project. 2018. PF_RING ZC (Zero Copy). https://www.ntop.org/products/ packet-capture/pf_ring/pf_ring-zc-zero-copy/
- [46] Luigi Rizzo. 2012. Netmap: a novel framework for fast packet I/O. In 21st USENIX Security Symposium (USENIX Security 12).
- [47] Luigi Rizzo and Giuseppe Lettieri. 2012. Vale, a switched ethernet for virtual machines. In Proceedings of the 8th international conference on Emerging networking experiments and technologies. ACM.
- [48] Pedro M Santiago del Rio, Dario Rossi, Francesco Gringoli, Lorenzo Nava, Luca Salgarelli, and Javier Aracil. 2012. Wire-speed statistical classification of network traffic on commodity hardware. In Proceedings of the 2012 Internet Measurement Conference. ACM.
- [49] William Tu. 2018. [ovs-dev] AF_XDP support for OVS. https://mail.openvswitch. org/pipermail/ovs-dev/2018-August/351295.html
- [50] IO Visor. 2018. BCC BPF Compiler Collection. https://www.iovisor.org/ technology/bcc
- [51] VMWare. 2018. p4c-xdp. https://github.com/vmware/p4c-xdp [52] Kenichi Yasukata, Michio Honda, Douglas Santry, and Lars Eggert. 2016. StackMap: Low-Latency Networking with the OS Stack and Dedicated NICs. In 2016 USENIX Annual Technical Conference (USENIX ATC 16). USENIX Association, 43–56.
- [53] Qi Zhang. 2018. [dpdk-dev] PMD driver for AF_XDP. http://mails.dpdk.org/ archives/dev/2018-February/091502.html
如有侵权请联系:admin#unsafe.sh