Reading Time: 6 minutes
It’s no secret that, since the beginning of the year, I’ve spent a good amount of time learning how to fuzz different Windows software, triaging crashes, filling CVE forms, writing harnesses and custom tools to aid in the process.
Today I would like to sneak peek into my high-level process of designing a Homemade Fuzzing Platform, which I’m currently using to fuzz some targets leveraging millions of samples; how I did it, what setup and technologies I’ve used etc…
This blog post is a re-post of the original article “Homemade Fuzzing Platform Recipe” that I have written for Yarix on YLabs.
Fuzzing Phases
- Identify the Target: when searching for targets I like to stick to the following metrics:
- Complexity & Attack surface: I usually prefer to stick with proprietary and complex software with a huge attack surface, likely because fewer fellow researchers have spent time looking at it or, that they have focused on some very specific part/component of it since it’s so huge.
- Popularity:
- Software that is included as a bundled application, installed on many systems and with many downloads.
- Specific software that is used by a smaller user base to accomplish specific tasks (e.g., SCADA software, peculiar design tools used by fashion boutiques etc.).
- If targeting a specific library instead of complete software, look for a binary that is shared across multiple applications, as vulnerabilities in such target will be of higher value due to the expanded user base.
- Vulnerability History: looking at the vendor’s history with regards to previously discovered vulnerabilities; a vendor with a poor track record is more likely to have poor coding practices that will likely result in vulnerabilities.
- Identify Inputs: enumerate all user-controllable input vectors; failing to do so can severely limit your fuzzing capabilities.
- Generate Corpus: once input vectors have been identified, fuzz data must be generated/gathered. The decision to use predetermined values, mutate existing data or generate data dynamically will depend on the target and the data format. I personally start, if possible, by gathering input vectors directly from the software and scraping the net searching for data that can be ingested by the target (e.g., JPG files for image viewer software). After this step, I usually minimize the collected corpus and start applying, where possible, random mutation to the database. If coverage is low, or random mutation is not possible, I fall back on understanding the protocol/file format the software use and letting the fuzzer generate valid data from the provided structure.
- Fuzzing Process: this step involves loading the corpus in the target application
- Monitor for Exceptions: monitoring the target application for exceptions that occurred during the fuzzing process.
- Crash Triaging: once a fault is detected is crucial determining the uniqueness and exploitability of the crash. This is usually the most time-consuming process as crash exploitability must be determined following a manual triaging approach.
Target Prerequisites & Constraints
As a target, I’ve chosen a popular music player (which results and crashes I’m going to disclose in a future blog post) and I’ve decided to focus solely on the MP3 file format as input vector.
I had roughly 20 million MP3 samples, each iteration (launching the target application, reproducing the MP3 sample, terminating the application) took between 3 and 4 seconds. I was not able to use multithreading as no more than a single instance of the target application can run at the same time. It was immediately clear that with a single machine (instance from now on) I would not be able to cut the chase as 20 M samples x 4 seconds =~ 30 months of execution time.
From that time constraint, it was obvious that I would have needed something more powerful in order to exhaust the space of the samples in a timely human manner.
Fuzzing Platform Requirements
When designing the platform, I’ve used to handle the fuzzing process, the following requirements were taken into considerations:
- Reusability: once designed, it should be used over and over to fuzz different targets.
- General Purpose vs Specialization: even if it is cool to have a generic fuzzing interface for every task, I’ve decided to keep it specialized in file format fuzzing in order to minimize “Complexity and Development Time”. Even so, it has been designed in a pretty modular way that it can also be extended in the future if needed.
- Complexity & Development Time: as I’m more interested in the exploitation phase rather than the developing process, I wanted to keep things simple (KISS principle). For example, I’ve decided to leverage x86 fault detection only, as most of my targets are compiled for that architecture. However, in a second take, I’ll like to expand it to support x64 architecture too.
- Scalability: the platform should be something easily expandible and scalable, able to support multiple fuzzing instances with no hassle.
Fuzzing Platform Technology
Platform
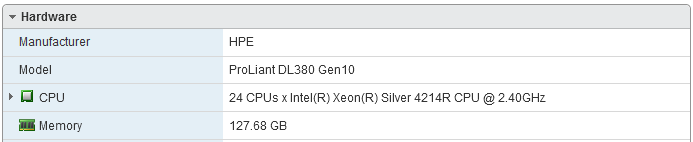
All the project is based on an HP ProLiant DL380 Gen 10 server with Intel Xeon 4214R CPU @2.40 GHz and 128 GB of RAM.
 On top of the bare metal server, I’ve installed VMWare ESXI. VMware will allow for the needed scalability, deploying multiple VMs when increased fuzzing throughput capacity is needed.
On top of the bare metal server, I’ve installed VMWare ESXI. VMware will allow for the needed scalability, deploying multiple VMs when increased fuzzing throughput capacity is needed.
Orchestrator
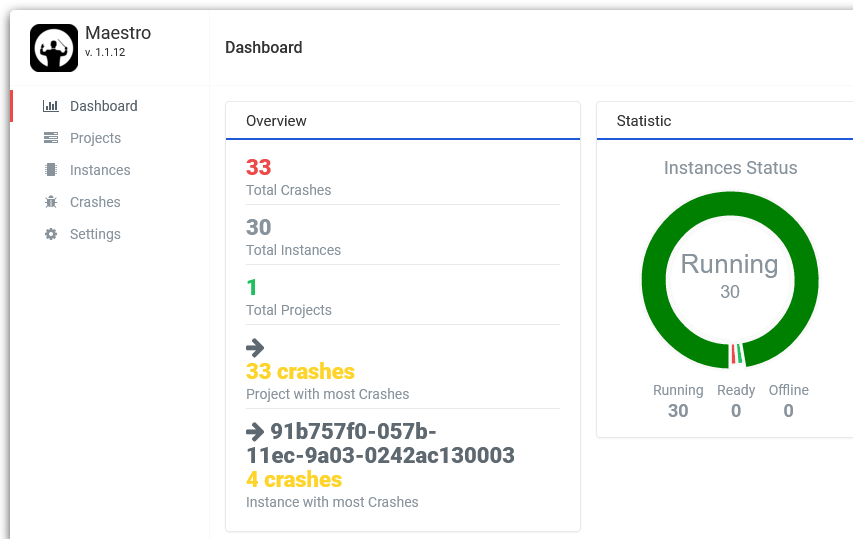
Maestro (the instances’ orchestrator) was developed over the classical XAMP stack (Windows, Apache, PHP, MySQL) mainly because I’m familiar with it as well as the team. Apache and PHP should provide enough capabilities and performance given the fact that Maestro is mainly a GUI allowing users to:
- Create new fuzzing projects and defining their properties (e.g., target, execution time, threads to be used etc.
- Monitor and control the status of the deployed instances.
- Corpus files are automatically sent to the instances.
- Crash artefacts are automatically collected on Maestro.
Instances
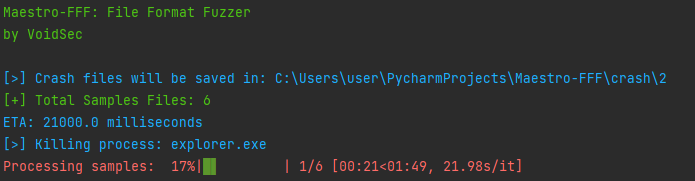
Maestro-FFF is the Python software running on the deployed instances, it is responsible for:
- Registering the instance on Maestro.
- Downloading the fuzzing corpus.
- Reporting the status of the Instance as well as the progress of the fuzzing process.
- Executing the target application
- Collecting exceptions and crashes; sending samples causing the target to crash back to Maestro, allowing a centralized interface to review and triage them.
 I’ve chosen Python mainly because I’m familiar with it and because it was easy to implement, from scratch, a multithreaded application able to support different operative systems.
I’ve chosen Python mainly because I’m familiar with it and because it was easy to implement, from scratch, a multithreaded application able to support different operative systems.
While the main “body” is developed in Python, the fault detection mechanism is a C executable that leverage the libdasm library to detect and report crashes.
It reports back to Maestro-FFF the occurred exception, faulting memory address and instruction as well as it dumps the status of the registers.
While it is a good point to start from, every crash must be loaded into WinDbg at a later time, leveraging its “!exploitable” plugin, the plugin output will be used to identify unique crashes and then crashes will be triaged to determine their exploitability.
I’ve deployed 30 instances of Maestro-FFF that exhausted the space of the fuzzing corpus in a month of continuous work.
Roadblock
Among all the different roadblocks I’ve encountered during this project, the absence of a working logging functionality in Python was the most problematic; while the logging module is awesome, it lacks support on Windows when multithreading/multiprocessing is used. Even if I’ve resolved the problem in the hackiest way possible (acquiring a global lock on the file in a thread and releasing it once it finished), I’m still hoping that I’ve missed something in the documentation or some non-standard python modules. So, if you know a Python multiprocessing/multithreading logging module compatible with Windows, please let me know!
Conclusion
While I’ve started my career as a web developer and later transitioned into the cyber security field, I’ve definitely jumped out of my comfort zone glueing all these different pieces of software and components together. I had to employ skills spanning many different IT fields and where I’m not proficient. While it’s unarguably clear to me that some things could be improved (or completely rethought and/or refactored to a more professional level, using modern and more performing technologies), I’ll recommend everyone taking this journey and trying to write some homemade fuzzers for themselves as the number of pieces needed to complete this project are vast but provide an enormous wealth of experience.
Upcoming Article
In the next blog post I’ll disclose the fuzzed target, Maestro/Maestro-FFF metrics, triage process, crashes, CVEs, and exploit PoC.
Resources & References
- Book – Fuzzing: Brute Force Vulnerability Discovery by Michael Sutton, Adam Greene, Pedram Amini
- Companion Web Site – http://www.fuzzing.org/
如有侵权请联系:admin#unsafe.sh