
2021-09-05 00:42:28 Author: www.offensiveosint.io(查看原文) 阅读量:383 收藏
Credential stuffing, password spraying/guessing are more dangerous than anyone thinks. It leads to breaches, unauthorized access and big privacy violation. It's even more dangerous when confidential documents and information come into play like it was couple weeks ago with Polish politicians' private mailboxes.
In this article, I will show how to do reconnaissance using IntelX in the best way, it includes script that retrieves information about email addresses and displays it in a clear way as a tree view chart. This way could be used to obtain information about used passwords and other hints from previous leaks that led to "hacking" of private mailboxes of deputies of the polish senate.
It's a second story about OSINT research regarding polish government. First one presented how to map government infrastructure using Shodan.
Offensive OSINT s03e07 - Shomap - Advanced Shodan visualization
Today’s post focuses on looking for anomaly based on exposed assets from Shodan for Polish government. The visualization that was prepared presents Internet facing infrastructure with additional features which will be explained in details. It helps in red teaming assessments allowing to spot weak po…
 Wojciech
Wojciech

Quick story
It all started on one Telegram channel where screenshots from private Gmail mailbox of minister Michal Dworczyk were published. His wife's account also was hacked and posted messages regarding this incident. ABW (Internal Security Agency) and SKW (Military Counterintelligence Service) said, in a notification, that more than 4300 email addresses was targeted and accused UNC1151 for this attack.
In an official statement, prime minister Mateusz Morawiecki confirmed the incident and recommended to use two factor authentication, be careful of phishing and keep accounts more secure in general.
Couple days after Morawiecki's attendance, more emails from Dworczyk's mailbox were published, which allegedly threaten national security. We won't be analysing the emails but rather methods that potentially could be used to perform credential re-use attack across different services and websites.
To achieve that, we will use Intelx, Python and dj3s to present it in a graph but first let's get familiar with Intelx.
Script is available below
GitHub - woj-ciech/intelx_viz: Collect information about leaks for particular domain in IntelX and present it on a tree view graph.
Collect information about leaks for particular domain in IntelX and present it on a tree view graph. - GitHub - woj-ciech/intelx_viz: Collect information about leaks for particular domain in IntelX...
 GitHubwoj-ciech
GitHubwoj-ciech
IntelX
It's a Czech Republic company which I call HaveIBeenPwned on steroids. HIBP shows you only services that password has been leaked from, but IntelX also gives you insight into hashed or plain text passwords for given email address. It covers also more leaks, spam list and breaches than HIBP.
Basic access costs 1000 euro and gives you 200 search credits per day. It refers to the API, as well as web interface. In addition, Intelx runs phonebook.cz to help you gather subdomains, urls and email addresses.
IntelX supports many so called buckets
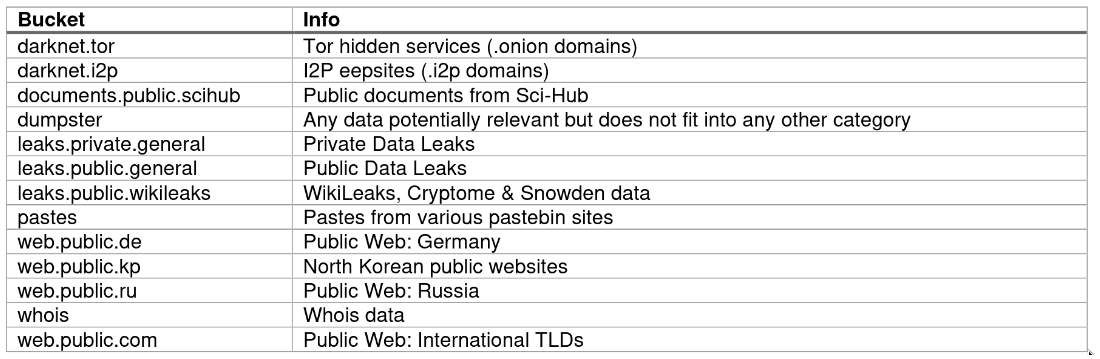
I don't need to say how useful it can be in variety of investigations and mostly related to HUMINT. You can quickly collect almost all email addresses for a company and check them against above mentioned buckets.
It allows to discover employees of the organization, find private email addresses or research bitcoin transactions. For the record, you can search by phone number, email address, IP address, credit card, domain, bitcoin address and many more.
This service has a lot features and advantages but UI needs to be more user friendly and results for particular email should be highlighted. Right now, we have many results and have to go to each one and search for the our input, which is really tedious.
Next stage is to write more consistent way of displaying results from Intelx and keep all the collected data in raw format.

Improvements for IntelX
The method I will present saves a lot of time and allow to share such report with other co-workers engaged in investigation.
First of all, we need to collect email addresses from Phonebook, you can do it as follow:
def phonebooksearch(term, maxresults=1000, buckets=[], timeout=5, datefrom="", dateto="", sort=4, media=0,
terminate=[], target=0):
"""
Conduct a phonebook search based on a search term.
Other arguments have default values set, however they can be overridden to complete an advanced search.
"""
results = []
done = False
search_id = intelx.PHONEBOOK_SEARCH(term, maxresults, buckets, timeout, datefrom, dateto, sort, media, terminate,
target)
if (len(str(search_id)) <= 3):
print(f"[!] intelx.PHONEBOOK_SEARCH() Received {intelx.get_error(search_id)}")
while done == False:
time.sleep(1) # lets give the backend a chance to aggregate our data
r = intelx.query_pb_results(search_id, maxresults)
results.append(r)
maxresults -= len(r['selectors'])
if (r['status'] == 1 or r['status'] == 2 or maxresults <= 0):
if (maxresults <= 0):
intelx.INTEL_TERMINATE_SEARCH(search_id)
done = True
return results
This function was taken straight from the API
IntelligenceX/SDK
Public SDK for Intelligence X. Contribute to IntelligenceX/SDK development by creating an account on GitHub.
 GitHubIntelligenceX
GitHubIntelligenceX
and is responsible for making a request to IntelX Phonebook API and returning results. Going into details, code shows that we need to obtain search_id and then use query_pb_results method to get into the real data. Everything is done in while loop which iterates all over the results.
At the end, it returns results in form of list with dictionaries inside.
Next function unpacks data i.e. email from the returned value and saves it to "<domain>_emails.txt".
results = phonebooksearch(term=phonebook, target=0)
try:
with open(phonebook + "_emails.txt", 'w') as emails:
for selector in results[0]['selectors']:
if selector['selectorvalue'].startswith("http"):
pass
else:
print("[*] " + selector['selectorvalue'])
emails.write(selector['selectorvalue'] + "\n")
except Exception as e:
print("[*] Can't find " + phonebook + "_emails.txt file")
To make actual search, instead of Phonebook, almost the same function is used but instead of using
intelx.PHONEBOOK_SEARCH
intelx.query_pb_results
we use
intelx.INTEL_SEARCH
intelx.query_results
To save amount of requests, script does not check each email from previous list but rather collects data for domain that matches previous input. And then it tries to find emails in the leaks line by line. This way we do make only one request to /search/intelligent endpoint with domain name, instead of checking each email.
This snippet is responsible for checking content of each match and iterating all over emails and lines to find the line in the file that contains this particular email address.
t = args.normal # domain, input
with open(args.normal + "_emails.txt", 'r') as f:
emails = f.read().splitlines()
for email in emails:
tst.update({email: []})
print('[*] Checking leaks for ' + args.normal)
print("[*] Found " + str(len(res['records'])) + " records")
for c,i in enumerate(res['records']):
view = intelx.FILE_VIEW(i['type'], i['media'], i['storageid'], i['bucket'])
print("[i] Checking " + str(c))
for line in view.splitlines():
if t in line.lower():
ems = extractEmails(line.lower())
for email in emails:
if email in ems:
print("[*] Found email " + email)
help_dict = {'systemid': i['systemid'], 'bucket': i['bucket'], 'name': i['name'],
'line': line}
tst[email].append(help_dict)
if not ems:
print("[*] Found domain " + args.normal)
help_dict = {'systemid': i['systemid'], 'bucket': i['bucket'], 'name': i['name'], 'line': line}
tst['other'].append(help_dict)
with open(args.normal + '.json', 'w') as f:
f.write(json.dumps(tst, indent=4))
print("[*] JSON has been saved to "+ args.normal + '.json')
make_html(args.normal+".json")
First, we open txt file with emails and add it to another dictionary which will be saved at the end and needed for comparison.
Previous function "search" does not return actual content of the data but only "storage id" which is passed to intelx.FILE_VIEW to view actual data.
Then we check each line if it includes the domain and later extract email from the matched line. It's necessary to do that because of the false positives, for example if we would use
if email in line:
print email
then "[email protected]" would fit "[email protected]" what we want to avoid.
so following regex is used
def extractEmails(line):
match = re.findall(r'[\w\.-]+@[\w\.-]+', line)
return match
if specific line matches email address, then information about the leak (systemid, name, bucket and line itself) is added to the dictionary. There is other case, when only domain name was found, it covers scihub, mxrecords, whois or public websites, they are added as an 'other' category to the file.
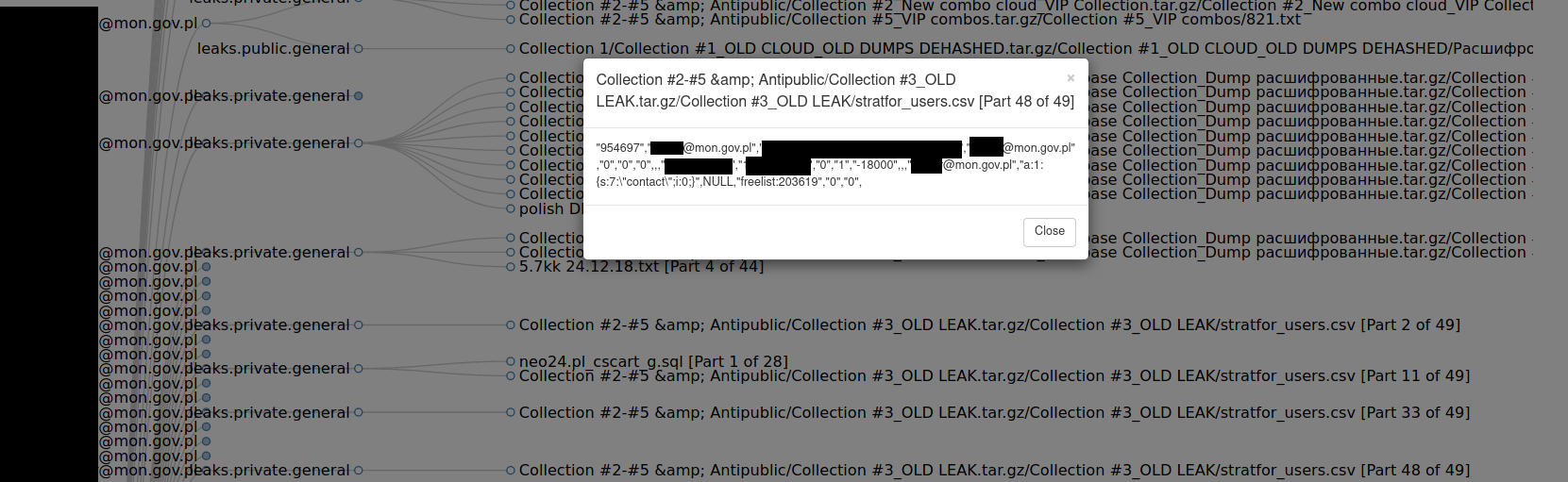
First stage results are kept in following format
"[REDACTED]@mon.gov.pl": [
{
"systemid": "4d2e9c82-a762-4076-af55-92d06116540d",
"bucket": "leaks.private.general",
"name": "Collection #2-#5 & Antipublic/Collection #3_OLD LEAK.tar.gz/Collection #3_OLD LEAK/stratfor_users.csv [Part 48 of 49]",
"line": "\"954697\",\"
[REDACTED]@mon.gov.pl\",\"[REDACTED]\",\"[REDACTED]@mon.gov.pl\",\"0\",\"0\",\"0\",,,
\"1319199254\",\"1319217035\",\"0\",\"1\",\"-18000\",,,\"[REDACTED]@mon.gov.pl\",\"a:1:{s:7:\\\"contact\\\";i:0;}\",NULL,\"freelist:203619\",\"0\",\"0\","
}
],
"[REDACTED]@mon.gov.pl": [
{
"systemid": "f98e345d-318d-40f4-b7e7-165a930d14ce",
"bucket": "leaks.private.general",
"name": "Collection #2-#5 & Antipublic/Collection #3_OLD LEAK.tar.gz/Collection #3_OLD LEAK/stratfor_users.csv [Part 43 of 49]",
"line": "\"874706\",\"
[REDACTED]@mon.gov.pl\",\"[REDACTED]\",\"[REDACTED]@mon.gov.pl\",\"0\",\"0\",\"0\",,,\
"1304499834\",\"1304499835\",\"0\",\"1\",\"-18000\",,,\"[REDACTED]@mon.gov.pl\",\"a:1:{s:7:\\\"contact\\\";i:0;}\",NULL,\"freelist:193267\",\"0\",\"0\","
}Last stage is to make a super simple HTML page with the results
html = ""
for i in data:
html = html + "<h2>" + i + "</h2>"
for j in data[i]:
html = html + "<b>" + j['name'] + "</b>" + "<br>" + "<a href=https://intelx.io/?did=" + j[
'systemid'] + ">" + bleach.clean(j['line']) + "</a> <br><br>"

Beside above page, tree view chart graph is generated but to achieve that we have to transform our previously created json to suit format for the visualization.
The viz was taken from blocks
Interactive d3.js tree diagram
d3noob’s Block 8375092
 bl.ocks.org
bl.ocks.org

and supports following format
var treeData = [
{
"name": "Top Level",
"parent": "null",
"children": [
{
"name": "Level 2: A",
"parent": "Top Level",
"children": [
{
"name": "Son of A",
"parent": "Level 2: A"
},
{
"name": "Daughter of A",
"parent": "Level 2: A"
}
]
},
{
"name": "Level 2: B",
"parent": "Top Level"
}
]
}
];
So, to transform our json we need to make a domain as a main Parent and emails as a children, then group leaks into categories (buckets) with leak content and rest of the data as a next children.
After opening the file, script creates new dictionary that will be returned at the end, and check if it's not in 'other' category. It's not added to the chart due to lot of results in many cases I tested.
Then, there are two potential ways, one when it's a first time loop comes across the bucket and if it already exists, so only content should be added as a children.
with open ('mon.gov.pl.json', 'r') as email:
emails = json.load(email)
return_dict = {"name":domain, 'children':[]}
for c,i in enumerate(emails):
helper_to_check_leak_category = []
if not i=="other":
c = c-1
return_dict['children'].append({"name": i, 'children': []})
for c2,j in enumerate(emails[i]):
if j['bucket'] not in helper_to_check_leak_category:
try:
return_dict['children'][c]['children'].append({"name":j['bucket'], 'children':[{"name":j['name'], 'systemid':j['systemid'], 'line':j['line']}]})
helper_to_check_leak_category.append(j['bucket'])
except Exception as e:
print(str(e))
else:
for c3,k in enumerate(return_dict['children'][c]['children']):
if k['name'] == j['bucket']:
return_dict['children'][c]['children'][c3]['children'].append({"name":j['name'], 'systemid':j['systemid'], 'line':j['line']})
helper_to_check_leak_category.append(j['bucket'])
pass
with open('graph_json.json', 'w') as f:
f.write(json.dumps(return_dict, indent=4))
It's a tricky thing to add another, next, records to the existing category, another iteration over already added dictionary is needed, what is shown in else statement.
Helper is used only to keep all categories and check if they are already exist.
After this transformation, we get perfect json that is comfortable with the format supported by original visualization.
{
"name": "[REDACTED]@mon.gov.pl",
"children": [
{
"name": "leaks.private.general",
"children": [
{
"name": "onliner_spambot.rar/base/original/de_5kk.txt [Part 6 of 24]",
"systemid": "d72a34f3-f062-4741-98dc-89642d87f3cf",
"line": "[REDACTED]@mon.gov.pl"
},
{
"name": "onliner_spambot.rar/base/original/all_mix_de_5.7kk.txt [Part 33 of 34]",
"systemid": "fd727c56-6566-4d5a-a2a6-7656c40a08f4",
"line": "[REDACTED]@mon.gov.pl"
}
]
}
]
},
{
"name": "[REDACTED]@mon.gov.pl",
"children": [
{
"name": "leaks.private.general",
"children": [
{
"name": "www.divecomputertraining.com.txt [Part 3 of 4]",
"systemid": "afbb6f71-ee71-464e-9a29-8f8e7d911b16",
"line": "[REDACTED]@mon.gov.pl:"
}
]
}
]
},
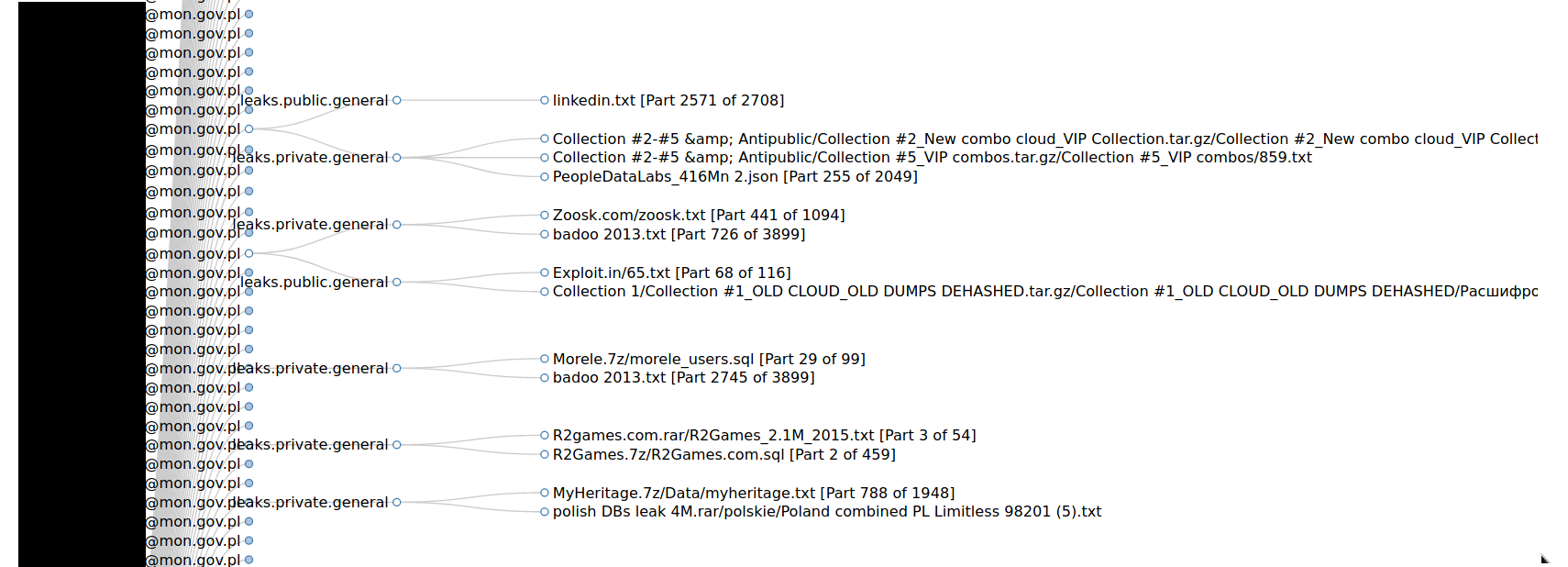
I explained technical/programming part of the problem, let's take a look how it all works together.
Putting it together
As mentioned, first thing to do is to obtain emails for your target domain. You can just use phonebook.cz and copy paste emails to the main script directory and name it "<domain>_emails.txt" and then run script with flag --normal or you can use --phonebook flag.
└─# python3 IntelXgraph.py -h
usage: IntelXgraph.py [-h] [--phonebook PHONEBOOK] [--normal NORMAL]
Quick search with Intelx
optional arguments:
-h, --help show this help message and exit
--phonebook PHONEBOOK
Set the domain for phonebook
--normal NORMAL Set the domain to search
Usage: intelx --domain 'sejm.pl'
After that it will create new files ("<domain>.json" and "graph.json"). HTML & D3js file is located in the same directory and load only "graph.json", so each time you run it, your file will be overwritten unless you change the name.
At the end, we get the HTML file with sorted results - emails, line of the leak where email appears and link to the IntelX for this leak, however when you click on the link, one request will be deducted from your account.
Graph is clear, easy to read, clickable and interactive. It shows every email that was gathered and associated leaks/breaches with the account. It helps to quickly get information about your target email address and look for password and personal info leaked to the public and archived by IntelX.
Research
That was very long introduction to the real research. You should be aware what happened with politician mailboxes and modus operandi of UNC1511 group. Also, how I approach from technical perspective to recreate and maybe improve their reconnaissance phase.
From the articles, we know that main domain was sejm.pl, where many politicians keep their malboxes. Quick look and we found a paste with private emails and phone numbers published couple years ago.
We can pivot and check each private, exposed, email separately but do not look for general domain like 'gmail' in the script, it has too much results and it's not suitable for this case.
I decided though, to check most critical departments in government, like Ministerstwo Obrony Narowodej (Ministry of National Defence), Agencja Bezpieczenstwa Wewnetrznego (Internal security agency), Wojsko Polskie (Polish army) or Ministerstwo Spraw Zagranicznych (Ministry of Foreign Affairs). Of course, you can specify domain from your own country or also check for private companies.
It's very important during spear phishing campaigns or due to nature of gathered data, you can address owner of the email address based on his name, thanks to the leaks that disclose who owns the email address or reveal his password to him.
Another advantage of such script & information is to share awareness about password reuse and credential stuffing attacks. If someone used password in one service, especially simple one, it's high possibility that the person set same password for completely different platform. Attackers having such information could try to use the credentials to get into account, that's why two factor authentication is very important in this case.
Beside that, another idea comes to mind obviously - to check for leaked nicknames in another social media platforms like Twitter, Facebook, Steam, etc.
Next thing you should care during the investigation is to look for personal email addresses and phone number or whatever else you can find. It happens often that person gives secondary email to the service, which is the private one. Then, depends of the uniqueness of the email you can look for the nickname or search further in IntelX to gain more intelligence about the target.
Passwords can give another hint about family, spouse, personal views, favourite artist and lot more depends of the person and scenario. It's yet another way to gather more intel about the target and potentially confirm another findings.
After explaining basic principles of research, we can move the the most interesting part and analyse results for the critical assets of critical departments in government.
Policja.gov.pl
There are 129 leaked email addresses for polish Police, most of them in format <role>@policja.gov.pl ([email protected]), <first_letter_of_name>.<surname>@policja.gov.pl and <name>.<surname>@policja.gov.pl. Most of the emails look real, sometimes people registered account on such email for trolling or messing up, but for this domain, most look legitimate.
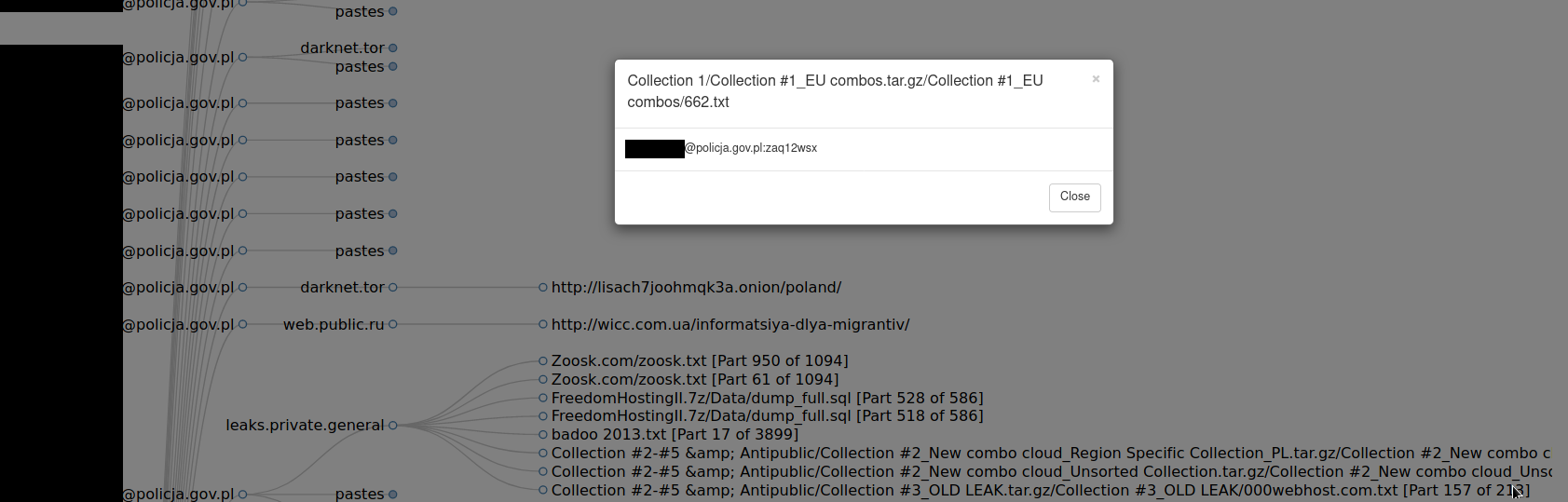
I don't want to disclose any names, associated passwords or any other personal details, but rather show how the government takes care of his own personal and business accounts. As the background story showed, it can include confidential documents and cause national security concerns.
Going back to the Police leaks, I saw many emails with super weak password like above "zaq12wsx". It's easy to guess, bruteforce and is one of the first in every password dictionary. Following NSA statement, bruteforcing is still in use by Russian hackers. Thanks to previous, leaked password they might know requirements for the passwords to be created and adjust their dictionaries or just add them to the dictionary.
NSA, Partners Release Cybersecurity Advisory on Brute Force Global Cyber Campaign
The National Security Agency (NSA), Cybersecurity and Infrastructure Security Agency (CISA), Federal Bureau of Investigation (FBI) and the UK’s National Cyber Security Centre (NCSC) released a
National Security Agency Central Security Service

Completely another thing that I will never understand is when government officials register themselves on different social media platform with 'gov' email address. There are dating websites (infamous Badoo leak from 2013), ddos Secrets, wikileaks, Usenet, Freedom Hosting, People Data Labs, Linkedin and also emails are included in compilations and spamlists.
mon.gov.pl
Checking such date for hundreds of people, you can focus on statistics and anomalies to find something out of norm. In the below example, one member of Ministry of National Defence used his government email address in some polish online story giving his personal phone number, which next can be used to find his Facebook account or to use it for further investigation including SMS phishing.
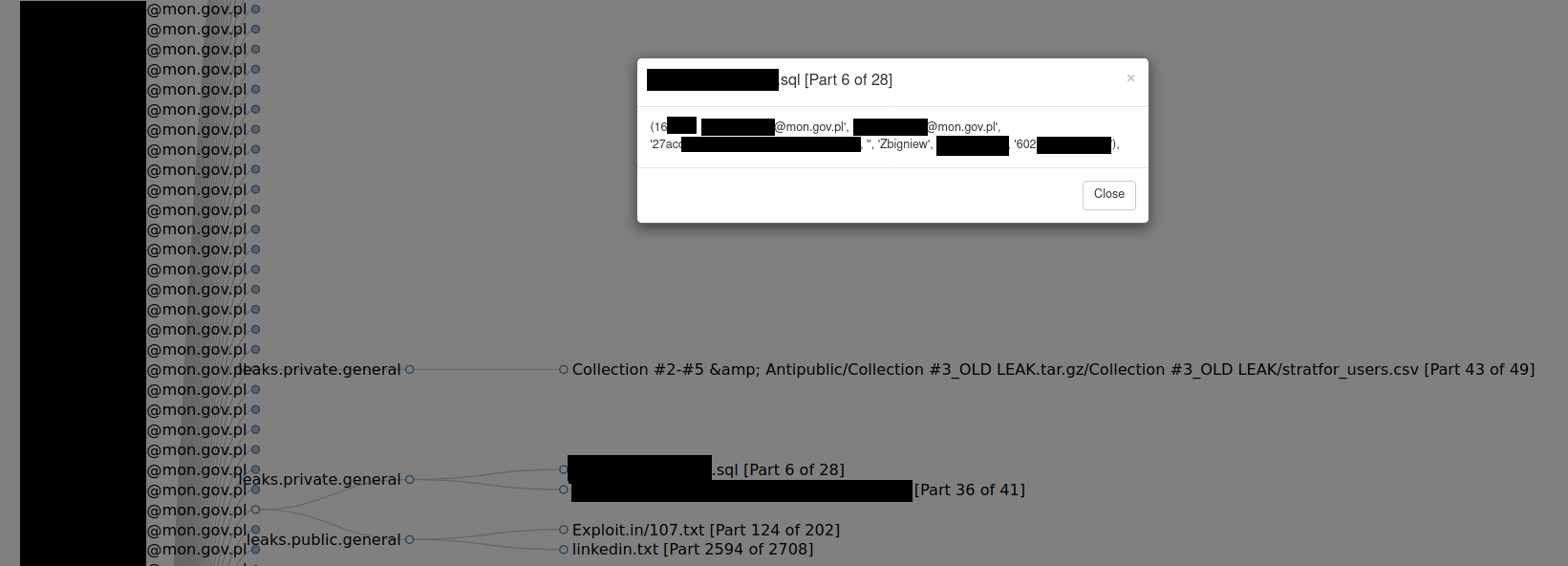
ncbj.gov.pl
If you remember from previous part of reconnaissance, we can group government infrastructure based on the organization with Shomap
Offensive OSINT s03e07 - Shomap - Advanced Shodan visualization
Today’s post focuses on looking for anomaly based on exposed assets from Shodan for Polish government. The visualization that was prepared presents Internet facing infrastructure with additional features which will be explained in details. It helps in red teaming assessments allowing to spot weak po…
Offensive OSINTWojciech
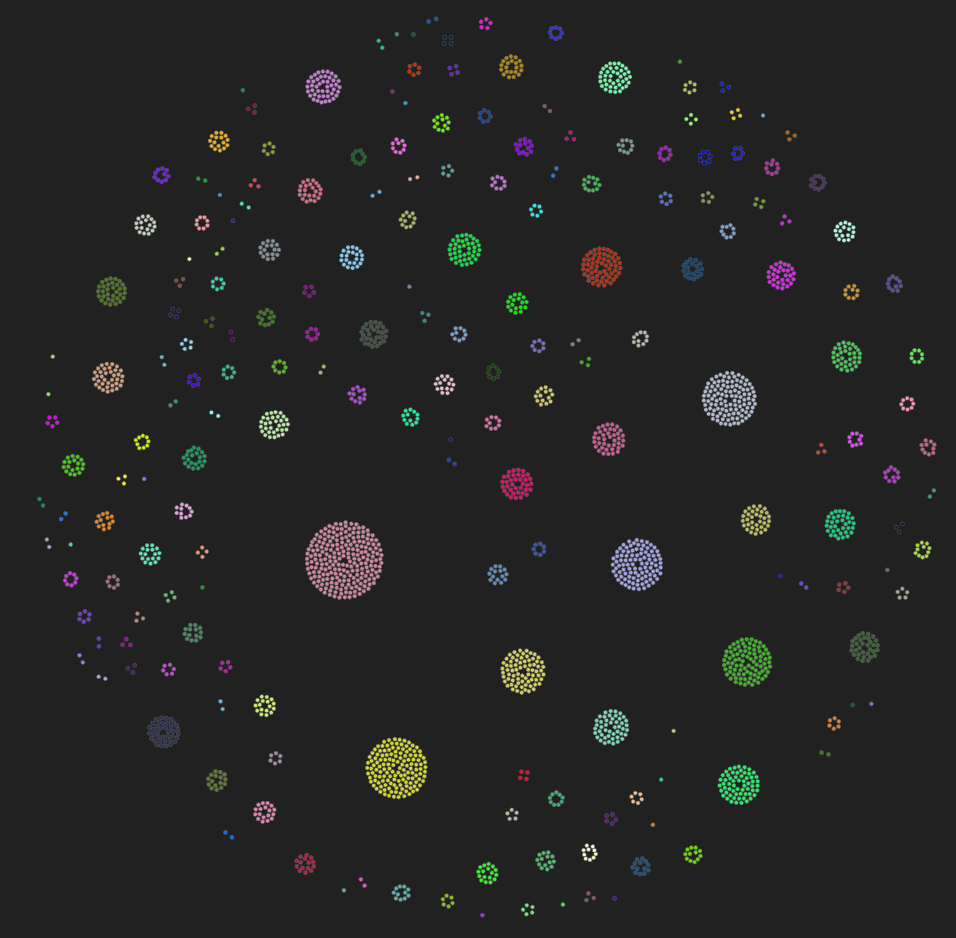
and then look for emails for this org.
The National Center of Nuclear Research netblock was found and
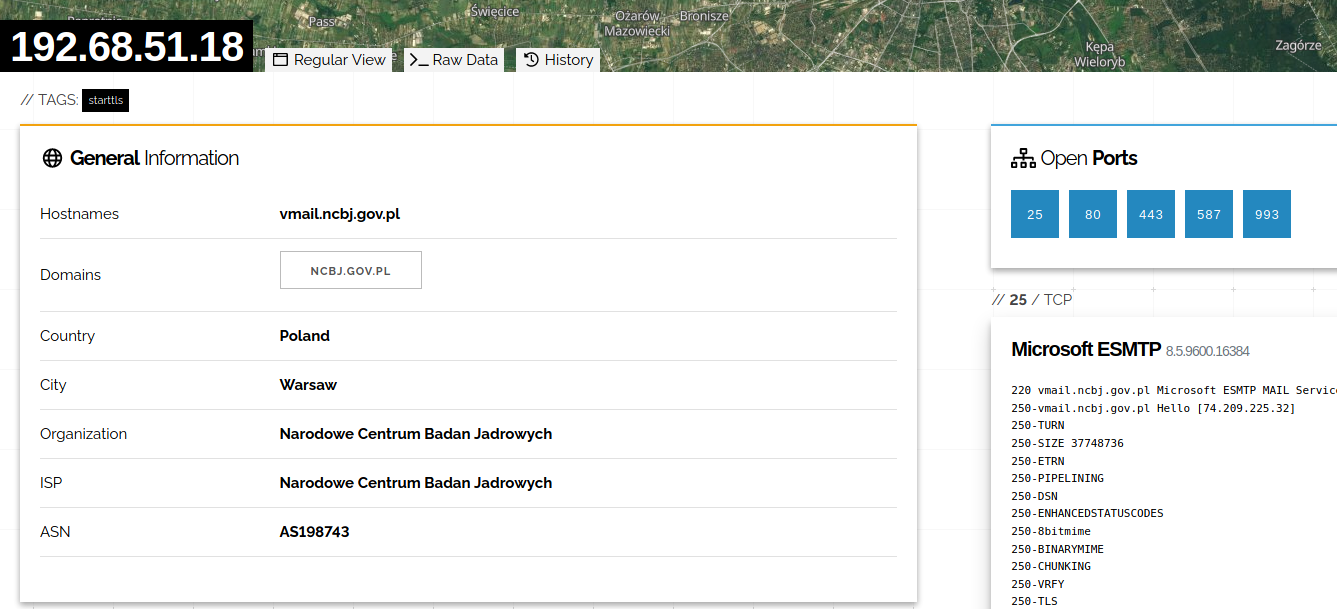
based on their SMTP server, we know they use ncbj.gov.pl domain. So Phonebook gives around 300 emails, which we copy paste to 'ncbj.gov.pl_emails.txt" file and run script.
Of course, graph and html page will be created and we can start analyse it, for example, find personal emails of the employees like below and then pivot it to find more intel necessary to compromise account or perform successful spear phishing.
I don't want to share details of the research, beside these couple examples, from obvious reasons, but right now if you have an IntelX subscription, you can check by yourself how politicians create passwords and how skilled they are in terms of cyber security & privacy.
Advice
The most important part is to draw conclusions and react properly when our data have been leaked.
Answer is simple and predictable - you have to implement two factor authentication for all of your account using apps like Google Authenticator instead of SMS code. This way we are protected from SS7 and Sim Swapping attacks.
Next thing, which should be obvious, is to use password manager, especially when we have to deal with confidential documents. Thanks to that, our passwords will be strong and automatically generated with proper randomness hard to crack.
In addition, you have to monitor your email address if they have been leaked from any service. OPSEC does not work retroactively and if we forgot about any account, services like HIBP can give us notification about our email in any leaked database.
It might sound ironically, but IntelX cares about privacy and we can contact them and delete our records from their archive.
Conclusion
Successful attacks very depends on the reconnaissance you made, it gives you direction you should follow to find entry point and weakness in infrastructure or accounts. Intelligence agencies around the world have their own departments to achieve different cyber goals. From various sources, we know that Russians have bot farms and real people to conduct disinformation. Also, they have departments for offensive operations, examples of such attacks might be SolarWinds incident or Ghostwriter campaign. It's necessary to know their methods to protect yourself and any government departments.
如有侵权请联系:admin#unsafe.sh