作者:蚂蚁安全实验室
原文链接:https://mp.weixin.qq.com/s/CTCGt4GwlIB63lMkAucunA
近日,蚂蚁集团与南洋理工大学、中国科技大学联合论文《APICRAFT: Fuzz Driver Generation for Closed-source SDK Libraries》入选网络安全领域四大顶会之一USENIX Security 2021。
在黑盒的自动化漏洞挖掘过程中,闭源SDK库缺失源代码、API接口未知,而逆向成本高、效果差等问题,常常困扰安全研究者。
基于遗传算法,研究团队的APICraft 框架技术能对闭源SDK的API依赖关系进行最大程度的挖掘和还原,很好地解决了闭源SDK库的fuzz driver自动化生成难题,从而实现在0人工干预下挖掘漏洞。
通过运用这项技术方案,截止2021年2月,蚂蚁安全光年实验室已向Apple提交142个macOS系统库漏洞,并已收获54个Apple官方致谢。
蚂蚁光年安全实验室林性伟也因此获得安全届的奥斯卡大奖—2021年Pwnie Award “Most Innovative Research”奖提名。

以下是他的技术分享
01 背景
在fuzzing过程中,安全研究员需要构建好一个应用程序用来接收fuzzer提供的fuzz input,这个应用程序我们称之为fuzz driver。过往的fuzzing相关研究大多针对于fuzzing引擎本身的优化提升,包括种子变异策略以及调度算法的优化,增加多维度的反馈,以及提升fuzzer速度等,这些研究已经将fuzzing研究变为红海,极其“内卷”。
而我们关注到,如何自动化地构建一个高质量的fuzz driver其实是一个同样关键的问题。直观来看,如果一个fuzz driver能够调用更多SDK提供的API,有更丰富的程序行为,那它在fuzzing过程中必然会有更高的覆盖率,从而更容易触发漏洞。因此如何生成高质量的fuzz driver是个值得深究的研究问题。
这篇文章主要解决了如何针对闭源SDK自动化生成高质量的fuzz driver问题。
1.1 实例

图1是一个构建fuzz driver的例子,以macOS CoreText库为例,图1有两个fuzz drivers,分别是Consumer 1以及Consumer 2,将具体API简化,以伪代码形式来表现(下面的序号标识了每个API调用,与图1相对应):
1.Consumer 1调用ProviderCreateWithData API创建了一个DataProvider对象prov;
2.基于prov对象创建了Font对象font;
3.最后计算出font对象的LeadingSpace的double值。
4.而Consumer 2调用CreateFontDescriptor API创建了FontDescriptor对象desc;
5.再基于desc对象创建Font对象font;
6.最后计算font对象的LeadingSpace值。
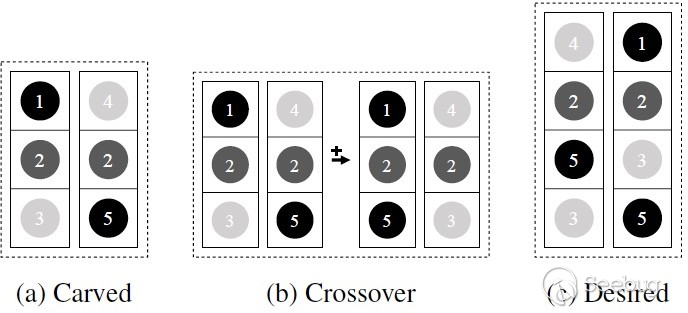
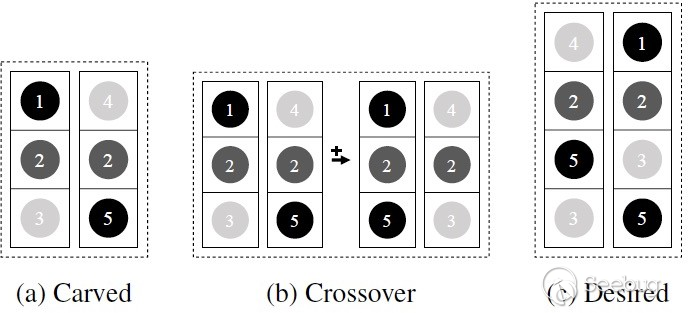
图2是简化出来的API调用序列。(a)是原始的调用序列,(b)是我们将Consumer 1与Consumer 2进行了一个交叉变换,将Consumer 1的序列号1调用与Consumer 2的序列号4调用交换,但我们会发现,这个交叉变换并没有用。因为1与4的调换,只是改变了从raw data创建font对象的方式,并没有改变后续API调用的语义,后续的2->5,2->3都是没有变化的。所以我们其实是想要 (c)这种的组合,将3调用与5调用组合在一起。并且可能由于调用时序的不同会有意想不到的结果。比如先调用3计算LeadingSpace的double值,再调用5计算LeadingSpace可能会导致整数溢出漏洞。
从这个例子来看单纯依赖人工进行fuzz driver 构建耗费时间且容易出(error-prone)。需要一个自动化的框架来辅助完成这个fuzz driver构建过程。
02 系统总览
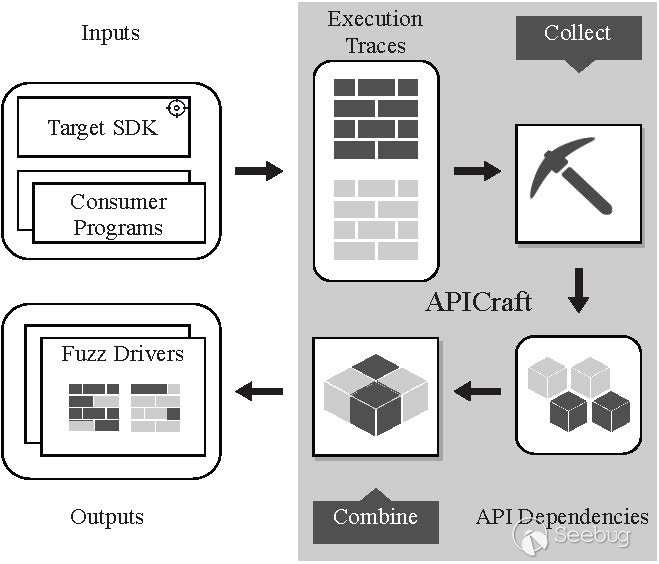
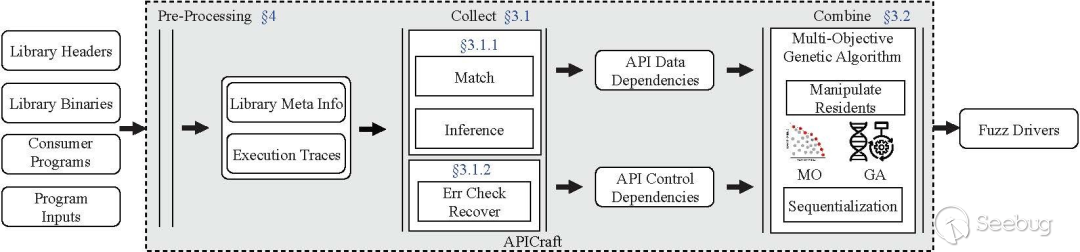
我们设计并实现了APICraft系统用于针对闭源SDK fuzz driver自动化生成工作。图3是整体的系统框架总览。APICraft整体设计思路可以概括为Collect-Combine。
-
Collect:APICraft会对使用相关SDK的GUI应用程序进行动态trace,用于收集GUI应用程序的动态行为信息,包括GUI应用程序调用SDK API的data dependency以及control dependency等。
-
Combine:随后将这些dependency解析好之后进行多目标优化的遗传算法(Multi-Objective genetic algorithm)的变异进化。产生合乎我们要求的fuzz driver。
03 框架设计
框架设计章节将详细介绍APICraft框架的设计与实现细节。
3.1 API Function Dependency信息收集
首先是如何收集(Collect)API function dependency信息。APICraft最终目标是想自动化的完成fuzz driver 构建过程,而人工构建fuzz driver最核心的部分基于SDK提供的API构建API调?序列,API调用序列包含了data dependency以及control dependency。APICraft需要收集data dependency以及control dependency信息,用于作为后续的多目标遗传算法的变异进化的基因/染色体。
3.1.1 Data Dependency
3.1.1.1 定义
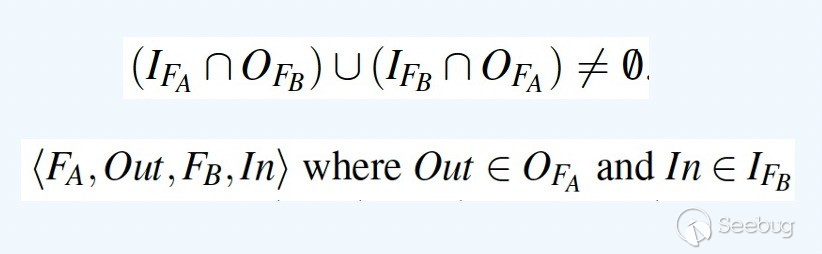
在data dependency中,APICraft定义两个函数A与B有data dependency的关系在于,函数A的某个输入参数是函数B的输出参数/返回值,或者函数B的某个输入参数是函数A的输出参数/返回值。如果函数A与B存在data dependency,以图4的公式来表征,即函数A的输出参数/返回值会被?作函数B的输入参数。
APICraft定义了两类的API Data Dependency:
-
return value:函数A的返回值(return value)被用做函数B的输入参数;
-
output parameter:函数A的输出参数(output paramater,一般是以指针形式存在)被用做函数B的输?参数。
如果两个API函数满足data dependency关系,那这两个API函数就有时序调用关系。
3.1.1.2 解析
当APICraft收集完程序动态行为信息后,需要将信息解析成相应的data dependency。具体的解析步骤是:
-
由图5所示,在预处理阶段,APICraft会通过SDK提供的头文件解析出每个API的参数与返回值的类型信息;
-
而参数与返回值的值是由动态获取到的,APICraft基于function interposition机制实现了一套轻量级的动态trace框架,基于该trace框架,APICraft能够获取到动态运行过程中API函数进入前以及退出之后的参数与返回值信息,具体包括了thread id,nested level,以及会递归的将函数的参数值,返回值,输出参数值dump出来;
-
APICraft基于thread id来将不同线程的trace信息区分开;
-
APICraft会筛掉nested level大于1的API。APICraft针对的API函数都是SDK头文件里面提供的合法调用API。在动态trace过程,如果某个API不是由其他API所调用,即由我们的GUI应用所调用,他的nested level就是1,如果该API是在另外的API所调用的,那他的nested level就是2,以此类推。在fuzz driver生成的应用场景中,我们关注的是API函数如何正确地被GUI应用所调用,而不关注API内部调用的逻辑。APICraft需要演化学习的是GUI应用程序的程序行为逻辑,因此不关注SDK库内部调用的逻辑;
-
区分输出参数:如果一个参数类型是指针,APICraft会监控该指针指向的内容在进API函数前,以及退出API函数之后是否有变化,如果有的话,则该参数会被判别为输出参数;
-
结合类型(type)信息以及值(value)信息进行data dependency匹配:APICraft认为即使在类型信息一致的情况下,两个值为0的比对是不匹配的,因为值为0基本无意义。随后APICraft会将typedef给展开,如果类型不一致,APICraft会看两个比对对象的类型信息是否能够转换,如果(1) 两个比对对象的基本类型是一致的,只是修饰符不一样,比如const这种修饰词;(2)如果是指针类型的话,并且两者指针大小一致,或者对象之一指针是void类型的。上述情形都是可转换的,两个对象可被匹配上。

图6所示算法是APICraft Data Dependency解析算法,输入T是收集到的API函数的调用序列信息,输出R是解析完的data dependency的集合。
1.初始化阶段,R以及cache都将初始化为空;
2.算法会遍历每个函数A,在第8?中,算法会将output值不为0的函数加入cache中,cache是个字典类型,key为output的值,value为函数A的 output实例;
3.在第4行中,算法会遍历函数的每个输入参数(input parameter),用输入参数的值(value)当作key从cache中取出相应的函数的output,看看是否有函数的输入参数与另外函数的output类型与值匹配上的。如果有的话就加到集合R中。
3.1.1.3 Dependency推测
除了通过动态trace收集到的API data dependency关系,有些合理的API data dependency关系并不会被trace到(GUI应用程序没有相应的 API调?组合)。APICraft还会做dependency推测(inference)这一步。APICraft定义了三个推测规则:
1.R1: Dependency-based transition:如果函数A的output与函数C的输入参数相匹配,并且函数B的output与函数C的输入参数相匹配,以及又trace到,函数A的output与函数D的输入参数相匹配, APICraft会推断出,函数B的output跟函数D的输入参数能够相匹配并产生一组data dependency关系;
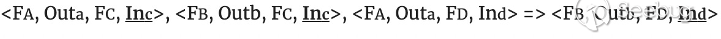
2.R2: Type-based transition:当APICraft观察到函数A的output的类型信息与函数B的输?参数类型信息一致,这个时候APICraft会做个推测,因为这个没有值(value)信息,所以是个推测,推测出函数A的 output是函数B的输入参数;
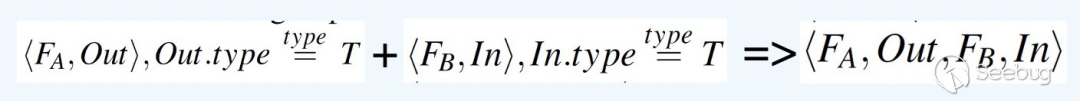
3.R3: Inter-thread data flow dependency:R3与图6的算法是一致的,只不过在这个规则下,会限定类型是指针,一般跨线程之间会传递指针,需要减少误报。
3.1.2 Control Dependency
APICraft收集到的Control Dependency主要是用来解决error code checking的:
1.API函数的输出参数(output parameter)或者返回值(return value)是指针类型,将对这个output值 进行非空判断(null check);
2.API函数的输出参数(output parameter)或者返回值(return value)是整数类型,并且是个status code的话,将进行动态污点分析来获取error code checking分支的表达式。(1)获取这个API函数的调用处(callsite);(2)通过静态分析找到一些error code checking的系统调用,比如exit,abort 等。这些basic block会被标记为checkpoint。(3)最后从调用处(callsite)开始进行taint analysis,因为正常的GUI应用程序会走正常分支,当走到checkpoint相应分支的时候将表达式取反, 让污点分析传播到checkpoint处。拿到对应的表达式。
3.2 Dependency Combination
APICraft将收集并解析完成的data dependency以及control denpendency进行Combination,再通过多目标优化遗传算法进行变异演化。
3.2.1 问题建模
APICraft将fuzz driver生成问题抽象成一个数学问题,利用多目标优化遗传算法(Multi-Objective Genetic Algorithm)进行求解。
具体而言,以GUI应用程序(调用相应 SDK提供的 API)的API函数使用方式为初始种群,对这些种群进行变异演化生成fuzz driver,通过判断生成的fuzz driver的优劣,将优越fuzz driver保留下来继续变异,最后生成满足要求的fuzz driver 用于fuzzing。我们认为?个高质量的fuzz driver需要满足三个目标:
1.多样性(Diversity):多样性(Diversity)指的是fuzz driver能够调用足够多样的API使fuzz driver程序行为更丰富。即为了让生成出来的fuzz driver有更多不同的data dependencies,如果data dependencies能够组成loop,每条loop都会给这个目标加分数。图9所示的多样性(Diversity)的公式是生成的fuzz driver的有向多边图的边(即单个data dependency)的数量,加上这个图的圈复杂度。总体是要表征data dependency图(或者说fuzz driver的API调用)的多样性。

2.有效性(Effectiveness):有效性(Effectiveness)是这三个指标中的唯一一个需要动态反馈信息的指标,其目标是要让生成的fuzz driver的API调用更合法有效。我们会给basic blocks中有调用其他函数的,以及这个basic block处于loop循环中的更多分数,因为我们觉得相对于核心代码而言error handling code在一个API函数中会执行更少的basic blocks,而核心代码会有更多的loop信息或者其 他函数调用。该指标是个动态的feedback,是需要将fuzz driver序列化成代码编译运行后得来的,我们对每个basic block评分(如图10所示):(1)调用其余函数以及处于loop循环中,评分3分;(2)调用其余函数或者处于loop循环中,2分;(3)两者均无则1分。

3.紧凑性(Compactness):core dependency指的是从接收input file的API函数为起点,以此为根结点的展开的data dependency图。non-core dependency就是与这颗树无关的data dependency。F是core function(处于 core dependency中的函数)集合,f是集合里面的每个函数,If是每个函数的参数集合。k是每个input参数的无关函数数量,5是个经验值(即如果无关函数数量超过5,则该紧凑性(Compactness)指标得分为0)。
紧凑性(Compactness)指标目的是为了让fuzz driver去除冗余API调用,冗余API调用就是跟以接收input file API为起点的data dependency 图无关的API调用,即存在于non-core dependency图中的API调用。所以在core dependency的data dependency分数会高,non-core dependency中的data dependency分数会低。图11是Compactness的具体公式。

3.2.2 多目标优化遗传算法(Multi-Objective Genetic Algorithm)
APICraft采用了NSGA-II算法来对Diversity、Effectiveness、Compactness这三个目标进行多目标优化的遗传算法演进。
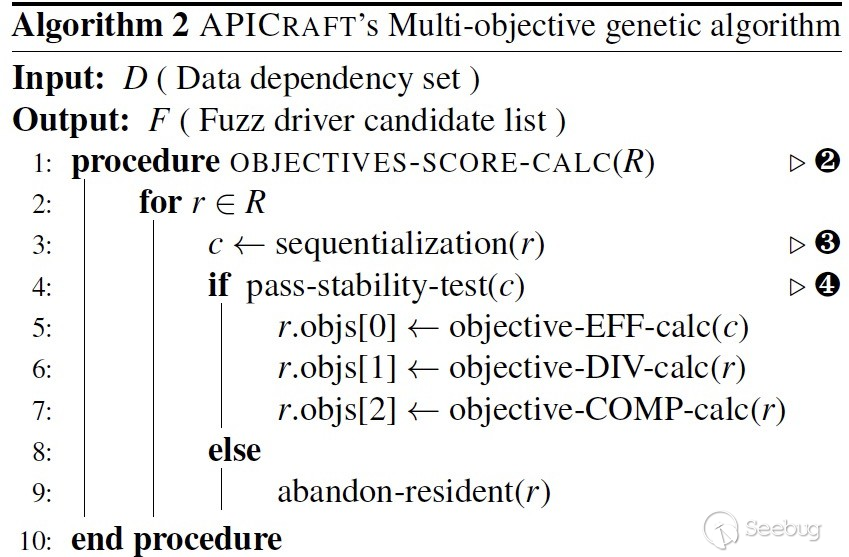
图12是整体的APICraft的多目标优化遗传算法,输入data dependency集合,输出是一系列的fuzz driver集合:
-
25-31行即传统的遗传算法,先生成初始的种子集,选取初始种子集,然后开始变异,再选择存活下来的个体,继续变异,往复。直到到了我们限定的变异轮数。28行进行变异,29行选取最优个体;
-
17-23行选取两个种?进?交叉变异;
-
11-16行对交叉变异后的种?进行多目标优化的评分计算,然后筛出最优个体。12行计算目标评分,13行进行非支配排序算法,进行分层。14行计算拥挤度与拥挤度比较算子。15行筛选出来最优个体;
-
1-10行就是对个体先进行序列化后,计算三个目标的分值。

04 实现
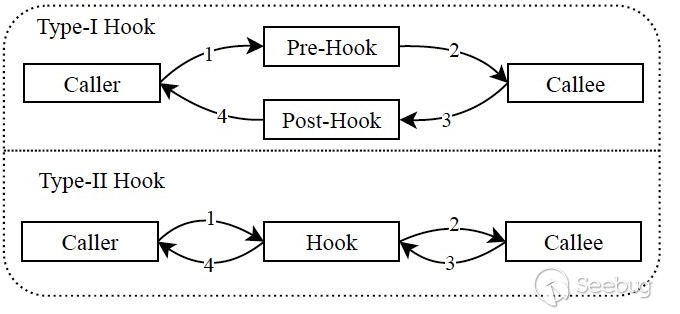
APICraft工程实现中核心之一是动态trace功能,动态trace是为了获取API函数的参数以及返回值。如图13所示,在hook中有两种机制:
1.Type-I需要两个hook点,函数的enter point以及exit point,enter point容易分析,但函数的exit point无法准确判断,因为一个函数可能会有多个exit点,单纯通过判断ret指令是无法精确判断exit点的,特别是当二进制程序被高度编译优化过。错误的exit点的hook机制会导致后续收集的nested level等信息都有误;
2.Type-II则没有这个问题,基于interposition的机制是中间有个媒介层在进行函数前接管,在退出函数之后也接管。我们就能准确拿到参数值以及返回值。Interposition机制的核心是会有一个跟被hook函数相同函数签名的替换函数,然后基于这个替换函数接管原函数的信息之后再调用原函数。在macOS上 APICraft用DYLD_PRELOAD跟DYLD_INTERPOSE机制来实现,在Windows上我们用的是detour来实现。
05 实验结果
5.1 多目标优化遗传算法
我们一共对5个攻击面进行了漏洞挖掘,包含了Image,Font,PDF,Audio,RTF,这里用Image这个攻击面来看看我们算法的实验效果,其他攻击面实验效果可查阅论文。
-
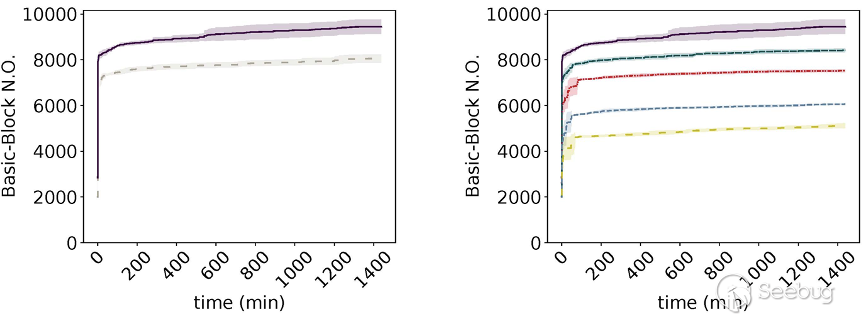
图14左图是经过多目标遗传算法生成的fuzz driver跟人工写的fuzz driver在fuzzing过程中覆盖率比对。紫色的线是APICraft生成的fuzz driver,浅色线是Google Project Zero的安全研究员手写的fuzz driver,这个fuzz driver是研究员在对攻击面熟悉,并且通过逆向构建出来的fuzz driver。实验来看, 通过APICraft产生的fuzz driver在fuzzing过程中的覆盖率仍比P0顶尖安全研究员手写的fuzz driver实验效果卓越;
-
图14右图是三个目标(Diversity、Effectiveness、Compactness)都结合起来生成的fuzz driver跟去掉每一个单一目标而生成的fuzz driver比对,比如绿色这条线是去掉多样性(Diversity)的覆盖率,去掉每个单一目标的实验效果没有三个目标都结合起来生成的fuzz driver在fuzzing过程中的实验效果好。
5.2 漏洞挖掘产出
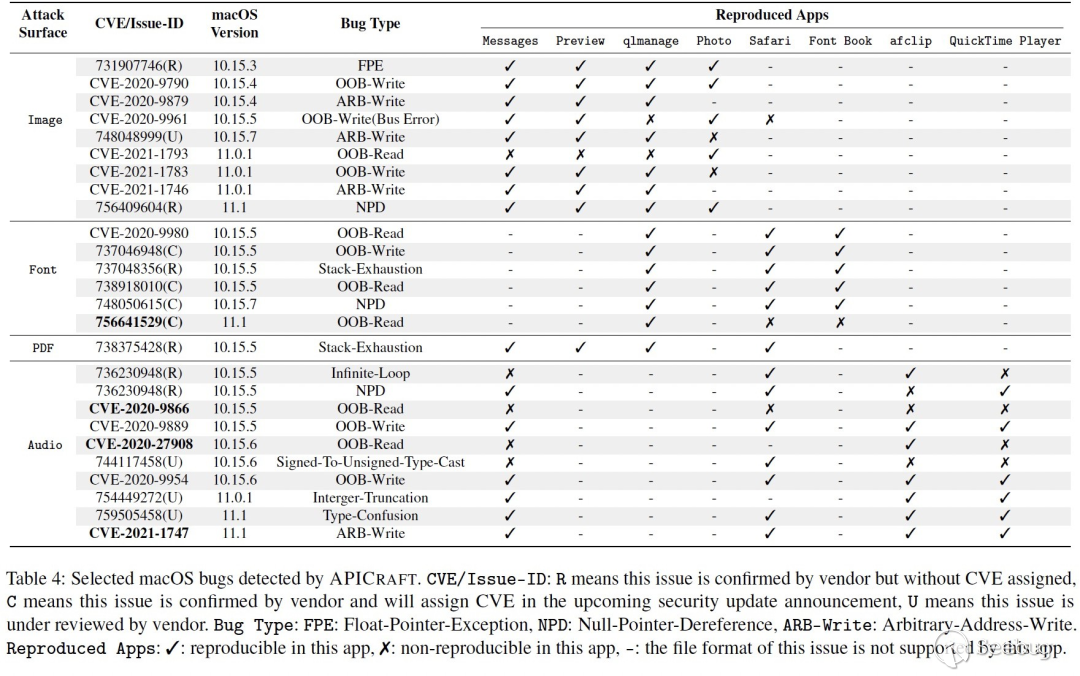
基于APICraft生成的fuzz driver,我们进行了长达8个月的fuzzing。最终在macOS系统库5个攻击面上发现了142处漏洞,收到Apple 54个官方漏洞致谢(该数据统计截止5到论?投稿时,2021年2月)。
图15节选了一些漏洞,每一列分别是攻击面(Attack Surface),获取到的CVE号或者 Issue-ID,macOS的复现版本,漏洞类型,已经能在哪些 APP上上复现这些bug。
06 总结
APICraft基于function interposition技术实现了轻量级的GUI应用程序动态行为收集框架,以及基于NSGA—II多目标优化遗传算法实现的fuzz driver自动化生成框架。基于APICraft框架生成的fuzz driver在fuzzing过程中帮助我们挖掘到了macOS系统库142处漏洞,共收获Apple 54个官方漏洞致谢。
APICraft项目主页链接为:https://sites.google.com/view/0xlib-harness 我们将在Usenix Security 2021会议完成之后开源代码。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1706/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1706/
如有侵权请联系:admin#unsafe.sh