
We’re currently working on making Go binaries easier to understand using our ultra-fast Carbon disassembler. In the upcoming weeks we’ll keep on posting progress updates.
In the previous part we focused on resolving function names. In this part we focus on resolving strings literals.
Let’s take the following decompiler output for a Go function:
void __stdcall sub_47D590(void)
{
uint32_t *puVar1;
int32_t in_FS_OFFSET;
unk32_t uStack8;
unk32_t uStack4;
while (puVar1 = (uint32_t *)(**(int32_t **)(in_FS_OFFSET + 0x14) + 8),
*(BADSPACEBASE **)0x10 < (unk8_t *)*puVar1 ||
(unk8_t *)*(BADSPACEBASE **)0x10 == (unk8_t *)*puVar1) {
uStack4 = 0x47D638;
sub_446900();
}
sub_44B9D0("syntax error scanning complex numberuncaching span but s.allocCount == 0) is smaller than minimum pa", 0x24);
*(unk32_t *)0x532DC8 = uStack8;
if (*(int32_t *)0x542C70 == 0) {
*(unk32_t *)0x532DCC = uStack4;
}
else {
sub_448050();
}
sub_44B9D0("syntax error scanning booleantimeBegin/EndPeriod not foundtoo many open files in systemtraceback has", 0x1D);
*(unk32_t *)0x532DC0 = uStack8;
if (*(int32_t *)0x542C70 == 0) {
*(unk32_t *)0x532DC4 = uStack4;
}
else {
sub_448050();
}
return;
}
It lacks function names and although referenced strings are visible thanks to the heuristics implemented in our decompiler, the size of the strings is incorrect, as the strings are not null-terminated.
By correctly resolving the Go strings, we obtain an improved output:
void __stdcall fmt.init.ializers(void)
{
uint32_t *puVar1;
int32_t in_FS_OFFSET;
unk32_t uStack8;
unk8_t *puStack4;
while (puVar1 = (uint32_t *)(**(int32_t **)(in_FS_OFFSET + 0x14) + 8),
*(BADSPACEBASE **)0x10 < (unk8_t *)*puVar1 ||
(unk8_t *)*(BADSPACEBASE **)0x10 == (unk8_t *)*puVar1) {
puStack4 = &fmt.init.ializers;
runtime.morestack_noctxt();
}
errors.New("syntax error scanning complex number", 0x24);
*(unk32_t *)0x532DC8 = uStack8;
if (*(int32_t *)0x542C70 == 0) {
*(unk8_t **)0x532DCC = puStack4;
}
else {
runtime.gcWriteBarrier();
}
errors.New("syntax error scanning boolean", 0x1D);
*(unk32_t *)0x532DC0 = uStack8;
if (*(int32_t *)0x542C70 == 0) {
*(unk8_t **)0x532DC4 = puStack4;
}
else {
runtime.gcWriteBarrier();
}
return;
The same is true for our initial hello world example:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
The original decompiler output would be:
void __stdcall sub_47D7B0(void)
{
uint32_t *puVar1;
int32_t in_FS_OFFSET;
unk32_t uStack8;
unk32_t uStack4;
while (puVar1 = (uint32_t *)(**(int32_t **)(in_FS_OFFSET + 0x14) + 8),
*(BADSPACEBASE **)0x10 < (unk8_t *)*puVar1 ||
(unk8_t *)*(BADSPACEBASE **)0x10 == (unk8_t *)*puVar1) {
uStack4 = 0x47D823;
sub_446900();
}
uStack8 = 0x491320;
uStack4 = &"Hello, World!MapViewOfFileMasaram_GondiMende_KikakuiOld_HungarianRegDeleteKeyWRegEnumKeyExWRegEnumVa";
sub_478270(0x4BCEC0, *(unk32_t *)0x532A8C, &uStack8, 1, 1);
return;
}
While the newly introduced feature of our decompiler already detects the indirect string literal reference, again the size of the string is wrong.
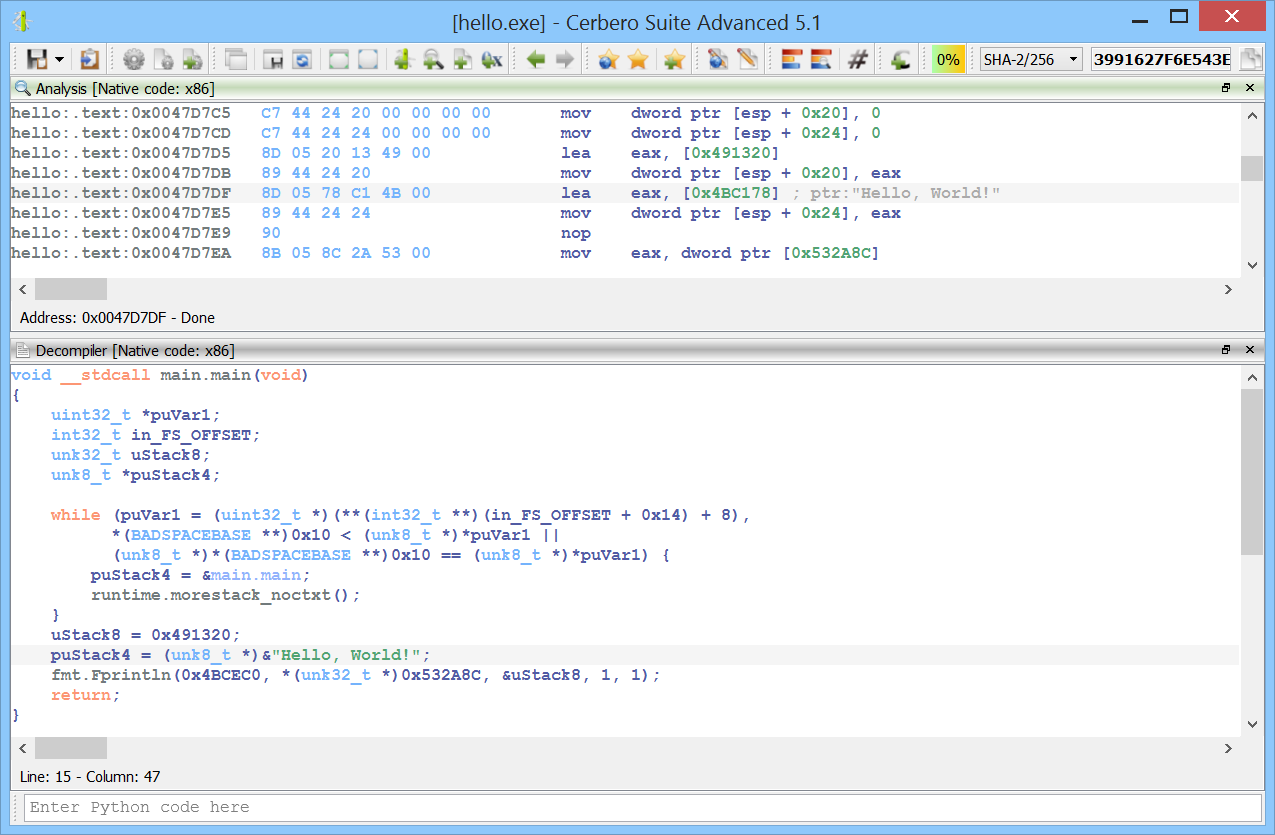
The improved decompiler output is:
void __stdcall main.main(void)
{
uint32_t *puVar1;
int32_t in_FS_OFFSET;
unk32_t uStack8;
unk8_t *puStack4;
while (puVar1 = (uint32_t *)(**(int32_t **)(in_FS_OFFSET + 0x14) + 8),
*(BADSPACEBASE **)0x10 < (unk8_t *)*puVar1 ||
(unk8_t *)*(BADSPACEBASE **)0x10 == (unk8_t *)*puVar1) {
puStack4 = &main.main;
runtime.morestack_noctxt();
}
uStack8 = 0x491320;
puStack4 = (unk8_t *)&"Hello, World!";
fmt.Fprintln(0x4BCEC0, *(unk32_t *)0x532A8C, &uStack8, 1, 1);
return;
}
While it’s still far from being easy to read, it’s definitely easier to read than before.
To be continued…