2019-08-30 15:01:00 Author: paper.seebug.org(查看原文) 阅读量:256 收藏
Author: Badcode@Knownsec 404 Team
Date: 2019/08/29
Chinese Version: https://paper.seebug.org/1025/
1 Foreword
In the afternoon @fnmsd sent me a Confluence warning. I studied this patch, recurred the vulnerability and recorded the process of the emergency.
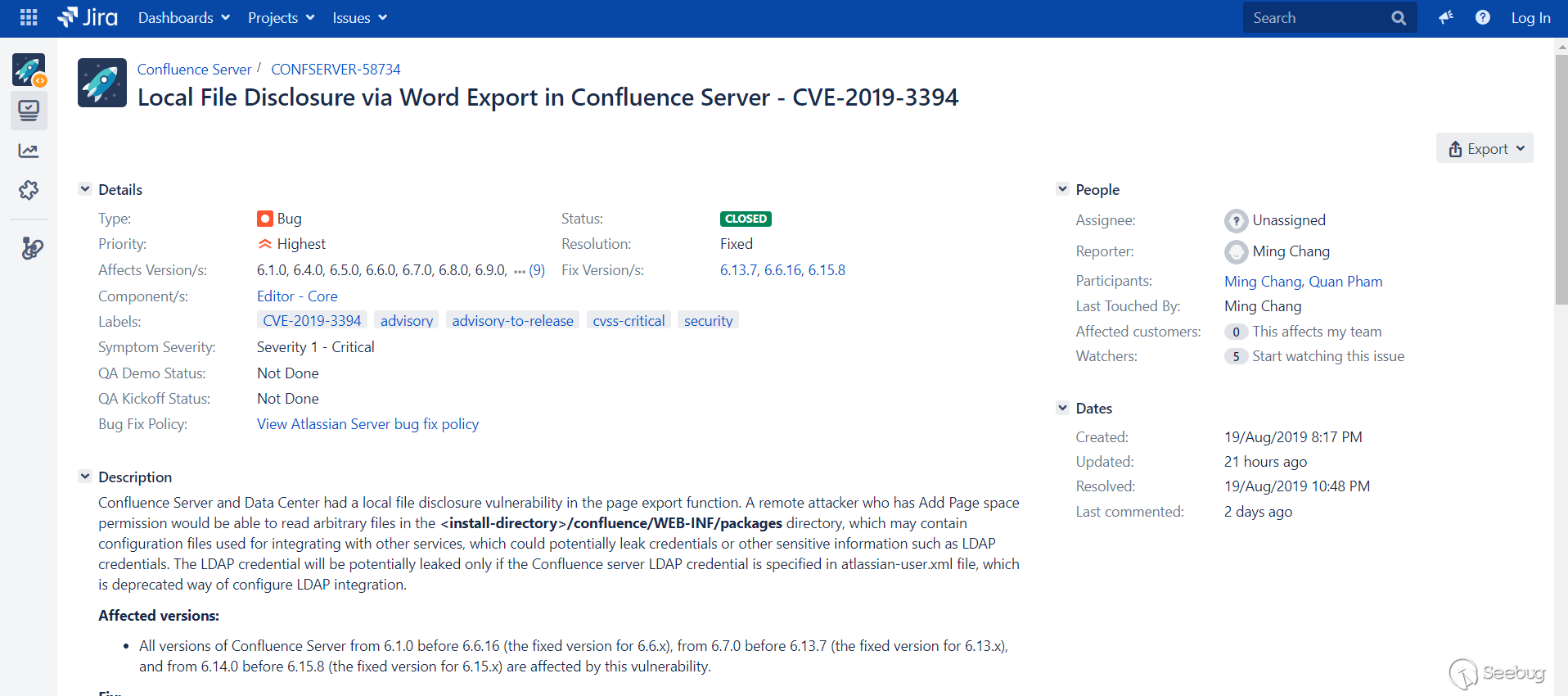
As the description says, Confluence Server and Data Center had a local file disclosure vulnerability in the page export function. A remote attacker who has Add Page space permission would be able to read arbitrary files in the
2 Vulnerability Impact
- 6.1.0 <= version < 6.6.16
- 6.7.0 <= version < 6.13.7
- 6.14.0 <= version < 6.15.8
3 Patch Comparison
According to the description, the trigger is at the Word export operation.
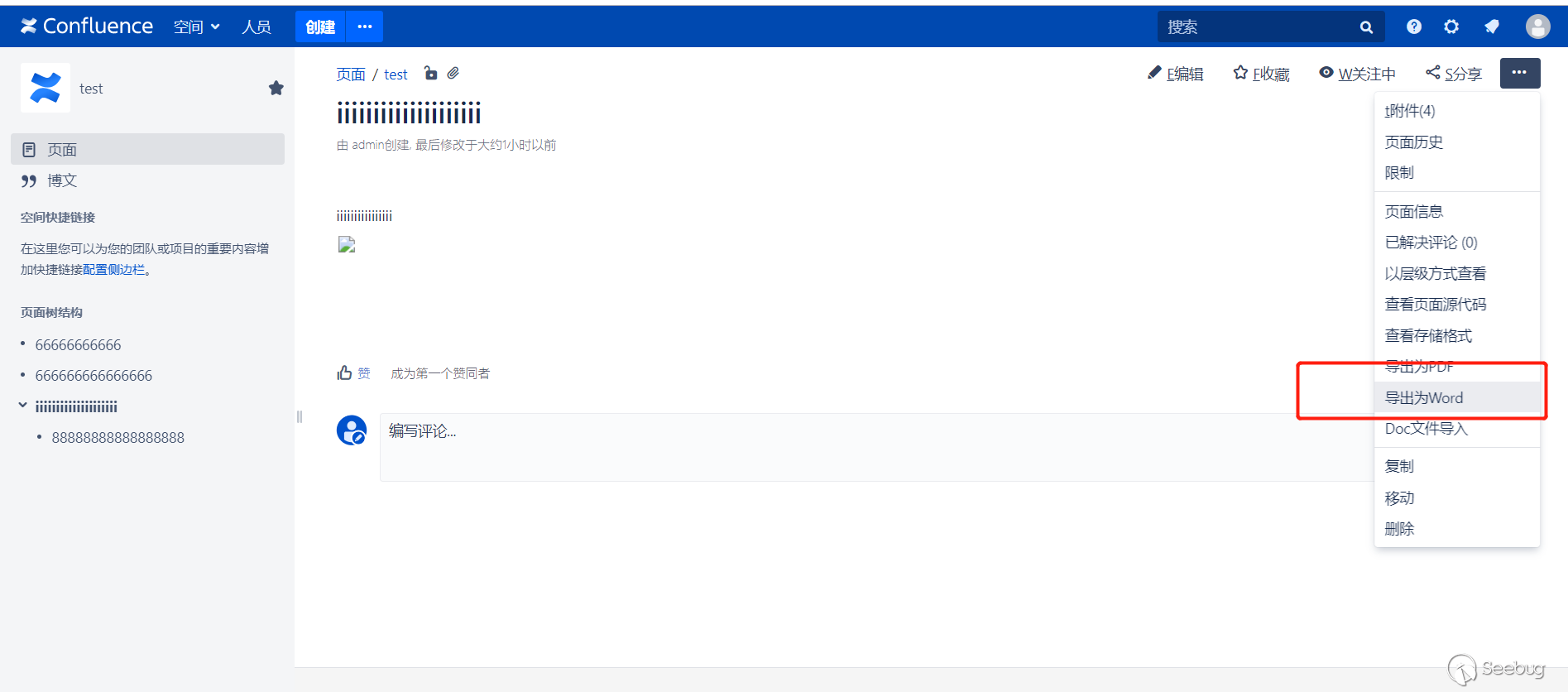
Look at the code to see where the patch is.
I downloaded 6.13.6 and 6.13.7 for comparison.
Let's focus on confluence-6.13.x.jar.
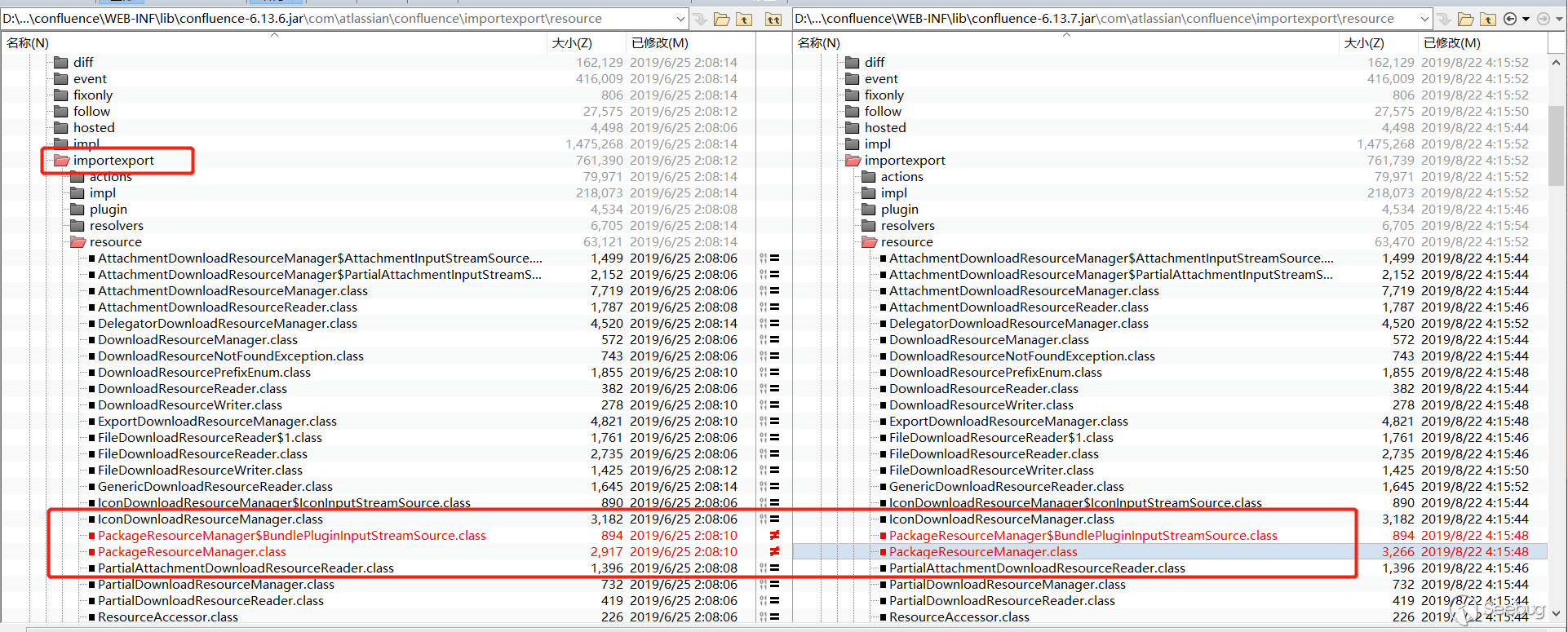
Comparing these two jars, I saw that there is a change in the importexport directory. Combined with the previous description which said the vulnerability is in the page export function, the patch is probably here. There is a change in the PackageResourceManager in the importexport directory.
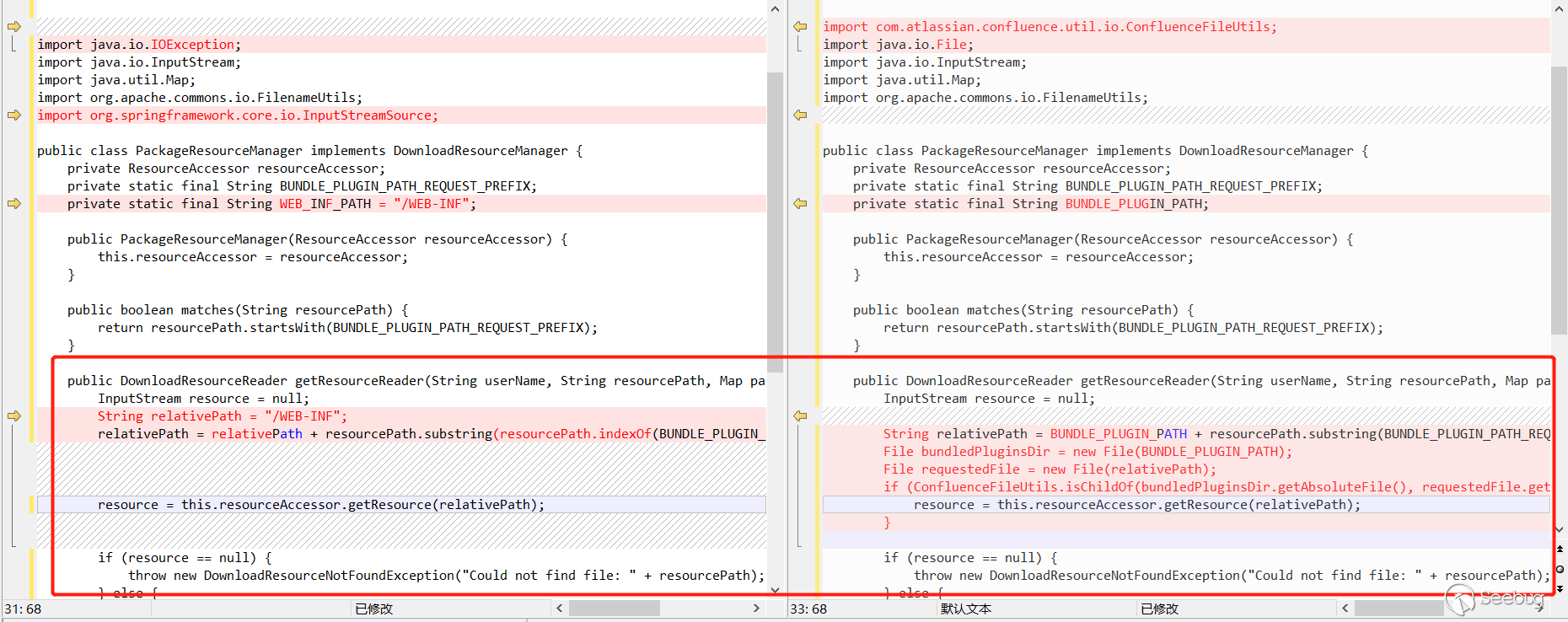
See the key function getResourceReader, resource = this.resourceAccessor.getResource(relativePath);. It seems to get the file resource, the value of relativePath is /WEB-INF splicing resourcePath.substring(resourcePath. indexOf(BUNDLE_PLUGIN_PATH_REQUEST_PREFIX)) , and resourcePath is passed in. It is obvious that resourcePath is controllable. It splices /WEB-INF, then call getResource to read the file.
4 Process Analysis
The next step is to find the path of the trigger. I tried to insert various things on the page, then exported Word, tried to jump to this place, and all failed. Finally, when I tracked the inserted image, I found that I jumped to a similar place, and finally jumped to the trigger by constructing the image link.
First see the service method of com.atlassian.confluence.servlet.ExportWordPageServer.
public void service(SpringManagedServlet springManagedServlet, HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String pageIdParameter = request.getParameter("pageId");
Long pageId = null;
if (pageIdParameter != null) {
try {
pageId = Long.parseLong(pageIdParameter);
} catch (NumberFormatException var7) {
response.sendError(404, "Page not found: " + pageId);
}
} else {
response.sendError(404, "A valid page id was not specified");
}
if (pageId != null) {
AbstractPage page = this.pageManager.getAbstractPage(pageId);
if (this.permissionManager.hasPermission(AuthenticatedUserThreadLocal.get(), Permission.VIEW, page)) {
if (page != null && page.isCurrent()) {
this.outputWordDocument(page, request, response);
} else {
response.sendError(404);
}
......
}When exporting Word, it first get the pageId of the exported page, then get the content of the page, determine whether there is permission for viewing and follow up this.outputWordDocument
private void outputWordDocument(AbstractPage page, HttpServletRequest request, HttpServletResponse response) throws IOException {
......
try {
ServletActionContext.setRequest(request);
ServletActionContext.setResponse(response);
String renderedContent = this.viewBodyTypeAwareRenderer.render(page, new DefaultConversionContext(context));
Map<String, DataSource> imagesToDatasourceMap = this.extractImagesFromPage(renderedContent);
renderedContent = this.transformRenderedContent(imagesToDatasourceMap, renderedContent);
Map<String, Object> paramMap = new HashMap();
paramMap.put("bootstrapManager", this.bootstrapManager);
paramMap.put("page", page);
paramMap.put("pixelsPerInch", 72);
paramMap.put("renderedPageContent", new HtmlFragment(renderedContent));
String renderedTemplate = VelocityUtils.getRenderedTemplate("/pages/exportword.vm", paramMap);
MimeMessage mhtmlOutput = this.constructMimeMessage(renderedTemplate, imagesToDatasourceMap.values());
mhtmlOutput.writeTo(response.getOutputStream());
......There will be some headers in the front, and then the content of the page willget rendered. Then it will return renderedContent, and hand it to this.extractImagesFromPage
private Map<String, DataSource> extractImagesFromPage(String renderedHtml) throws XMLStreamException, XhtmlException {
Map<String, DataSource> imagesToDatasourceMap = new HashMap();
Iterator var3 = this.excerpter.extractImageSrc(renderedHtml, MAX_EMBEDDED_IMAGES).iterator();
while(var3.hasNext()) {
String imgSrc = (String)var3.next();
try {
if (!imagesToDatasourceMap.containsKey(imgSrc)) {
InputStream inputStream = this.createInputStreamFromRelativeUrl(imgSrc);
if (inputStream != null) {
ByteArrayDataSource datasource = new ByteArrayDataSource(inputStream, this.mimetypesFileTypeMap.getContentType(imgSrc));
datasource.setName(DigestUtils.md5Hex(imgSrc));
imagesToDatasourceMap.put(imgSrc, datasource);
......The function extracts the image in the page. When the exported page contains images, the link of the image is extracted and submitted to this.createInputStreamFromRelativeUrl.
private InputStream createInputStreamFromRelativeUrl(String uri) {
if (uri.startsWith("file:")) {
return null;
} else {
Matcher matcher = RESOURCE_PATH_PATTERN.matcher(uri);
String relativeUri = matcher.replaceFirst("/");
String decodedUri = relativeUri;
try {
decodedUri = URLDecoder.decode(relativeUri, "UTF8");
} catch (UnsupportedEncodingException var9) {
log.error("Can't decode uri " + uri, var9);
}
if (this.pluginResourceLocator.matches(decodedUri)) {
Map<String, String> queryParams = UrlUtil.getQueryParameters(decodedUri);
decodedUri = this.stripQueryString(decodedUri);
DownloadableResource resource = this.pluginResourceLocator.getDownloadableResource(decodedUri, queryParams);
try {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
resource.streamResource(outputStream);
return new ByteArrayInputStream(outputStream.toByteArray());
} catch (DownloadException var11) {
log.error("Unable to serve plugin resource to word export : uri " + uri, var11);
}
} else if (this.downloadResourceManager.matches(decodedUri)) {
String userName = AuthenticatedUserThreadLocal.getUsername();
String strippedUri = this.stripQueryString(decodedUri);
DownloadResourceReader downloadResourceReader = this.getResourceReader(decodedUri, userName, strippedUri);
if (downloadResourceReader == null) {
strippedUri = this.stripQueryString(relativeUri);
downloadResourceReader = this.getResourceReader(relativeUri, userName, strippedUri);
}
if (downloadResourceReader != null) {
try {
return downloadResourceReader.getStreamForReading();
} catch (Exception var10) {
log.warn("Could not retrieve image resource {} during Confluence word export :{}", decodedUri, var10.getMessage());
if (log.isDebugEnabled()) {
log.warn("Could not retrieve image resource " + decodedUri + " during Confluence word export :" + var10.getMessage(), var10);
}
}
}
} else if (uri.startsWith("data:")) {
return this.streamDataUrl(uri);
}
.....This function is to get the image resources, and will handle different image links in different formats. We should look at this.downloadResourceManager.matches(decodedUri). The this.downloadResourceManager is DelegatorDownloadResourceManager, and there are 6 downloadResourceManager below. Among them is the PackageResourceManager we want.
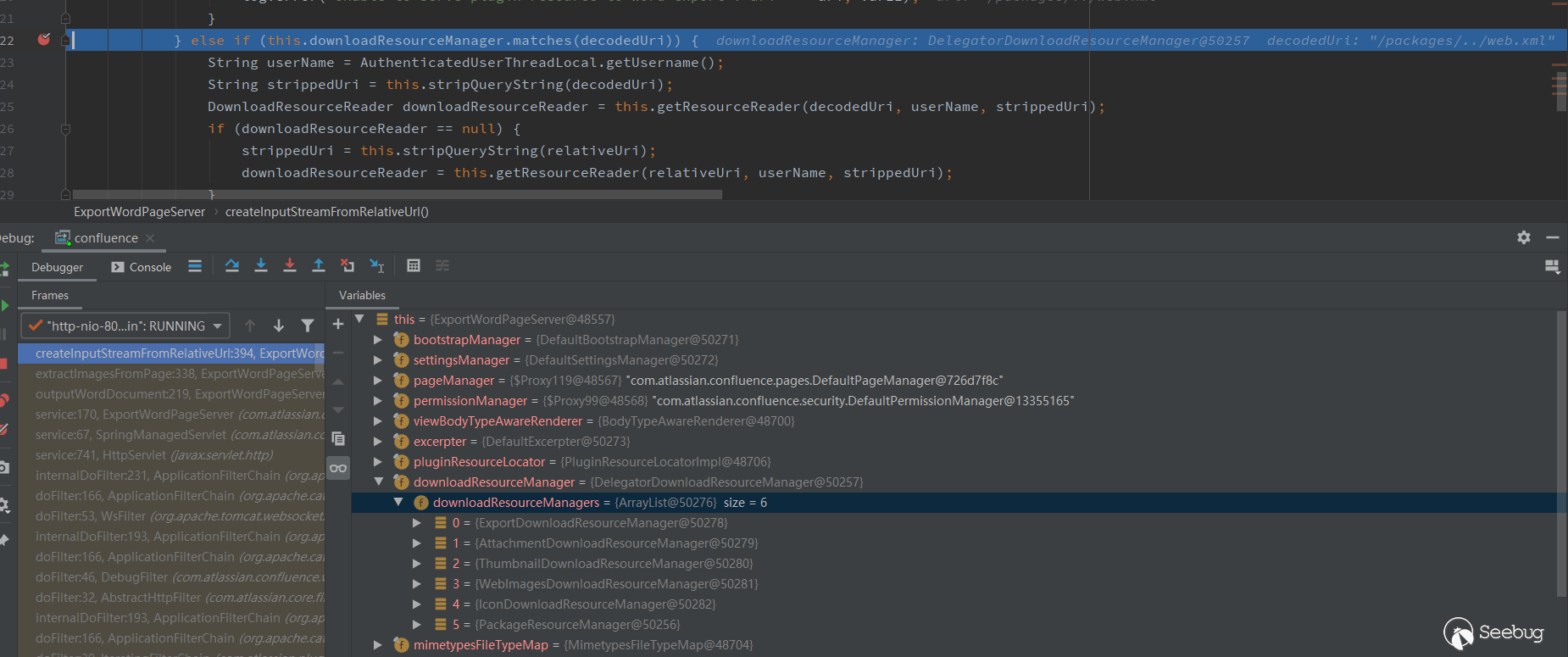
Follow the matches method of DelegatorDownloadResourceManager.
public boolean matches(String resourcePath) {
return !this.managersForResource(resourcePath).isEmpty();
}
......
private List<DownloadResourceManager> managersForResource(String resourcePath) {
return (List)this.downloadResourceManagers.stream().filter((manager) -> {
return manager.matches(resourcePath) || manager.matches(resourcePath.toLowerCase());
}).collect(Collectors.toList());
}The matches method will call the managersForResource method, calling the matches method of each downloadResourceManager to match resourcePath, and return true if there is a downloadResourceManager that matches. Look at the matches method of PackageResourceManager
public PackageResourceManager(ResourceAccessor resourceAccessor) {
this.resourceAccessor = resourceAccessor;
}
public boolean matches(String resourcePath) {
return resourcePath.startsWith(BUNDLE_PLUGIN_PATH_REQUEST_PREFIX);
}
static {
BUNDLE_PLUGIN_PATH_REQUEST_PREFIX = DownloadResourcePrefixEnum.PACKAGE_DOWNLOAD_RESOURCE_PREFIX.getPrefix();
}resourcePath returns true when it starts with BUNDLE_PLUGIN_PATH_REQUEST_PREFIX. BUNDLE_PLUGIN_PATH_REQUEST_PREFIX is PACKAGE_DOWNLOAD_RESOURCE_PREFIX in DownloadResourcePrefixEnum, and is also called /packages.
public enum DownloadResourcePrefixEnum {
ATTACHMENT_DOWNLOAD_RESOURCE_PREFIX("/download/attachments"),
THUMBNAIL_DOWNLOAD_RESOURCE_PREFIX("/download/thumbnails"),
ICON_DOWNLOAD_RESOURCE_PREFIX("/images/icons"),
PACKAGE_DOWNLOAD_RESOURCE_PREFIX("/packages");Therefore, resourcePath will return true when it starts with the /packages.
Back to createInputStreamFromRelativeUrl method. When downloadResourceManager matches decodedUri, it will enter the branch. Continue to call DownloadResourceReader downloadResourceReader = this.getResourceReader(decodedUri, userName, strippedUri);
private DownloadResourceReader getResourceReader(String uri, String userName, String strippedUri) {
DownloadResourceReader downloadResourceReader = null;
try {
downloadResourceReader = this.downloadResourceManager.getResourceReader(userName, strippedUri, UrlUtil.getQueryParameters(uri));
} catch (UnauthorizedDownloadResourceException var6) {
log.debug("Not authorized to download resource " + uri, var6);
} catch (DownloadResourceNotFoundException var7) {
log.debug("No resource found for url " + uri, var7);
}
return downloadResourceReader;
}Jump to getResourceReader in DelegatorDownloadResourceManager
public DownloadResourceReader getResourceReader(String userName, String resourcePath, Map parameters) throws DownloadResourceNotFoundException, UnauthorizedDownloadResourceException {
List<DownloadResourceManager> matchedManagers = this.managersForResource(resourcePath);
return matchedManagers.isEmpty() ? null : ((DownloadResourceManager)matchedManagers.get(0)).getResourceReader(userName, resourcePath, parameters);
}Here we will continue to call managersForResource to call the matches method of each downloadResourceManager to match resourcePath. If there is a match, we will continue to call the getResourceReader method of the corresponding downloadResourceManager. So, if matches method in PackageResourceManager can match resourcePath, then we will continue to call the getResourceReader method in PackageResourceManager, which is the vulnerability. To get here, resourcePath must start with /packages.
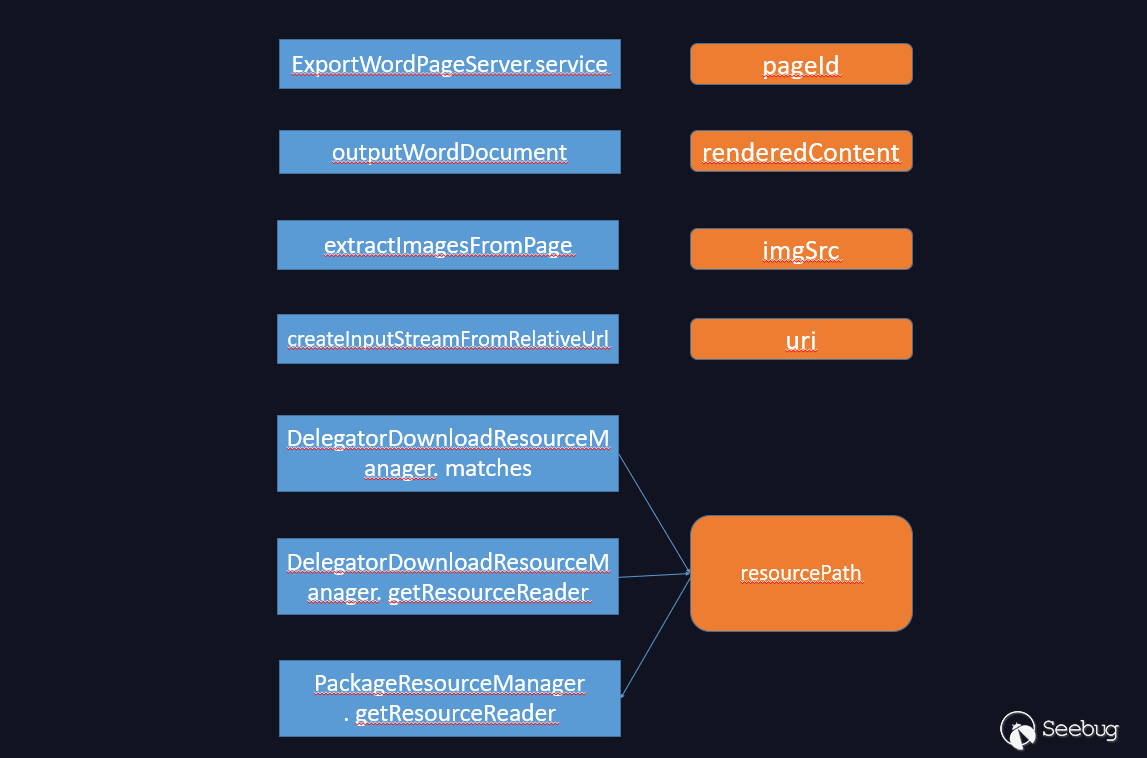
The entire flow chart is as follows.
5 Construction
The process is clear, and now it's about how to construct it. We are going to insert a picture with a link starting with /packages.
Create a new page and insert a web image.
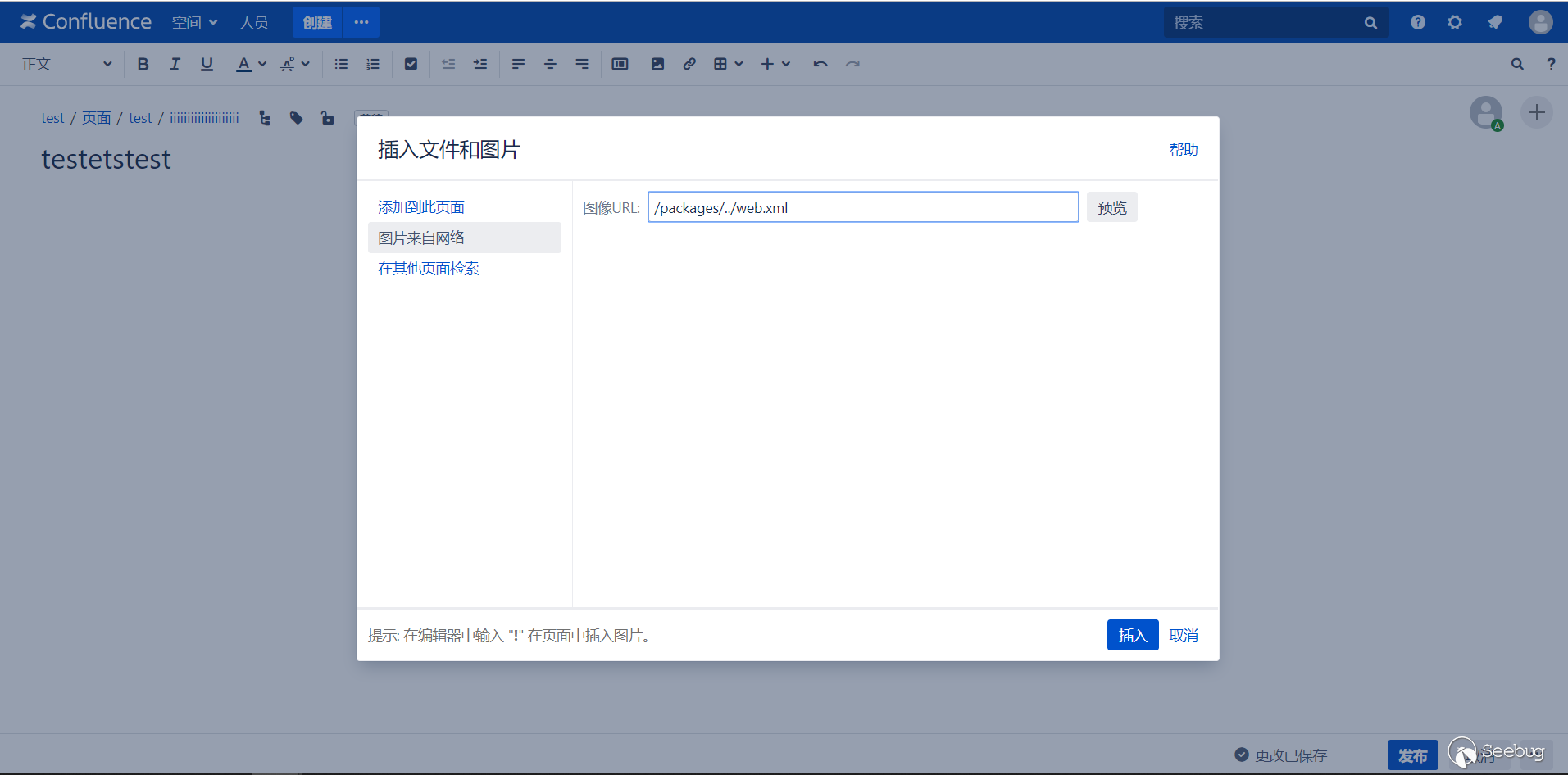
It can not be saved directly, cause if you do so, the inserted image link will be automatically spliced to the website address, so use the burpsuite to remove the automatically spliced website address when saving.
Capture the package when releasing.
Remove URL.

After the release, you can see that the image link was successfully saved.
Finally, click Export Word to trigger the vulnerability. After successfully reading the data, it will be saved to the image and then placed in the Word document. Since it cannot be displayed properly, I use burp to check the returned data.
The contents of /WEB-INF/web.xml have been successfully read.
6 What's More
This vulnerability is unable to jump out of the web directory to read the file. getResourcemethod will finally be transferred to org.apache.catalina.webresources.StandardRoot. There is a validate function in it and it has restrictions and filtration that prevent you from jumping to the upper directory of /WEB-INF/.
This video demonstrates the vulnerability with Pocsuite3:
7 Reference
Local File Disclosure via Word Export in Confluence Server - CVE-2019-3394
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1026/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1026/
如有侵权请联系:admin#unsafe.sh