2021-11-10 11:0:0 Author: ricercasecurity.blogspot.com(查看原文) 阅读量:25 收藏
Japanese version is here.
Written by:
Introduction
At Ricerca Security, we are currently working on fuzzing and its development. Today, we released the AFL++ CoreSight mode in public as a part of our study. This project adds a new feedback mechanism using CoreSight (a CPU feature available on some ARM-based processors) to the standard fuzzing tool, AFL++.
Generally, fuzzing without source code (binary-only fuzzing) requires instrumentation to target binaries. The AFL++ CoreSight mode enables more performant binary-only fuzzing by employing CoreSight for instrumentation.
The AFL++ CoreSight mode is available on:
In this blog post, we describe the AFL++ CoreSight mode and background.
Binary-only Fuzzing on ARM
Coverage-guided fuzzing is the most common method used by industry-standard fuzzing tools such as American Fuzzy Lop (AFL) and its well-known fork AFL++. It searches for inputs given to the program under test (PUT) to find new branch transitions using code coverage as feedback.
If the PUT source code is available, fuzzing tools can instrument the code for feedback generation at the build time. In the case where the source code is not available (binary-only fuzzing), they require a binary instrumentation tool or binary rewriting tool to instrument the target binaries. Although we can obtain better results than the binary-only fuzzing if the source code is available, binary-only fuzzing is more practical because most proprietary software or firmware do not provide the source code.
Instrumentations for binary-only fuzzing are categorized into static and dynamic instrumentation as shown in Figure 1. Static instrumentations statically rewrite target binaries to patch PUTs using static rewriting tools, such as e9patch. Dynamic instrumentation inserts the code for generating feedback into the PUTs at run time. One example of this instrumentation type is the de facto standard binary-only fuzzing tool AFL++ QEMU mode. Static instrumentation does not support the ARM architecture, and dynamic instrumentation has a performance issue. Therefore, we have ended up relying on slow QEMU-based instrumentation for ARM binary-only fuzzing.
 |
| Figure 1. Static and dynamic types of fuzzing instrumentations |
We focus on the CPU feature CoreSight implemented on some ARM-based system-on-chips (SoCs) to address this limitation. CoreSight captures the executions of branch instructions at runtime. Intel processors have a similar CPU feature known as Intel Processor Trace (Intel PT). Several existing studies, such as kAFL, employ Intel PT for x86 binary-only fuzzing. We compared both the features to adopt the lessons learned from the Intel PT-based methods to the new CoreSight-based method. Figure 2 illustrates the QEMU and CoreSight modes. Both the modes instrument the PUTs at runtime. The QEMU mode executes a PUT on the VM and generates feedback at every edge of the basic blocks synchronously (Figure 2 (b-1)). On the contrary, the CoreSight mode executes PUTs on the native CPU and generates feedback asynchronously (Figure 2 (b-2)). Therefore, it performs better than the QEMU mode by nature.
 |
| Figure 2. QEMU and CoreSight modes |
Introduction to CoreSight
Some modern CPUs have a feature that traces processor behavior at runtime for debugging or performance monitoring purposes. Both Intel PT and ARM CoreSight have sufficient features to provide trace data, such as branch information for fuzzing feedback generation. CoreSight differs from Intel PT in some respects. Its specification defines more functions than the Intel PT, and it is provided as a set of multiple hardware components, while the Intel processor integrates the Intel PT as a single function.
The CoreSight implementations differ from SoC to SoC because the vendor configures the CoreSight hardware components when designing the processor. The system consists of three types of components: trace source, trace sink, and trace link. A trace source is a trace generator, and a trace sink stores or transfers traces. A trace link connects trace sources and trace sinks. In CoreSight, a set of bits known as a packet represents a trace, and a series of packets is referred to as trace data. To reconstruct the program behaviors from the trace data, we have to decode the packets in the trace data.
For more details of the CoreSight, please refer to the following ARM official CoreSight introduction:
To summarize, we need a tracer that controls the components and a decoder for the given trace data to generate feedback from the CoreSight.
AFL++ CoreSight mode
We developed a new tracer coresight-trace and decoder coresight-decoder for the AFL++ CoreSight mode. A characteristic of the tracer is that it runs entirely on user-space and does not depend on the Linux kernel CoreSight device drivers. Based on this design, even if the Linux kernel on the system cannot recognize the CoreSight devices because of the lack of device tree registration, the tracer can communicate with the CoreSight components to retrieve the traces. The decoder’s highlighted features include the following: 1) it supports the path coverage scheme proposed in the PTrix for Intel PT and the traditional AFL-style edge coverage; 2) it aims for high performance by providing a multi-layer cache mechanism and by supporting concurrent execution with the tracer. The decoder design is based on the best practice in Intel PT, because the decoding tends to be the bottleneck.
The tracer and decoder are available on:
- Tracer: RICSecLab/coresight-trace
- Decoder: RICSecLab/coresight-decoder
The following chapters describe the technical issues we solved to develop a CoreSight-based fuzzing feedback in tracer and decoder.
Tracer: coresight-trace
A tracer is responsible for retrieving the traces required to generate feedback by monitoring a PUT and by manipulating the CoreSight components. It controls the tracing of the PUT process as it starts and stops.
We implemented the tracer as a derivation of the afl-proxy proxy application. As indicated in the original AFL, calling many exec() for fuzzing PUTs decreases the performance due to the overhead of the system call. Thus, we also implemented a fork server mode to the tracer in the same manner as the PTrix implementation.
Figure 3 shows the workflow of the AFL++ CoreSight mode, which comprises the AFL fuzzer, proxy application, and PUT. The proxy application consists of a tracer and decoder, and they asynchronously run on independent threads.
 |
| Figure 3. AFL++ CoreSight mode workflow |
We addressed some of the technical issues caused by the CoreSight specifications. @retrage describes our approaches in the following sections.
Filtering Trace
To obtain the appropriate trace data, a filter must be set up, such that CoreSight outputs the PUT process-related trace data. PID filtering is a well-known approach that compares the PID of the target process to the CONTEXTIDR register, in which the OS sets the PID of the running processes to the register. However, this method requires reconfiguring the filter for every fuzzing loop because the PID to be traced changes every fork and decreases the performance. We noticed that the address layout of each forked child process did not change in the fork server mode that we implemented. Therefore, to avoid this issue, we configure the filter at the beginning so that CoreSight outputs trace data only within the address range of the PUT.
Embedded Trace Router for Storing Traces in DRAM
As mentioned earlier, CoreSight uses a component known as the trace sink to store or transfer the trace data. Because a typical fuzzing algorithm traces everything from the start to the end of the PUT process, a trace sink should have a sufficient buffer capacity. In addition, because fuzzing requires high performance, the transfer speed of the traces is essential. However, inexpensive SoCs may not have a trace sink with sufficient capacity and transfer speed. Figure 4 shows a CoreSight configuration typically used for inexpensive SoCs.
Figure 4 is a CoreSight configuration typically used for inexpensive SoCs.
") |
| Figure 4. CoreSight configuration storing trace data in ETB (based on ID010111 Revision r0p1 Figure 1-4) |
A trace sink known as an embedded trace buffer (ETB) stores the trace data to its SRAM in this configuration. The trace data from each trace source are aggregated by a trace link known as Funnel and are transferred to the ETB. The ETB has an advantage in its low latency; nonetheless, the buffer size is small for fuzzing. For instance, tracing libxml2 generates approximately 450 KB of trace data, whereas ETB only has a buffer of 4 KB to 64 KB, which is not large enough to store the entire trace. Fuzzing with such a small buffer requires that the PUT is suspended periodically to save traces before it overflows. However, because the size of a target PUT increases, the frequency of the interruption increases, which deteriorates the performance.
To avoid this problem, we focused on a trace sink known as the embedded trace router (ETR). Some high-end SoCs have this CoreSight component which stores trace data in DRAM like Intel PT. The ETR dynamically allocates buffers up to 4 GB from the DRAM, whereas the ETB has a fixed SRAM buffer capacity. Figure 5 shows an example of the CoreSight configuration with the ETR.
") |
| Figure 5. CoreSight configuration stores the trace data in the DRAM using ETR via ETF (based on ID010111 Revision r0p1 Figure 1-8) |
Because the ETR uses DRAM to store the trace data, it may have latency when other high-priority DRAM accesses are requested. Figure 5 configuration uses the embedded trace FIFO (ETF) as a FIFO buffer to avoid trace loss if a delay occurs. The ETF transfers the trace data to the ETR via a trace link known as the Replicator. Although the ETR has latency compared to the ETB, our preliminary experiment on Jetson TX2 reveals that the ETR achieves higher throughput than the ETB as shown below. (The ETB in this table is strictly an ETF; nonetheless, the ETF can also be used as an ETB by setting the mode described in the next section.)
| Size (KB) | Read (MB/sec) | |
|---|---|---|
| ETB | 32 | 23.3 |
| ETR | 1024 | 65.8 |
Due to these CoreSight hardware limitations, our coresight–trace requires configuration with ETR as shown in Figure 5.
Handling Overflow Packets
Trace sinks have several different role modes. For example, the circular buffer mode uses a trace sink as a ring buffer to read the user. In this mode, the overflow status register bit is set when the buffer is full, making it easy to detect trace data loss at the runtime.
If a trace sink is used as a FIFO buffer such as the ETF shown in Figure 5, we set the trace sink to the hardware FIFO mode. The trace sink will notify behind the components when the buffer is about to overflow; we refer to this behavior as back pressure. When this occurs, the trace source sends an overflow packet and waits for the trace sink until the overflow is resolved. Figure 6 shows the behavior of the ETF when back pressure occurs.
 |
| Figure 6. ETF Behavior on back pressure |
Because the CPU continues to run while the trace source is suspended, the trace may be missing. Therefore, trace data containing overflow packets are incomplete and should be discarded. However, we have seen overflow packets at high frequencies during our fuzzing experiment, and discarding such trace data decreased the fuzzing performance. To overcome this, we made a simple assumption on the trace data. Because the period during which tracing is stopped is relatively short, the number of missing traces is negligible. Moreover, because the undiscovered execution paths are rarer than the known ones, all the missing traces are known execution paths with high probability. Therefore, it is unlikely that the missing traces will prevent the fuzzer from finding a new execution path. Thus, we decided to decode the trace data based on this assumption, even if an overflow packet was detected. Although this approach contradicts the CoreSight usage guidelines, we experimentally confirmed that this method could find new execution paths.
By adopting the PTrix-based architecture, trace filtering, use of ETR, and handling of overflow packets, we developed a tracer that takes full advantage of CoreSight.
Decoder: coresight-decoder
A decoder is responsible for generating feedback from the trace data for fuzzing.
Because a decoder can be a bottleneck in fuzzing with hardware tracers, it is necessary to use some techniques for better efficiency. The following sections were written by @mmxsrup.
Decoder Overview
The purpose of a decoder is to recover the execution history from the trace data and compute the coverage used as feedback for fuzzing. Hardware tracers such as CoreSight and Intel PT do not store complete execution history, and they encode only partial information in the form of packets. This design improves the trace performance; however, it cannot recover the execution history using only the trace data. For example, suppose a CPU executes an indirect branch instruction. In this case, the trace data will only contain information about whether the branch occurred at that point, not the branch destination address. The decoder must disassemble the PUT binary to obtain the branch destination address.
Figure 7 illustrates the decoding procedure for the assembly and trace data. The code consists of a loop starting at 0x71c and a function that calls the loop starting at 0x900. The trace data contains address and atom packets that represent the branch information. An address packet is a packet that records the address of the indirect branch instruction branches. An atom packet represents the result of the direct branch instruction. The E bit represents that the branch was taken, and the N bit represents that the branch was not taken. In addition, an atom packet may contain multiple branches to compress packets for efficiency. For example, EEEN indicates that it branches three times in a row and does not branch the fourth time.
The first address packet is the starting address of the trace, which indicates that the execution starts at address 0x0000aaaaceaa0900. Because the address in the packet is a physical address, it needs a memory map for the program to know where the binary is on the memory. By calculating the actual location from the memory map, it was found that the execution started at assembly code 0x900. The second packet is an atom packet, indicating a direct branch execution. There is a direct branch bl at 0x908 if you observe the code from the forward direction. This indicates that the atom packet shows that it branches at the branch instruction, and the control flow changes to 0x71c. The third packet is an atom packet that indicates branches three times and does not branch at the fourth time. We find a direct branch instruction b.ne at 0x730, which conditionally jumps to 0x72c by observing from the 0x71c forward direction. This packet shows that the instruction branches three times and jumps to 0x71c. The last N bit indicates that it was not branched at the fourth time and continued to 0x734.
The fourth packet is an atom packet, corresponding to an indirect branch ret that is branched. A branch destination address cannot be determined solely from the atom packet and assembly code for indirect branch instruction. Therefore, a subsequent address packet must be generated just after the atom packet for the indirect branch, where the indirect branch instruction branches to 0x0000aaaaceaa090c, and the control flow returns to 0x90c.
 |
| Figure 7. Decoder behavior |
Because an address in an address packet is a physical address, it can be changed for each fuzzing campaign, even if they have the same control flow. Therefore, an offset on the ELF file is used instead of the physical address to compute the coverage. In addition, to support more than one program binary to trace, binaries are identified using unique IDs.
There is a slight difference in the decoding process between Intel PT and CoreSight. CoreSight atom packets correspond to Intel PT TNT packets, and the address packets correspond to TIP packets. The decoder preprocesses the raw trace data to retrieve only the trace data needed to generate feedback before starting the decoding because the raw trace data include traces from all CPU cores.
Optimizing the Decoder
In the previous section, we showed how to restore the edge coverage from the CoreSight trace data. Fuzzing runs a PUT repeatedly, which indicates that the decoding of trace data occurs several times. Therefore, decoding processes can be bottlenecks for fuzzing with hardware tracers. Unfortunately, our preliminary experiments show that the simple decoding technique described above is impractical, considering the performance. As such, we introduced concurrent decoding and two software cache layers to achieve a better decoding performance.
Concurrent decoding reduces the latency of a single fuzzing cycle during the runtime between tracing and decoding. If a decoder starts the process after all the tracing is complete, the latency of the fuzzing cycle increases. Therefore, we made it possible to start and resume at each partial completion of the tracing process. This indicates that the tracer and decoder can perform concurrently. This design reduces the runtime from the start of the tracing process to the completion of the decoding process; thereby, improving the efficiency of the entire fuzzing process. Therefore, we implemented a decoder to decode the fragmented trace data.
The cache layers record the results generated during a fuzzing cycle for the decoder to reuse them. A fuzzer computes edge coverages by decoding the trace data multiple times for the same PUT binary. Because the coverage obtained for each fuzzing cycle is often almost identical, the piece of the binary to be disassembled in each fuzzing cycle and the trace data are approximately identical. Additionally, the programs that contain loops disassemble the same code multiple times. This indicates that fuzzing often consists of repeated works on a PUT, and caching the results of such work contributes to more efficient decoding.
Moreover, libxdc is a decoder for Intel PT that uses software caching for optimized decoding. In our decoder, we introduce two cache layers that are similar to libxdc. However, the libxdc codebase contains many unnecessary parts; therefore, we have developed a decoder from scratch while referring to libxdc.
The first cache layer stores the results of the program binary disassembly to avoid redundant disassembly processes. As illustrated in the previous section, an atom packet representing the conditional branch does not have a branch destination address. Therefore, a decoder must disassemble the program binary, find the branch instruction, and parse the branch destination address. This sequence of tasks for the same code is performed several times during the fuzzing cycle; therefore, the results of this sequence of tasks can be cached to eliminate unnecessary disassembly. This cache uses a hash table, where the key is the starting address, and the data is the destination address of the branch instruction closest to the starting address.
The second cache layer stores the edge coverage calculation results to eliminate redundant atom packet parsing. As explained in the previous section, an atom packet may contain multiple branch records. Regarding this case, the decoder must parse each branch address from the EN bits stored in the Atom packet to compute the edge coverage. Because the trace data are often the same, this sequence of operations is performed many times during the fuzzing cycle. If the second cache layer does not exist, the decoder needs to compute the same result using the data stored in the hash table to restore the edge coverage. Therefore, the calculated edge coverage is cached to eliminate unnecessary atom packet parsing. This cache uses a hash table, where the key is the starting address and the atom packet and data are the results of the calculated edge coverage.
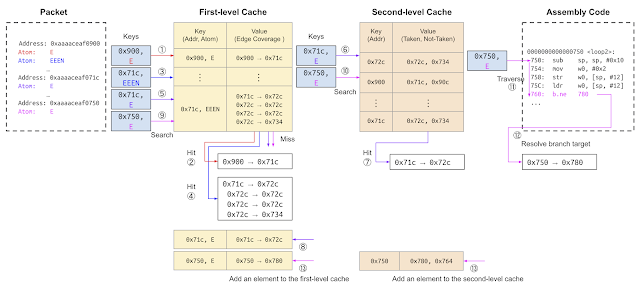
Figure 8 shows how these two caches work. In this example, the cache stores the decoding results described in Figure 7. It decodes the packets shown in Figure 8 from the second fuzzing campaign. (1) The E Atom bit is in a trace starting from 0x900, and the decoder searches for the address’s edge coverage from the first-stage cache. (2) The cache hits and finds the edge coverage. (3) The set of EEEN atom bits is in a trace starting from 0x71c, and it looks for the edge coverage at the address from the first-stage cache. (4) The cache hits and finds the edge coverage. (5) The E atom bit is in a trace starting from 0x900, and the decoder looks for the address’s edge coverage from the first-stage cache. (6) The cache misses. The decoder searches for the branch destination address of the first branch instruction after 0x71c in the second-stage cache. (7) The cache hits, and the destination address is 0x72c, where the branch is taken, and it computes the edge coverage. This shows that even if the traces follow the same control flow, the trace data do not always match because of external factors such as interruptions. In such cases, the second-stage cache is valuable. (8) The first-stage cache is updated to add the decoding result. (9) The E atom bit is in the trace starting from 0x750, and it searches for the edge coverage at the address in the first-stage cache. (10) Because of the cache miss, it searches for the branch destination address of the first branch instruction after 0x750 in the second-stage cache. (11) Because the second-stage cache misses, the decoder disassembles the target binary and searches for branch instructions from 0x750 in the forward destination. (12) It finds the branch instruction b.ne 780, specifies the branch destination address, and calculates the edge coverage. (13) Update the cache by adding the decoding results to the first and second caches.
 |
| Figure 8. Decoder behavior with two caches |
By applying the best practice of the Intel PT decoders to CoreSight, we developed an optimized CoreSight decoder for fuzzing.
Design and Implementation of PTrix-style Path Coverage
This section describes the design and implementation of PTrix-style path coverage for CoreSight.
In the PTrix paper, they point out that it is inefficient to generate AFL edge coverages from Intel PT trace data because it requires disassembling the PUT binaries as already mentioned in the previous section. They proposed a method that directly generates fuzzing feedback from the trace data without disassembling the binaries to solve this issue. This method computes a hash from the TNT and TIP packets and encodes the resulting hash to update the bitmap. Because the hash value represents the history of the trace packets, it can be used as a path coverage. Their experiments showed that the coverage representation captured better execution paths than the AFL edge coverage.
We implemented this PTrix-style path coverage by making the decoder compute the hash using atom and address packets. The decoder converts EN bits of the atom packets to a “0” and “1” to optimize the hash calculation for better performance.
Benchmark
How efficient are the many optimizations introduced in previous chapters? We conducted a benchmark to measure execution performance.
We chose four fuzzers for the benchmark: AFL++ LTO (instrumentation at build time), AFL++ QEMU, AFL++ CoreSight (edge coverage), and AFL++ CoreSight (path coverage) modes. The target PUT is a simple application void main(void) {}, and we measured the number of executions in 60 s. The PUT is a simple application to ensure that the fuzzers are not affected by the nature of the paths.
| # of exec | exec/sec | |
|---|---|---|
| LTO mode | 169169 | 2819.5 |
| QEMU mode | 64307 | 1071.8 |
| CoreSight mode (Edge cov.) | 96490 | 1608.2 |
| CoreSight mode (Path cov.) | 99744 | 1662.4 |
The results show that both CoreSight modes outperform the QEMU mode. The result of the PTrix-style path coverage mode is slightly higher than that of the edge coverage mode, and this result is consistent with that shown in the PTrix paper. Unfortunately, they cannot outperform the source code instrumented fuzzing because of the CoreSight operation-related overhead. However, we believe that this CoreSight-based binary-only fuzzing method is quite promising because the source code for ARM binaries, especially firmware, is unavailable in most practical situations.
Efficiency of the Path Coverage
We ran the four fuzzers described in the previous section with the PUT shown below to assess the efficiency of the path coverage mode. We measured the number of executions and generated seeds until the first crash occurred. This PUT crashes only if the first ten bytes of the input match aaaaabbbbb. A fuzzer feedback must be path-sensitive for reaching a crash. We performed this PUT based on the toy program from PTrix implementation.
read(0, src, SIZE); for (int i = 0; i < SIZE; i++) { if (src[i] == 'a') { dst[i] = src[i]; continue; } if (src[i] == 'b') { dst[i] = src[i]; continue; } break; } if (!strncmp(dst, "aaaaabbbbb", 10)) { crash(0); }
| # of exec | # of seeds | |
|---|---|---|
| LTO mode | 153260 | 11 |
| QEMU mode | 144645 | 12 |
| CoreSight mode (Edge cov.) | 146844 | 16 |
| CoreSight mode (Path cov.) | 135308 | 98 |
The results show that the CoreSight path coverage mode reaches a crash with the smallest executions in the fuzzers. In addition, the CoreSight path coverage mode generated more seeds than the other fuzzers. This indicates that the path coverage mode is more path-sensitive than the edge coverage modes, as intended.
Conclusions
We introduced our work on binary-only fuzzing using CoreSight. We demonstrated the availability of efficient binary-only fuzzing for ARM, which forms a part of our research on fuzzing. We hope you are safe and stay tuned for more.
Acknowledgements
This project has received funding from the Acquisition, Technology & Logistics Agency (ATLA) under the National Security Technology Research Promotion Fund 2021 (JPJ004596).
如有侵权请联系:admin#unsafe.sh