1 背景与挑战
问答系统(Question Answering System, QA)是人工智能和自然语言处理领域中一个倍受关注并具有广泛发展前景的方向,它是信息检索系统的一种高级形式,可以用准确、简洁的自然语言回答用户用自然语言提出的问题。这项研究兴起的主要原因是人们对快速、准确地获取信息的需求,因此被广泛应用于工业界的各种业务场景中。美团在平台服务的售前、售中、售后全链路的多个场景中,用户都有大量的问题需要咨询商家。因此我们基于问答系统,以自动智能回复或推荐回复的方式,来帮助商家提升回答用户问题的效率,更快地解决用户的问题。
针对不同问题,美团的智能问答系统包含多路解决方案:
- PairQA:采用信息检索技术,从社区已有回答的问题中返回与当前问题最接近的问题答案。
- DocQA:基于阅读理解技术,从商家非结构化信息、用户评论中抽取出答案片段。
- KBQA(Knowledge-based Question Answering):基于知识图谱问答技术,从商家、商品的结构化信息中对答案进行推理。
本文主要分享在KBQA技术落地中的实践与探索。
在用户的问题中,包括着大量关于商品、商家、景区、酒店等相关基础信息及政策等信息咨询,基于KBQA技术能有效地利用商品、商家详情页中的信息,来解决此类信息咨询问题。用户输入问题后,KBQA系统基于机器学习算法对用户查询的问题进行解析、理解,并对知识库中的结构化信息进行查询、推理,最终将查询到的精确答案返回给用户。相比于PairQA和DocQA,KBQA的答案来源大多是商家数据,可信度更高。同时,它可以进行多跳查询、约束过滤,更好地处理线上的复杂问题。
实际落地应用时,KBQA系统面临着多方面的挑战,例如:
- 繁多的业务场景:美团平台业务场景众多,包涵了酒店、旅游、美食以及十多类生活服务业务,而不同场景中的用户意图都存在着差别,比如“早餐大概多少钱”,对于美食类商家需要回答人均价格,而对于酒店类商家则需要回答酒店内餐厅的价格明细。
- 带约束问题:用户的问题中通常带有众多条件,例如“故宫学生有优惠吗”,需要我们对故宫所关联的优惠政策进行筛选,而不是把所有的优惠政策都回答给用户。
- 多跳问题:用户的问题涉及到知识图谱中多个节点组成的路径,例如“XX酒店的游泳池几点开”,需要我们在图谱中先后找到酒店、游泳池、营业时间。
下面将详细讲述我们是如何设计高准确、低延时的KBQA系统,处理场景、上下文语境等信息,准确理解用户、捕捉用户意图,从而应对上述的挑战。
2 解决方案
KBQA系统的输入为用户Query,输出为答案。总体架构如下图1所示。最上层为应用层,包括对话以及搜索等多个入口。在获取到用户Query后,KBQA线上服务通过Query理解和召回排序模块进行结果计算,最终返回答案文本。除了在线服务之外,知识图谱的构建、存储也十分重要。用户不仅会关心商户的基本信息,也会询问观点类、设施信息类问题,比如景点好不好玩、酒店停车是否方便等。针对上述无官方供给的问题,我们构建了一套信息与观点抽取的流程,可以从商家非结构化介绍以及UGC评论中抽取出有价值的信息,从而提升用户咨询的满意度,我们将在下文进行详细介绍。

对于KBQA模型,目前的主流解决方案有两种,如下图2所示:

- 基于语义解析(Semantic Parsing-based):对问句进行深度句法解析,并将解析结果组合成可执行的逻辑表达式(如SparQL),直接从图数据库中查询答案。
- 基于信息抽取(Information Retrieval):先解析出问句的主实体,再从KG中查询出主实体关联的多个三元组,组成子图路径(也称多跳子图),之后分别对问句和子图路径编码、排序,返回分数最高的路径作为答案。
基于语义解析的方法可解释性更强,但这种方法需要标注大量的自然语言逻辑表达式,而信息抽取式的方法更偏向端到端的方案,在复杂问题、少样本情况下表现更好,但若子图过大,会显著降低计算的速度。
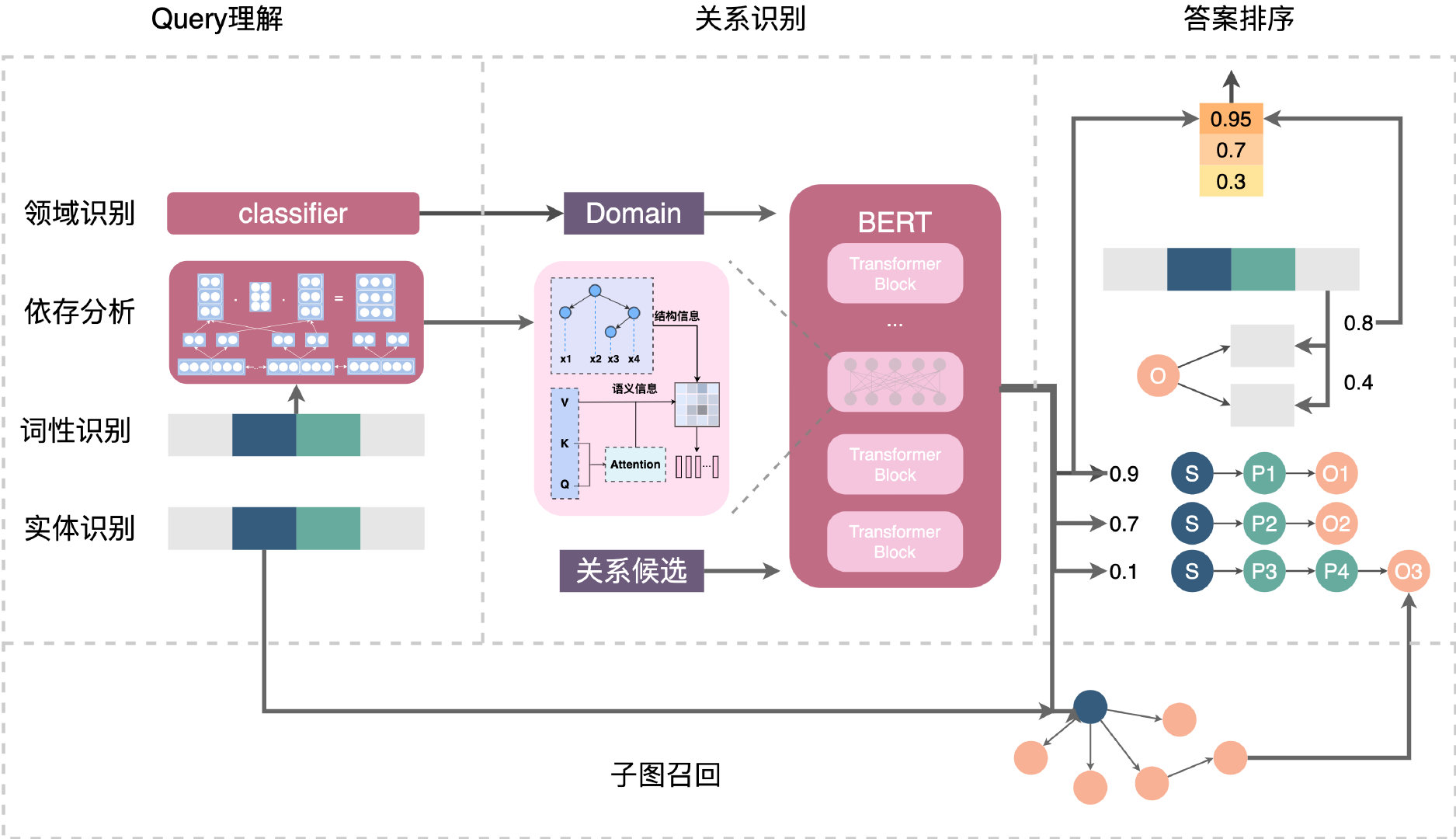
因此,考虑到两者的优势,我们采用将两者结合的方案。如下图3所示,整体的流程分为四大步骤,以“故宫周末有学生票吗”为例:

- Query理解:输入原始Query,输出Query理解结果。其中会对对Query进行句法分析,识别出用户查询的主实体是“故宫” 、业务领域为“旅游”、问题类型为一跳(One-hop)。
- 关系识别:输入Query、领域、句法解析结果、候选关系,输出每个候选的分数。在这个模块中,我们借助依存分析强化Query的问题主干,召回旅游领域的相关关系,进行匹配排序,识别出Query中的关系为“门票”。
- 子图召回:输入前两个模块中解析的主实体和关系,输出图谱中的子图(多个三元组)。对于上述例子,会召回旅游业务数据下主实体为“故宫”、关系为“门票”的所有子图。
- 答案排序:输入Query和子图候选,输出子图候选的分数,如果Top1满足一定阈值,则输出作为答案。基于句法分析结果,识别出约束条件为“学生票”,基于此条件最终对Query-Answer对进行排序,输出满足的答案。
下面将介绍我们对于重点模块的建设和探索。
2.1 Query理解
Query理解是KBQA的第一个核心模块,负责对句子的各个成分进行细粒度语义理解,其中两个最重要的模块是:
- 实体识别和实体链接,输出问句中有意义的业务相关实体和类型,如商家名称、项目、设施、人群、时间等。
- 依存分析:以分词和词性识别结果为输入,识别问句的主实体、被提问信息、约束等。
实体识别是句法分析的重要步骤,我们先基于序列标注模型识别实体,再链接到数据库中的节点。对于该模块我们主要做了以下优化:
- 为了提升OOV(Out-of-Vocabulary)词的识别能力,我们对实体识别的序列标注模型进行了知识注入,利用已知的先验知识辅助新知识的发现。
- 考虑到实体嵌套的问题,我们的实体识别模块会同时输出粗粒度和细粒度的结果,保证后续模块对于Query的充分理解。
- 在问答的长Query场景下,利用上下文信息进行实体的链接,得到节点id。
最终,该模块会输出句子中各个重要成分的类型,如下图4所示:

依存分析是句法分析的一种,它的目的是识别句子中词与词的非对称支配关系,在输出的结果中用有向弧表示,该弧线由从属词(dep)指向支配词(head)。对于KBQA任务,我们定义了五种关系,如下图5所示:

依存分析主要有两种方案:基于转移的(Transition-based)和基于图的(Graph-based)。基于转移的依存分析将依存句法树的构建建模为一系列操作,由模型预测每一步的动作(shift、left_arc、right_arc),不断将未处理的节点入栈并赋予关系,最终构成句法树。基于图的方法则致力于在图中找出一棵最大生成树,也就是句子整体依存关系的全局最优解。考虑到基于图的方法是对全局进行搜索,准确率更高,我们采用较为经典的“Deep Biaffine Attention for Neural Dependency Parsing”模型,它的结构如下图6所示:

该模型先通过BiLSTM对词与词性的拼接向量进行编码,之后采用对用两个MLP头分别编码出h(arc-head)和h(arc-dep)向量,去除冗余信息。最终将各个时刻的向量拼接起来得到H(arc-head)和H(arc-dep),且在H(arc-dep)上拼接了一个单位向量,加入中间矩阵U(arc)进行仿射变换,得到dep与head的点积分数矩阵S(arc),找到每个词依存的head。
有了依存分析的结果,我们可以更好地识别关系、复杂问题,具体的特征使用方法将在下文进行介绍。
2.2 关系识别
关系识别是KBQA中另一个核心模块,目的是识别出用户Query所问的关系(Predicate),从而与主实体(Subject)联合确定唯一子图,得到答案(Object)。
在实践中,考虑到图谱中边关系的数量会不断增加,我们将关系识别建模为文本匹配任务,输入用户Query、Query特征和候选关系,输出关系匹配的分数。为了解决开头提到的多领域问题,我们在输入的特征中加入了领域信息,从而在领域表示中存储一定的领域相关知识,让模型更好地判断。同时,为了提升复杂Query的理解,我们在输入中还融入了句法信息,让模型可以更好地理解带约束、多跳的问题。

随着大规模预训练语言模型的出现,BERT等大模型在匹配任务上取得了SOTA的结果,通常业界通用的方法主要归类为以下两种:
- 表示型:也称“双塔模型”,它的主要思想是将两段文本转换成一个语义向量,然后在向量空间计算两向量的相似度,更侧重对语义向量表示层的构建。
- 交互型:该方法侧重于学习句子中短语之间的对齐,并学习比较他们之间的对齐关系,最终将对齐整合后的信息聚合到预测层。由于交互型模型可以利用到文本之前的对齐信息,因而精度更高、效果更好,所以在本项目中我们采用交互型模型来解决匹配问题。
为了充分利用BERT的语义建模能力,同时考虑实际业务的线上延时要求,我们在推理加速、数据增强、知识增强方面做了以下三点优化:
- 层次剪枝:BERT每层都会学到不同的知识,靠近输入侧会学到较为通用的句法知识,而靠近输出则会学习更多任务相关的知识,因此我们参考DistillBERT,采取Skip等间隔式层次剪枝,只保留对任务效果最好的3层,比单纯保留前三层的剪枝在F1-score上提升了4%,同时,实验发现不同剪枝方法效果差距可达7%。
- 领域任务数据预精调:剪枝后,由于训练数据有限,3层模型的效果有不小的下降。通过对业务的了解,我们发现美团的“问大家”模块数据与线上数据的一致性很高,并对数据进行清洗,将问题标题和相关问题作为正例,随机选取字面相似度0.5-0.8之间的句子作为负例,生成了大量弱监督文本对,预精调后3层模型在准确率上提升超过4%,甚至超过了12层模型的效果。
- 知识增强:由于用户的表达方式多种多样,准确识别用户的意图,需要深入语意并结合语法信息。为了进一步提升效果,同时解决部分Case,我们在输入中加入了领域与句法信息,将显式的先验知识融入BERT,在注意力机制的作用下,同时结合句法依存树结构,准确建模词与词之间的依赖关系,我们在业务数据以及五个大型公开数据集上做验证,对比BERT Base模型在准确率上平均提升1.5%。
经过上述一系列迭代后,模型的速度、准确率都有了大幅的提升。
2.3 复杂问题理解
在真实场景中,大部分问题可以归为以下四类(绿色为答案节点),如下图8所示:

问题的跳数根据实体数量决定,单跳问题通常只涉及商户的基本信息,比如问商户的地址、电话、营业时间、政策等,在知识图谱中都可以通过一组SPO(三元组)解答;两跳问题主要是针对商户中某些设施、服务的信息提问,比如酒店的健身房在几层、早餐几点开始、以及接送机服务的价格等,需要先找到商户->主实体(设施/服务/商品等)的路径,再找到主实体的基本信息三元组,也就是SPX、XPO两个三元组。约束问题指主实体或答案节点上的约束条件,一般为时间、人群或是定语。
下面介绍针对不同类型的复杂问题,我们所进行的一些改进。
2.3.1 带约束问题
通过对线上日志的挖掘,我们将约束分为以下几类,如下图9所示:

对于带约束问题的回答涉及两个关键步骤:约束识别和答案排序。
通过KBQA系统中的依存分析模块,我们可以识别出用户在实体或关系信息上所加的约束限制,但约束的说法较多,且不同节点的约束类型也不一样,因此我们在构造数据库查询SQL时先保证召回率,尽量召回实体和关系路径下的所有候选节点,并在最终排序模块对答案约束进行打分排序。
为了提升效率,我们首先在知识存储层上进行了优化。在复合属性值的存储方面,Freebase提出Compound Value Type (CVT) 类型,如下图10所示,来解决这类复合结构化的数据的存储与查询问题。比如欢乐谷的营业时间,对于不同的场次是不一样的。这种复合的属性值可以用CVT的形式去承接。

但是,CVT存储方式增加查询复杂度、耗费数据库存储。以图“欢乐谷营业时间CVT”为例:
- 该信息以通常成对CVT形式存储,一个CVT涉及3个三元组存储。
- 对于“欢乐谷夏季夜场几点开始”这样的问题,在查询的时候,涉及四跳,分别为,<实体 -> 营业时间CVT>, <营业时间CVT -> 季节=夏季>, <营业时间CVT -> 时段=夜场>,<营业时间CVT -> 时间>。对业界查询快速的图数据库比如Nebula来说,三跳以上的一般查询时间约为几十毫秒,在实际上线使用中耗时较长。
- 一旦属性名称、属性值有不同的但是同意的表达方式,还需要多做一步同义词合并,从而保证查询时能匹配上,没有召回损失。
为了解决上述问题,我们采用Key-Value的结构化形式承载属性信息。其中Key为答案的约束信息,如人群、时间等可以作为该属性值的约束的信息,都可以放在Key中,Value即为要查的答案。对于上文的例子,我们将所有可能的约束维度的信息组成Key,如下图11所示:

之后,为了解决约束值说法过多的问题,在实际查询过程中,在找不到完全匹配的情况下,我们用属性值的Key和问题中的约束信息进行匹配计算相关度,相关度最高的Key,对应的Value即为答案。因此,Key的表示方法可以为多种形式:
- 字符串形式:用文本相似度的方法去计算和约束文本的相关性。
- 文本Embedding:如对Key的文本形式做Embedding形式,与约束信息做相似计算,在训练数据合理的情况下,效果优于字符串形式。
- 其他Embedding算法:如对虚拟节点做Graph Embedding,约束文本与对应的虚拟节点做联合训练等等。
这种形式的存储方式,相当于只存储一个三元组,即<实体->营业时间KV>,查询过程压缩成了一跳+文本匹配排序。基于语义模型的文本匹配可以在一定程度上解决文本表达不同造成的不能完全匹配的问题。对语义模型进行优化后,可以尽量压缩匹配时间,达到十几毫秒。
进行复杂条件优化后,先通过前置模块识别到实体、关系和约束,组成约束文本,再与当前召回子图的Key值候选进行匹配,得到最终的答案。
2.3.2 多跳问题
多跳问题是天然适合KBQA的一类问题,当用户询问商户中的设施、服务、商品等实体的信息时,我们只需要先在图谱中找到商户,再找到商户下的实体,接着找到下面的基本信息。如果使用FAQ问答的解法,就需要为每个复杂问题都设置一个标准问,比如“健身房的位置”、“游泳馆的位置”等。而在KBQA中,我们可以很好地对这类问题进行压缩,不管问什么实体的位置,都问的是“位置”这条边关系,只是起始实体不同。
在KBQA系统中,我们先依赖依存分析模块对句子成分间的依赖关系进行识别,之后再通过关系识别模块判断句子所询问的关系跳数以及关系,具体流程如下图12所示:

借助实体识别的类型,我们可以将句子中的重要成分进行替换,从而压缩候选关系配置的个数、提升关系识别准确率。在对句子进行了充分理解后,系统会基于主实体、关系、跳数对子图进行查询,并输入给答案排序模块进行更细粒度的约束识别和打分。
2.4 观点问答
除了上述基本信息类的查询Query外,用户还会询问观点类的问题,比如“迪士尼停车方便吗?”、“XX酒店隔音好吗?”等。对于主观观点类问题,可以基于FAQ或阅读理解技术,从用户评论中找出对应的评论,但这种方法往往只能给出一条或几条评论,可能会太过主观,无法汇总群体的观点。因此我们提出了观点问答方案,给出一个观点的正反支持人数,同时考虑到可解释性,也会给出多数观点的评论证据,在App中的实际展示如下图13所示:

为了自动化地批量挖掘用户观点,我们拆解了两步方案:观点发现和Evidence挖掘,如下图14所示。

第一步,先通过观点发现在用户评论中挖掘出多种观点。我们采用基于序列标注的模型发掘句子中的实体和观点描述,并使用依存分析模型对实体-观点的关系进行判断。
第二步,在挖掘到一定数量的观点后,再深入挖掘评论中的证据(Evidence),如下图15所示。虽然在第一步观点发现时也能找到部分观点的出处,但还有很多用户评论的观点是隐式的。比如对于“是否可以带宠物”,用户不一定在评论中直接指明,而是说“狗子在这里玩的很开心”。这就需要我们对评论语句进行深度语义理解,从而归纳其中的观点。在方案的落地过程中,最初我们使用了分类模型对观点进行分类,输入用户评论,用编码器对句子进行理解,之后各个观点的分类头判断观点正向程度。但随着自动化挖掘的观点增多,为了减少人工标注分类任务的成本,我们将其转换成了匹配任务,即输入观点标签(Tag)和用户评论,判断评论语句对该观点的支撑程度。最后,为了优化速度,我们对12层Transformer进行了裁剪,在速度提升3倍的情况下效果只降了0.8%,实现了大批量的观点离线挖掘。

2.5 端到端方案的探索
在上文中,我们针对多跳、带约束等复杂问题设计了不同的方案,虽然可以在一定程度上解决问题,但系统的复杂度也随之提高。基于关系识别模块的预训练思路,我们对通用的、端到端的解决方案进行了更多的探索,并在今年的EMNLP发表了《Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Language Models》论文。
对于KBQA,目前学术界有很多研究专注于图学习方法,希望用图学习来更好地表示子图,但却忽略了图谱节点本身的语义。同时,BERT类的预训练模型是在非结构化文本上训练的,而没接触过图谱的结构化数据。我们期望通过任务相关的数据来消除两者的不一致性,从而提出了三种预训练任务,如下图16所示:

- Relation Extraction:基于大规模关系抽取开源数据集,生成了大量一跳( [CLS]s[SEP]h, r, t[SEP] )与两跳( [CLS]s1 , s2 [SEP]h1 , r1 , t1 (h2 ), r2 , t2 [SEP] )的文本对训练数据,让模型学习自然语言与结构化文本间的关系。
- Relation Matching:为了让模型更好的捕捉到关系语义,我们基于关系抽取数据生成了大量文本对,拥有相同关系的文本互为正例,否则为负例。
- Relation Reasoning:为了让模型具备一定的知识推理能力,我们假设图谱中的(h, r, t)缺失,并利用其他间接关系来推理(h, r, t)是否成立,输入格式为:[CLS]h, r, t[SEP]p1 [SEP] … pn [SEP]。
经过上述任务预训练后,BERT模型对于Query和结构化文本的推理能力显著提升,并且在非完全KB的情况下有更好的表现,如下图17所示:

3 应用实践
经过一年多的建设,当前KBQA服务已经接入美团的旅游、酒店、到综等多个业务,辅助商家及时回答用户问题,并提升了用户的满意度和转化率。
3.1 酒店问一问
酒店是用户出行的必备需求之一,但一些中小商家没有开通人工客服入口,无法及时回答用户信息。为满足用户对详情页内信息的快速查找,智能助理辅助未开通客服功能的酒店商家进行自动回复,提升用户下单转化率。用户可询问酒店以及房型页的各类信息,如下图18所示:

3.2 门票地推
门票地推致力于帮助旅游商家解决主要的卖票业务,在景区高峰时段,线上购票相比于排队更加便捷,然而仍有很多用户保持着线下购票的习惯。美团通过提过二维码以及简单的交互,提升了商户卖票以及用户购票的便捷程度。同时,我们通过在购票页内置「智能购票助手」,解决用户购票过程中的问题,帮用户更快捷地买到合适的门票,如下图19所示:

3.3 商家推荐回复
除了出行场景外,用户在浏览其他本地服务商家时也会有很多问题,比如“理发店是否需要预约?”、“店家最晚几点关门?”,这些都可以通过商家客服进行咨询。但商家本身的人力有限,难免在高峰时期迎接不暇。为了降低用户的等待时间,我们的问答服务会为商家提供话术推荐功能,如下图20所示。其中KBQA主要负责解答商家、团购相关的信息类问题。

4 总结与展望
KBQA不仅是一个热门的研究方向,更是一个复杂的系统,其中涉及到实体识别、句法分析、关系识别等众多算法,不仅要关注整体准确率,更要控制延时,对算法和工程都提出了很大的挑战。经过一年多的技术的探索,我们团队不仅在美团落地多个应用,并在2020年获得了CCKS KBQA测评的A榜第一、B榜第二和技术创新奖。同时我们开放出了部分美团数据,与北大合作举办了2021年的CCKS KBQA测评。
回到技术本身,虽然目前我们的KBQA已能解决大部分头部问题,但长尾、复杂问题才是更大的挑战,接下来还有很多前沿技术值得探索,我们希望探索以下方向:
- 无监督领域迁移:由于KBQA覆盖美团酒店、旅游到综等多个业务场景,其中到综包含十多个小领域,我们希望提升模型的Few-Shot、Zero-Shot能力,降低标注数据会造成的人力成本。
- 业务知识增强:关系识别场景下,模型核心词聚焦到不相关的词将对模型带来严重的干扰,我们将研究如何利用先验知识注入预训练语言模型,指导修正Attention过程来提升模型表现。
- 更多类型的复杂问题:除了上述提到的带约束和多跳问题,用户还会问比较类、多关系类问题,未来我们会对图谱构建和Query理解模块进行更多优化,解决用户的长尾问题。
- 端到端KBQA:不管对工业界还是学术界,KBQA都是一个复杂的流程,如何利用预训练模型以及其本身的知识,简化整体流程、甚至端到端方案,是我们要持续探索的方向。
也欢迎对KBQA感兴趣的同学加入我们团队,一起探索KBQA的更多可能性!简历投递地址:[email protected]。
作者简介
如寐、梁迪、思睿、鸿志、明洋、武威,均来自搜索与NLP部NLP中心知识图谱组。
如有侵权请联系:admin#unsafe.sh