2021-12-28 19:49:0 Author: ricercasecurity.blogspot.com(查看原文) 阅读量:55 收藏
Today, we released fuzzuf (Fuzzing Unification Framework) as an OSS.
fuzzuf is a fuzzing framework with its unique DSL(Domain-Specific Language). The DSL enables you to easily define a fuzzing loop by assembling the building blocks of fuzzing primitive while preserving the extensibility of the definition. We have already implemented several fuzzers, including AFL, VUzzer, and libFuzzer so that they would work across multiple platforms in the future. Users can extend those algorithms by modifying their definitions with the DSL.
This article provides an overview of fuzzuf and the development process.
First of all, @RKX1209 gives a brief introduction to fuzzing and explains how the framework was developed in the next section.
TL;DR
Numerous fuzzing methods, such as AFL and libFuzzer, have been developed until today. When a fuzzing researcher develops and implements a new method, the common practice is to patch such existing fuzzers to reduce the implementation cost. However, the disadvantage of this approach is that as the original fuzzer is revised, it cannot keep up with the changes in the code, which reduces its reusability.
To solve this problem, we have developed a new fuzzing framework, fuzzuf. fuzzuf is a framework with a unique DSL called HierarFlow. HierarFlow makes it possible to define various types of fuzzing loops visually and clearly, which was difficult to achieve with conventional frameworks. In addition, it is easy to modify the defined execution flow on HierarFlow.
fuzzuf is intended to be a functional and convenient framework for all fuzzing researchers. If your implementation of a fuzzing method has novelty and is recognized in a paper or other works, please send us a PR to merge it into fuzzuf.
In the future, we would like to make it possible to measure and compare the performance of various fuzzing algorithms on fuzzuf. For this purpose, we will continue to implement the existing well-known fuzzing algorithms on fuzzuf. We would be grateful for external contributions to this as well.
What is Fuzzing
Fuzzing is an automated software testing technique that confirms the validity of the program by providing malformed inputs to the program and observing its behavior.
While fuzzing is widely used by security researchers to identify memory corruption bugs, it is also known that it can be used to detect other various types of bug classes with bug oracle functions that define whether fuzzer has potentially triggered a bug or not.
Since its first introduction in the early 1990s, there has been lots of work on improving fuzzing. As a result, modern fuzzing algorithms are highly diverse and difficult to classify. In 2018, Valentin et al. published a comprehensive survey of progress in fuzzing. The paper proposed a unified model of fuzzing (Algorithm 1). A wide variety of fuzzing algorithms can be modeled in the following pseudocode.
We call the loop in this code fuzzing loop.

American Fuzzy Lop (AFL) is a good example to see that their model (Algorithm 1) can represent the architecture of modern fuzzers.
AFL is a mutation-based fuzzer that generates a new testcase by modifying one of the existing inputs. It is also classified as a greybox fuzzer, which collects code coverage gathered from the program execution with a testcase. If the testcase produces new coverage, the testcase will be saved to a disk as a seed.
AFL’s fuzzing loop can be summarized as follows: select a seed from the seed queue, generate a new testcase by mutating the seed repeatedly using a variety of methods, run the program and if it reports a new coverage, save the input to a disk as a new seed, and adds it to the queue.
A general overview of AFL’s fuzzing loop is illustrated in the
following code, where you can see that it is very similar to the one shown in Algorithm 1.
(The corresponding pseudo-code in Algorithm 1 is shown in the comments)
while(true){ /* conf ← SCHEDULE(C) */ seed = select_seed(seed_queue); /* tc ← INPUTGEN(conf) */ new_input = mutate(seed.input); /* B',execinfos ← INPUTEVAL(tc, O_bug) */ feedback = execute(new_input); /* C ← CONFUPDATE(C, tc, execinfos) */ seed_queue = add_to_queue(seed_queue, new_input, feedback); }
Fuzzing framework
As aforementioned, AFL’s fuzzing loop is very similar to the one shown in Algorithm 1, implementing all of the five functions inside a loop: SCHEDULE, INPUTGEN, INPUTEVAL, CONFUPDATE, and CONTINUE. It is also the case with other AFL family fuzzers such as AFLFast, CollAFL, and AFL++.
In recent years, researchers proposed fuzzing frameworks ([libAFL], [FOT], etc.) to implement a variety of fuzzers in a universal way. The architecture of their frameworks are fundamentally based on the fuzzing loop shown in Alogirhtm 1. Therefore, they can integrate some major fuzzers such as AFL family fuzzers by extending the five functions in Algorithm 1.
Unfortunately, there are exceptional cases such as VUzzer, which have a slightly different execution flow from Algorithm 1. VUzzer leverages static and dynamic analysis to infer fundamental properties of an application and use them to guide the input generation and seed evaluation. In Valentin’s survey paper, the fundamental difference of VUzzer from traditional mutation-based grey box fuzzer is summarized into its implementation of the two functions, INPUTGEN and CONFUPDATE: in VUzzer, INPUTGEN guides the input generation using taint analysis, and CONFUPDATE adds or deletes seeds based on the fitness function that calculates the scores of them by a custom program analysis. From the perspective of the taxonomy of fuzzers, it is enough to mention these differences. However, from the perspective of implementation, we can say that there are also some differences in its fuzzing loop. Actually, implementing the actual execution flow of VUzzer based on Algorithm 1 is not a straightforward task.
We illustrated a general overview of VUzzer’s fuzzing loop in the following code, where you can see that it is far from the loop in Algorithm 1.
(The corresponding pseudo code in Algorithm 1 is shown in the comments)
while (true) { for(seed : seed_queue) { // conf ← SCHEDULE(C) /* B',execinfos ← INPUTEVAL(conf, O_bug) */ feedback = execute(seed.input); seed.score = calc_score(feedback); if (has_new_cov(feedback)) { /* execinfos2 ← INPUTEVAL(conf, O_bug) */ feedback2 = execute_with_taint(seed.input); taints += feedback2; } } /* conf ← SCHEDULE(C) */ seed = select_seed(seed_queue); /* tc ← INPUTGEN(conf, execinfos2_set) */ new_input = mutate(seed.input, taints); /* C ← CONFUPDATE(C, tc) */ seed_queue = add_to_queue(seed_queue, new_input); /* C ← CONFUPDATE(C) */ seed_queue = update_queue(seed_queue); }
VUzzer’s fuzzing loop can be summarized as follows: for each seed in the seed queue, VUzzer collects code coverage gathered from the program execution with the seed and then calculates the fitness score of it based on the coverage. If the seed finds priviously unseen code coverage, VUzzer uses a dynamic taint analyzer to infer its structure properties.
After that, VUzzer selects some seeds from the seed queue, generates a new testcase by mutating the chosen seeds repeatedly using a variety of methods, and adds it to the queue as a new seed. Then, finally it deletes all the seeds whose score is less than the highest score from the seed queue, except for the seeds newly generated in the previous mutation.
Now it is clear that implementing VUzzer on the existing fuzzing framework based on Algorithm 1 is no easy task at all. There are major differences in both execution flow and data flow between VUzzer and the model.
Fuzzing growth
As we have seen, it is difficult to use the model to strictly represent arbitrary fuzzing algorithms while the model is sufficient for classifying and roughly explaining them. To put all the existing fuzzing code into one framework, it is necessary to consider tricky fuzzing loops such as VUzzer. (There are also other fuzzers with special loops, such as Eclipser).
Therefore, even in 2021, it is rarely possible to take advantage of existing fuzzing frameworks when developing a new fuzzer. In most cases, we are forced (or tempted) to take one of the following two approaches to develop a new fuzzer:
(a) Fork and patch an existing fuzzer
(b) Implement the entire fuzzer from scratch.
Method (a) has the advantage of reducing the development cost by reusing the components of the existing fuzzer and making it easy for other researchers to check the essential contributions by looking at the differences with the existing fuzzer. On the other hand, it has the disadvantage of not being able to keep up with changes to the code of the existing fuzzer, which can easily lead to a significant loss of reusability.
In academia, there are many patchworks [AFLFast, MOpt, IJON, NEZHA] implementing their key ideas as Proof of Concept. It is the reasonable and easiest way for researchers to focus solely on their own contributions and integrate their key ideas into production-ready fuzzers quickly. However, it is not easy for other researchers to follow two codebases of existing fuzzers and new fuzzers. If the new fuzzer is abandoned and only the original fuzzer continues to be updated, the comparison experiment with them may one day become useless.
In the case of (b), we don’t need to keep up with changes to existing fuzzers, but we must reinvent a large number of components that are common to many existing fuzzers, which requires a huge implementation effort.
Furthermore, it is difficult to determine which part contributes to the result of performance. If the fuzzer yields better results than existing fuzzers, you should determine whether the key idea is really effective or other newly implemented components are better than (or just different from) previous fuzzers.
In the worst case, you may find that putting the key idea on an existing fuzzer instead of one built from scratch does not perform well at all.
Requirements for fuzzing framework
In summary, fuzzing framework should be designed for:
- Flexibility: It should be able to build the execution flow of various fuzzing algorithms.
- Visibility: It should help us to see the contributions of researches at a glance.
- Reusability: It should provide a fuzzing ecosystem, including several common components used to aid the fuzzing loop, such as mutators and executors.
fuzzuf
In order to realize these requirements, we have developed fuzzuf, a fuzzing framework implemented in C++17. fuzzuf currently provides five algorithms: AFL [AFL], AFLFast [AFLFast], VUzzer [VUzzer], libFuzzer [libFuzzer], NEZHA [NEZHA].
fuzzuf has its own DSL called HierarFlow (Hierarchical Flow) to deal with the aforementioned problems. fuzzuf can define execution flows visually and clearly by making good use of HierarFlow. In addition, the defined execution flow can be easily modified later. In the following sections of this chapter, @hugeh0ge will explain how we came up with HierarFlow and the advantages of HierarFlow.
Why did we need HierarFlow?
We didn’t have the idea of HierarFlow when we first started developing fuzzuf. We knew that we needed a useful framework to solve the problem, but we didn’t have the answer to the question of what kind of features the framework should have.
So I started by rewriting AFL in C++17. Reading and interpreting over 8000 lines of C code and porting it to C++17 was a daunting task, but I gained a lot of insights.
Before I rewrote AFL, I believed that most fuzzers could be described and implemented well by generalizing them like Algorithm 1; I thought there were only a few fuzzers that cannot be written like Algorithm 1, and we could come up with some good solutions for them later. For the time being, it looked sufficient to provide a generalization similar to Algorithm 1 by designing some base classes for it.
However, in reality, I realized that I couldn’t write even AFL in a neat way. Why couldn’t I write it nicely? To think about this, let’s take a look at another AFL pseudo-code, which is a bit more detailed than the previous one:
while (1) { /* conf ← SCHEDULE(C) */ seed = select_seed(seed_queue); while (!did_bitflips_enough) { // will be true at some point /* tc ← INPUTGEN(conf) */ new_input1 = mutate_by_bitflip(seed); /* B',execinfos ← INPUTEVAL(tc, O_bug) */ feedback1 = execute(new_input); /* C ← CONFUPDATE(C, tc, execinfos) */ seed_queue = add_to_queue(seed_queue, new_input1, feedback1); } while (!did_byteflips_enough) { // will be true at some point /* tc ← INPUTGEN(conf) */ new_input2 = mutate_by_byteflip(seed); /* B',execinfos' ← INPUTEVAL(tc, O_bug) */ feedback2 = execute(new_input); /* C ← CONFUPDATE(C, tc, execinfos) */ opt_info = build_info_for_optimization(feedback2); seed_queue = add_to_queue(seed_queue, new_input2, feedback2); } while (!did_arithops_enough) { // will be true at some point /* tc ← INPUTGEN(conf, execinfos') */ new_input3 = mutate_by_arithop(seed, opt_info); /* B',execinfos ← INPUTEVAL(tc, O_bug) */ feedback3 = execute(new_input); /* C ← CONFUPDATE(C, tc, execinfos) */ seed_queue = add_to_queue(seed_queue, new_input3, feedback3); } while (!did_dictionaries_enough) { // will be true at some point /* tc ← INPUTGEN(conf, execinfos') */ new_input4 = mutate_by_dictionary(seed, opt_info); ...
As you can see, there are different kinds of mutations; in other words, INPUTGEN changes its operation depending on the situation. Furthermore, if you look closely, INPUTGEN also needs to change its behavior depending on the result of the last execution (opt_info). This is where I first realized that AFL algorithms do not keep performing symmetric operations as well as the ideal pseudocode.
What would it look like if we implement this in a straightforward, generalized form like Algorithm 1? My initial code looked like this:
INPUTGEN(seed) {
if (current_state == "bitflip") {
new_input = do_bitflip(seed);
INPUTEVAL(new_input);
if (did_enough_bitflips) {
current_state = "byteflip";
}
return;
} else if (current_state == "byteflip") {
new_input = do_byteflip(seed);
INPUTEVAL(new_input); // CONFUPDATE will update opt_info
if (did_enough_byteflips) {
current_state = "arith_operation";
}
return;
} else if (current_state == "arith_operation") {
new_input = do_arithop(seed, opt_info);
INPUTEVAL(new_input); // creates opt_info
if (did_enough_arithops) {
current_state = "arith_operation";
}
return;
}
...
} The silly thing is that, inside of INPUTGEN, we have to have a state representing what INPUTGEN should do now. This is not easy to write nor read at all.
“If current_state is bitflip, then INPUTGEN executes here, and CONFUPDATE executes there…”
You need to think about this while reading.
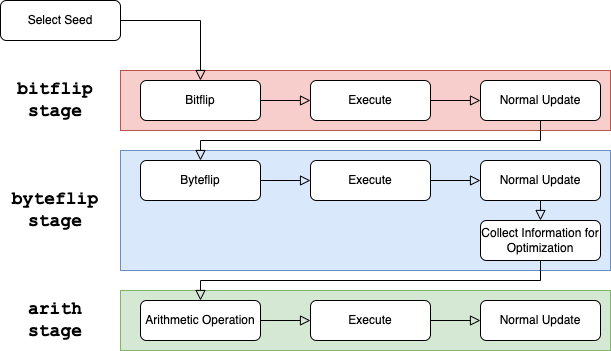
What went wrong? The cause is that I tried to divide the execution flow vertically, as shown in the following figure:

It would be better to divide the flow horizontally, considering the possibility that each stage may perform completely different operations as seen in “Collect Information for Optimization”:

This is more natural also for understanding the flow of the code. In this segmentation, we can see there are three types of operations, mutate, execute, and update in each stage. It seems to be sufficient for the framework to be able to perform each type of operations multiple times in each stage. For example, Observer pattern with two types of events, Execute event and Update event may be able to handle this, and there are actually fuzzing frameworks that are designed in such a way.
However, this is actually just a slightly generalized version of the pseudo-code of Algorithm 1. Implicitly, it assumes that fuzzing proceeds in the order of “mutate -> execute -> update” (which is, indeed, actually sufficient for AFL). Algorithms that cannot be interpreted as having this order will be expressed in an unreasonable way. Also, an algorithm that takes a set of inputs, rather than a single input, and generates a new set of inputs, e.g., by a genetic algorithm would also be difficult to express (unless we generalize it to take a set from the beginning). Inevitably, changes in design will be necessary.
HierarFlow: a DSL for describing fuzzing algorithms.
HierarFlow was conceived to make it easier to write and read fuzzing algorithms, while keeping all the noted exceptions in mind. To put it simply, HierarFlow is a tree structure of functions with parent-child relationships. Let’s take a look at an example of a concrete definition. For example, in the current version of fuzzuf, the HierarFlow of AFL is defined as follows:
fuzz_loop << ( cull_queue || select_seed ); select_seed << ( consider_skip_mut || retry_calibrate || trim_case || calc_score || apply_det_muts << ( bit_flip1 << execute << (normal_update || construct_auto_dict) || bit_flip_other << execute.HardLink() << normal_update.HardLink() || byte_flip1 << execute.HardLink() << (normal_update.HardLink() || construct_eff_map) || byte_flip_other << execute.HardLink() << normal_update.HardLink() || arith << execute.HardLink() << normal_update.HardLink() || interest << execute.HardLink() << normal_update.HardLink() || user_dict_overwrite << execute.HardLink() << normal_update.HardLink() || auto_dict_overwrite << execute.HardLink() << normal_update.HardLink() ) || apply_rand_muts << ( havoc << execute.HardLink() << normal_update.HardLink() || splicing << execute.HardLink() << normal_update.HardLink() ) || abandon_node );
The corresponding tree structure is illustrated below:

Even though HierarFlow is a DSL, it does not have its own definition grammar, definition file, or parser. It is instead implemented using C++ operator overloading. Variables such as fuzz_loop and cull_queue represent (sort of) functions.
The operator a << b indicates that b is a child of a in the tree structure, and the operator a || b indicates that a and b are siblings in the tree structure. For example, bit_flip1 has execute as a child, and execute has normal_update and construct_auto_dict as children.
A parent node (parent function) can call a child node (child function) any number of times with any arguments. Here, all child nodes with the same parent must have the same argument type. For example, nodes such as bit_flip1 and bit_flip_other are all defined with the same argument type because they have the same parent, apply_det_muts.
Usually, sibling nodes are executed in order from the top (or left). For example, when apply_det_muts calls child nodes, the nodes are called in the following order: bit_flip1, bit_flip_other, and so on. Note that the child nodes are not called in parallel.
However, a child node can also change its sibling node to be executed next. For example, if a fatal error occurs during mutation, apply_det_muts may skip apply_rand_muts and jump to abandon_node, forcing the mutation to terminate.
Thus, instead of allowing procedures to be inserted in specific places as in the Observer pattern, we leave it up to the user to define the entire execution flow, which allows for a very flexible representation of algorithms.
Perhaps those with good intuition may have wondered, “Isn’t this HierarFlow almost the same as just a function call?” Even without using HierarFlow, the same execution flow can be achieved by defining the function apply_det_muts and internally calling the functions bit_flip1, bit_flip_other, … in order. However, if you consider modifying this execution flow afterwards, you will find that the amount of modification can be very small if you use HierarFlow. The details are explained in another document called Why fuzzuf didn’t move to Rust, so please refer to that if you are curious.
It also has the advantage that the execution flow of the entire algorithm can be seen at a glance by the DSL. If we imagine that fuzzuf will be used in the field of academia, it will be easier to verify the correspondence between the pseudo code in the paper and the actual implementation.
VUzzer, which has an execution flow that deviates from Algorithm 1, can be represented simply by using HierarFlow as follows:
fuzz_loop << decide_keep << run_ehb << ( execute << update_fitness << trim_queue || execute_taint << update_taint || mutate || update_queue );
I hope this explanation has given you some idea of the uniqueness of fuzzuf. I believe that there is a trade-off between freedom and simplicity: the more freedom you restrict, the simpler the code you write, as in the Observer pattern. On the other hand, the range of algorithms that can be expressed will be reduced. fuzzuf is designed with the seemingly reckless philosophy of making it possible to write any fuzzing algorithms. I believe that the concept of HierarFlow has a certain rationality in this purpose. I would be very happy if anyone who finds this approach interesting, especially researchers, would use it.
Reproducibility and performance
Currently, the reproducibility and performance of the algorithms implemented in fuzzuf vary from one algorithm to another.
For example, AFL has an almost perfect reproduction of the core algorithms. The AFL on fuzzuf does not behave any differently from the original AFL, and is slightly faster, as confirmed in the repository fuzzuf-afl-artifact. AFLFast is also considered to be of similar quality, although it has not been checked yet (we will check it in the future).
On the other hand, fuzzuf’s libFuzzer does not implement some of the features of the original libFuzzer due to the absense of the binary instrumentation tool in fuzzuf. Also, while the original libFuzzer is unique in that it performs fuzzing within the binary to be fuzzed (in-process fuzzing), the fuzzuf libFuzzer does not. This is because fuzzuf is mainly interested in the theoretical performance of fuzzing algorithms and does not care about the delivery format at this time (This is also the reason why fuzzuf is not written in C, although it would be more advantageous to write it in C still as of 2021 for applications such as embedded systems). However, there are plans to implement AFL’s persistent mode, and it is expected to provide the similar performance to the original.
Moreover, when it comes to VUzzer and NEZHA, it is almost impossible to compare the original implementation with fuzzuf’s implementation:
Since the original VUzzer is written in Python2, it is difficult to make a fair comparison with C++. Moreover, as a result of changes in compiler implementations over time, VUzzer’s taint engine is becoming less and less able to propagate correct taint information in recent binaries.
NEZHA is an experimental algorithm that works only after modifying the target binaries(OpenSSL, LibreSSL, etc.) by hand, so the original implementation is not applicable to arbitrary binaries. On the other hand, it does not make much sense for us to implement them only for SSL libraries.
These algorithms need to be examined from the perspective of what makes the algorithm a completed one, and no conclusion has been reached at this point.
For these reasons, fuzzuf is still in a state that can best be described as alpha, but we will continue to improve the benchmarks and deal with what we can.
Future plans
In the future, fuzzuf plans to launch the following efforts:
Algorithm expansion
The following algorithms are planned to be implemented at this time:
- IJON [IJON].
- MOpt [MOpt].
- Eclipser [Eclipser].
- QSYM [QSYM].
- DIE [DIE].
Of these, the implementation of IJON is already almost complete and will be integrated within a few months.
As with VUzzer and NEZHA, each of these algorithms has different circumstances, and it is difficult to determine what is considered a complete implementation. For example, Eclipser is designed differently in v1.0 and v2.0, and we have to discuss whether to implement one or the other (or both). We would like to get your opinions on these discussions.
Generalization and expansion of Executor
Currently, fuzzuf has the following Executors (classes that execute binaries to be fuzzed):
- NativeLinuxExecutor
- PinToolExecutor
- QEMUExecutor
- CoreSightExecutor
- PolyTrackerExecutor
Note that there are no fuzzing algorithms that use QEMUExecutor and CoreSightExecutor, and they are only used in simple test codes.
Furthermore, Executor classes should have interchangeability, but this is not the case in the current fuzzuf. In other words, each fuzzing algorithm uses a specific one of these Executor classes. Essentially, a fuzzer that works with Edge Coverage, for example, should be compatible with PinToolExecutor, QEMUExecutor, and NativeLinuxExecutor (along with binaries instrumented with Edge Coverage). This will be addressed by refactoring the Executor classes.
Also, the following executors, which are not yet implemented, will be available in the future:
- WindowsExecutor (will be implemented with reference to WINNIE [WINNIE], etc.)
- AndroidExecutor
- Other Executor using dynamic instrumentation tools such as Frida and DynamoRIO
Benchmark expansion
We have not carried out enough benchmark testings on the algorithms implemented on fuzzuf. Since most of the algorithms implemented at this time are relatively classical algorithms, it is unlikely that they will perform dramatically better than the existing implementations. Still, it’s better to have more information about their performance to make sure no degradation happens. We are also looking for your feedback on what kind of benchmarks you would like us to perform.
Please check TODO.md for other plans.
Contributions and expected use cases
fuzzuf is intended to be a useful framework for all researchers in the fuzzing field, and we hope that you will propose and develop new fuzzing algorithms based on fuzzuf.
If your algorithm is novel and has been recognized by a paper or other works, we hope you will send us a PR to merge it into fuzzuf. This will make it easier for other researchers to compare, reproduce, and modify your work.
In the future, we would like to make it possible to compare the theoretical performance of various fuzzing algorithms within fuzzuf alone. For this purpose, we will continue to implement existing well-known fuzzing algorithms on fuzzuf. We would be very grateful if you could contribute to this as well.
Conclusion
We at Ricerca Security will continue to actively promote research and development, vulnerability assessment, and penetration testing in order to develop new values in offensive security. We are looking for people with an understanding of system security and computer science, skills to keep up with the latest research, and practical experience in penetration testing and vulnerability assessment. If you are interested in joining us, please visit Careers.
Acknowledgments
This project has received funding from the Acquisition, Technology & Logistics Agency (ATLA) under the Innovative Science and Technology Initiative for Security 2020 (JPJ004596).
References
[AFL]: Michal Zalewski. “american fuzzy lop” https://lcamtuf.coredump.cx/afl/
[libFuzzer]: “libFuzzer – a library for coverage-guided fuzz testing.” https://llvm.org/docs/LibFuzzer.html
[AFLFast]: Marcel Böhme, Van-Thuan Pham, and Abhik Roychoudhury. 2016. Coverage-based Greybox Fuzzing as Markov Chain. In Proceedings of the 23rd ACM Conference on Computer and Communications Security (CCS’16).
[VUzzer]:
Sanjay Rawat, Vivek Jain, Ashish Kumar, Lucian Cojocar, Cristiano Giuffrida, and Herbert Bos. 2017. VUzzer: Application-aware Evolutionary Fuzzing. In the Network and Distribution System Security (NDSS’17).
[MOpt]: Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, Wei-Han Lee, Yu Song, and Raheem Beyah. 2019. MOpt: Optimized Mutation Scheduling for Fuzzers. In Proceedings of the 28th USENIX Security Symposium (Security’19).
[NEZHA]: Theofilos Petsios, Adrian Tang, Salvatore Stolfo, Angelos D. Keromytis, and Suman Jana. 2017. NEZHA: Efficient Domain-Independent Differential Testing. In Proceedings of the 38th IEEE Symposium on Security and Privacy (S&P’17).
[Eclipser]: Jaeseung Choi, Joonun Jang, Choongwoo Han, and Sang K. Cha. 2019. Grey-box Concolic Testing on Binary Code. In Proceedings of the 41st ACM/IEEE International Conference on Software Engineering (ICSE’19).
[QSYM]: Insu Yun, Sangho Lee, Meng Xu, Yeongjin Jang, and Taesoo Kim. 2018. QSYM : A Practical Concolic Execution Engine Tailored for Hybrid Fuzzing. In Proceedings of the 27th USENIX Security Symposium (Security’18).
[IJON]: Cornelius Aschermann, Sergej Schumilo, Ali Abbasi, and Thorsten Holz. 2020. IJON: Exploring Deep State Spaces via Fuzzing. In Proceedings of the 41st IEEE Symposium on Security and Privacy (S&P’20).
[AFL++]: Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. 2020. AFL++: Combining Incremental Steps of Fuzzing Research. In Proceedings of the 14th USENIX Workshop on Offensive Technologies (WOOT’20).
[libAFL]: “LibAFL, the fuzzer library.” https://github.com/AFLplusplus/LibAFL
[FOT]: Hongxu Chen, Yuekang Li, Bihuan Chen, Yinxing Xue, and Yang Liu. 2018. FOT: A Versatile, Configurable, Extensible Fuzzing Framework. In Proceedings of the 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE’18).
[DIE]: Soyeon Park, Wen Xu, Insu Yun, Daehee Jang, and Taesoo Kim. 2020. Fuzzing JavaScript Engines with Aspect-preserving Mutation. In Proceedings of the 41st IEEE Symposium on Security and Privacy (S&P’20).
[WINNIE]: Jinho Jung, Stephen Tong, Hong Hu, Jungwon Lim, Yonghwi Jin, and Taesoo Kim. 2021. WINNIE: Fuzzing Windows Applications with Harness Synthesis and Fast Cloning. In the Network and Distribution System Security (NDSS’21).
[CollAFL]: Shuitao Gan, Chao Zhang, Xiaojun Qin, Xuwen Tu, Kang Li, Zhongyu Pei, and Zuoning Chen. 2018. CollAFL: Path Sensitive Fuzzing. In Proceedings of the 39th IEEE Symposium on Security and Privacy (S&P’18).
如有侵权请联系:admin#unsafe.sh