
我们经常使用机器学习(ML)技术来提高网络安全系统的质量,但是机器学习模型可能容易受到旨在“愚弄”它们以提供错误结果的攻击。这可能会对我们的公司和客户造成重大损害。因此,了解ML解决方案中的所有潜在漏洞以及如何防止攻击者利用这些漏洞至关重要。
这篇文章是关于我们如何攻击我们自己的DeepQuarantineML技术-它是反垃圾邮件系统的一部分,以及我们针对此类攻击部署了哪些保护方法。但首先,让我们仔细看看技术本身。
DeepQuarantine
DeepQuarantine是一种神经网络模型,用于检测和隔离可疑电子邮件。它为反垃圾邮件系统争取时间来更新我们的垃圾邮件过滤器并进行重新扫描。DeepQuarantine流程类似于机场安全服务的工作,引起怀疑的乘客将被带走进行额外检查。在安全部门检查他们的行李和检查他们的文件时,乘客必须等待。如果经过检查后发现没有问题,则允许乘客通过,否则将被拘留。在反垃圾邮件系统中,安全服务的角色由反垃圾邮件专家和服务机构扮演,这些专家和服务机构在电子邮件被隔离时处理大量电子邮件并创建新的检测规则。如果header分析揭示了垃圾邮件的新迹象,则会根据结果创建检测规则。同时,在邮件被隔离的同时可能会处理其他电子邮件,从而产生新的检测规则。电子邮件离开隔离区后,将对其进行重新扫描。如果这触发了任何新规则,则消息将被阻止;如果没有,则将其交付给收件人。请注意,隔离技术需要非常准确,以免延误合法的电子邮件——就像机场安检无法对每一位乘客进行全面检查一样,因为这会打乱出发时间表。如果这触发了任何新规则,则消息将被阻止;如果没有,则将其交付给收件人。请注意,隔离技术需要非常准确,以免延误合法的电子邮件——就像机场安检无法对每一位乘客进行全面检查一样,因为这会打乱出发时间表。
点击此处阅读有关DeepQuarantine工作原理的更多信息。要成功攻击ML模型,必须知道两件事:1)它用于决策的特征;2)它的训练数据是如何生成的。
为了识别可疑电子邮件,DeepQuarantine使用了一系列技术标头(例如,图1中此特性的值为“主题:发件人:收件人:日期:Message-Id:内容类型:X-Mailer”),加上Message-Id(唯一消息标识符)和X-Mailer(邮件客户端名称)字段的内容。选择这些特性是因为它们取决于所使用的邮件客户端的类型,并且可能包含垃圾邮件发送者的踪迹。

图 1. 电子邮件技术header
图2说明了算法的运作方式。左边是来自PayPal的真实信息,右边则是假的。如果要发送电子邮件,Message-Id是必需的,其格式取决于邮件客户端。如果我们将伪造的header与原始header进行比较,最大的不同是该字段缺少域和随机字符序列。

图 2. 真假 PayPal 电子邮件header的比较
诈骗者在模型处理的各种技术标头中留下的各种痕迹表明这是一项艰巨的任务。
现在让我们看看生成训练数据的过程,这是对我们的模型实施攻击的起点。

图 3. 训练样本生成方案
用于训练模型的数据和标签是在反垃圾邮件系统的一般操作过程中自动生成的。训练样本生成方案如图3所示。在扫描邮件后,如果客户端同意数据处理,Anti-Spam会将其header和判定转发到卡巴斯基安全网络(KSN)。这些数据从KSN被发送到一个存储库,在那里它被用来训练模型。邮件header用作分析样本,反垃圾邮件引擎的判定用作标签。
对机器学习模型的攻击
是什么使得攻击机器学习模型成为可能?这主要是因为使用机器学习技术,训练样本中的数据分布有望与模型在现实世界中遇到的数据分布相匹配。违反此原则可能会导致算法出现意外行为。因此,对机器学习模型的攻击可以分为两种:
00001. 对抗性输入——生成输入数据,导致已经训练和部署的模型给出错误的判断。
00002. 数据中毒——影响训练样本以产生有偏差的模型。
在第一种情况下,为了成功,对手通常需要直接与模型交互。DeepQuarantine只是反垃圾邮件系统的一个组成部分,因此排除了与其直接交互的可能性。第二种类型的攻击对我们的模型来说危险得多。让我们仔细看看。
数据中毒攻击可以进一步分为两个子类型:
00001. 模型倾斜——污染训练样本以改变模型的决策边界。这种攻击的一个例子是针对Google的垃圾邮件分类器,其中高级垃圾邮件组试图通过将大量垃圾邮件标记为“非垃圾邮件”来污染训练样本。目的是让系统允许更多垃圾邮件通过。
00002. 后门攻击——将具有特定标记的示例引入训练样本以迫使模型做出错误决策。例如,在属于某个类别(比如狗)的图片中嵌入一个灰色方块,仅当模型在看到这个方块时才开始识别狗,而这张照片可能根本不是狗。
有几种方法可以降低数据中毒攻击的风险:
00001. 确保来自少量来源(例如,来自一小群用户或IP地址)的输入数据不占训练样本的大部分。这会迫使垃圾邮件发送者采取额外的措施来防止他们的操作被作为统计异常值而遭到拒绝,从而使垃圾邮件发送者更难实施此类攻击。
00002. 在发布模型的更新版本之前,使用一系列技术将其与最新的稳定版本进行比较,例如A/B测试(比较测试环境中各种变化的版本)、摸黑启动(为一小部分试点客户运行更新的服务)或回溯测试(测试历史数据的模型)。
00003. 创建一个基准数据集,该数据集的正确评估结果是已知的,您可以根据该数据集验证模型的准确性。
对DeepQuarantine的攻击
现在让我们继续攻击DeepQuarantine。假设攻击者的目标是隔离其雇主的竞争对手公司发送的所有电子邮件,这些电子邮件将严重影响其业务流程。我们调查攻击者的步骤:
00001. 找出公司使用的邮件客户端以及公司发送电子邮件时生成的header类型。
00002. 生成header与受攻击公司类似的垃圾邮件。在邮件正文中添加一些明显的垃圾邮件过滤触发器,例如,显式广告或已知的网络钓鱼链接,这样邮件几乎不可避免地被标记为垃圾邮件。
00003. 将这些消息发送给我们的客户端,以便反垃圾邮件系统阻止它们,并将相关统计信息输入到训练和测试样本中,如图3所示。
如果在对中毒样本进行训练后,模型通过了测试,则被攻击的模型将被释放,并且来自受害公司的电子邮件开始被隔离。接下来,我们尝试不同的数据中毒技术。
方法
首先,我们采集了干净的训练和测试数据样本,这些样本由一组带有相应反垃圾邮件判断的电子邮件header组成。在这两个样本中,我们都添加了模仿受攻击公司中毒的header,并以不同的数量判定“垃圾邮件”:样本大小的0.1%、1.5%和10%。对于每个实验,训练样本和测试样本中中毒数据的比例相同。
在中毒训练样本上训练模型后,我们使用测试样本来检查精度(正确的肯定结论在所有模型的肯定结论中的比例)和召回率(正确肯定结论在垃圾邮件标题总数中的比例)样本)指标,以及模型分配给受攻击公司电子邮件的“垃圾邮件”判决的可信度。
实验1.模型倾斜
我们的第一个实验实施了一种模型倾斜方法,就像对谷歌反垃圾邮件模型的攻击一样。然而,与谷歌的例子不同,我们的目标是模拟对特定公司的攻击,这稍微复杂一些。在本例中,我们在Message-Id字段中使用了所选公司的域(图4),但ID本身是随机生成的,仅保留该公司使用的邮件客户端特定的长度。我们没有更改受攻击公司邮件客户端的header序列或X-mailer字段。

图 4. 中毒示例模板
我们分析了我们的目标指标(精度和召回率)如何根据中毒数据相对于训练样本量的比例在测试数据集上发生变化。结果如图5所示。如图所示,相对于数据中没有中毒示例,目标指标几乎保持不变。这意味着可以发布在中毒样本上训练的模型。

图 5. 取决于中毒数据量的目标指标
我们还使用来自我们选择的公司的真实电子邮件的header,测试了数据中毒如何影响模型对消息应该被隔离的置信度。
如图5所示,当中毒数据的份额超过5%时,模型已经强烈倾向于认为应该隔离受攻击公司的电子邮件。因此,这种有偏见的模型可能会切断该公司与我们客户之间的通信,而这正是攻击者试图实现的目标。





图 6. 根据数据中毒的数量,模型对隔离受害公司电子邮件的需求的信心密度发生的变化
现在,基于那些导致模型做出错误决策的对象,让我们看看它在看什么。为此,我们使用Saliency via Occlusion方法构建了一系列特征图(见图6),其中header某些部分的显著性是通过交替隐藏这些部分并评估这是如何改变模型的置信度来建立的。图片中的区域颜色越深,说明神经网络在决策过程中就越关注这个区域。该图还显示了来自所选公司(Target)和其他公司(Other)的电子邮件被隔离的数量。

图 7. 特征图
正如我们在图中看到的,只要模型没有足够的中毒数据来对来自受攻击公司的电子邮件返回误报,该模型就主要集中在Message-Id字段上。但是一旦中毒数据足以使模型产生偏差,它的注意力就会均匀地分布在Message-Id、X-mailer字段(图中的MUA)和电子邮件中的标题序列(标题序列)之间。
请注意,尽管5%的中毒数据足以进行成功攻击,但从绝对值来看,这是相当多的数据。例如,如果我们使用超过1亿封电子邮件进行训练,攻击者将需要发送超过500万封电子邮件,而这些邮件很可能会被监控系统接捕获。
我们能否更有效地攻击我们的模型?事实证明我们可以。
实验2.带时间戳的后门攻击
某些邮件用户代理在Message-Id字段中指定时间戳。我们使用这个事实来创建带有与模型发布日期相对应的时间戳的中毒header。如果攻击成功,该模型会将在发布当天收到的来自受攻击公司的电子邮件进行隔离。图8显示了我们如何生成中毒数据。

图 8. 数据后门
这种数据中毒是否会影响模型预发布测试中的目标指标?结果与模型倾斜攻击相同(图9)。

图 9. 取决于中毒数据量的目标指标
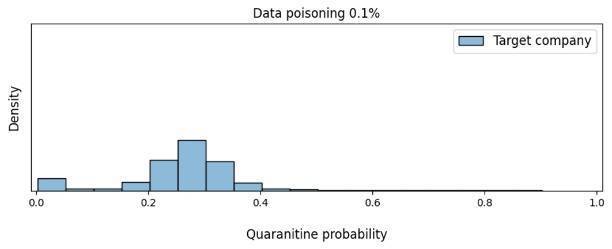
所需的数据中毒量是否会影响攻击的效率?正如我们在图10中看到的,在这种情况下,攻击者只需要0.1%的中毒数据即可将模型转变为将受害公司的电子邮件标记为可疑。





图 10. 基于数据中毒量的模型对隔离受害公司电子邮件的信心密度的变化
让我们再次看一下特征图,看看我们的模型在本例中关注了什么。图11显示,在中毒率为0.1%时,模型侧重于域起始区域、代理类型和header序列,神经网络主要集中在时间戳上。我们还注意到,当模型只关注时间戳时,它会对来自其他公司的电子邮件(这些公司的Message-Id也以时间戳开头)发出更多误报。随着中毒级别的增加,模型变得专注于时间戳和域起始区域。同时,它对X-mailer领域和header序列。

图 11. 特征图
实验3.带时间戳的后门攻击-延迟攻击
在之前的实验中,我们能够显着提高攻击效率。但实际上,攻击者不太可能知道模型的发布日期。在这个实验中,我们决定进行延迟攻击,看看这是否会影响测试结果。为此,我们生成了带有时间戳的有毒header,时间戳从当前的发布日期前移一年。
结果如图12所示:样本中毒在测试过程中没有以任何方式反映出来,这对我们来说是最危险的结果,因为这意味着攻击几乎不可能被监测出来。鉴于后门将在未来不确定的时刻被激活,即使是摸黑启动和A/B测试也无助于识别攻击。





图 12. 模型对隔离受害公司电子邮件需求的信心依赖于数据中毒量
根据实验结果,我们得出以下结论:
00001. 模型倾斜需要相当多的中毒样本
00002. 攻击的事实并没有反映在准确率和召回率上
00003. 添加“后门”(在我们的例子中是时间戳)使攻击更有效
00004. 在延迟攻击的情况下,摸黑启动和A/B测试可能无效
我们通过实验证明了对我们技术的成功攻击。但这又引出了一个问题:如何防御此类攻击?
防止对ML模型的攻击
在我们的实验背景下,让我们仔细看看防范数据中毒攻击的方法,我们在“对机器学习模型的攻击”这一节中提到过:训练数据的受控选择;A/B测试、摸黑启动或反向测试等技术;生成精心控制的基准数据集。训练样本的受控选择确实使攻击实现复杂化,因为攻击者必须找到一种发送虚假数据的方法,因此很难分组和过滤。这在技术上可能很困难,但不幸的是,并非不可能。例如,为了防止中毒电子邮件按IP地址分组,攻击者可以使用僵尸网络。
当涉及到创建一个额外的基准数据集时,如果数据分布随时间发生变化,问题就出现了——该数据集将保持当前状态多长时间。
将更新的模型与最新的稳定工作版本进行比较似乎是一个更好的解决方案,因为这使我们能够监控模型的变化。但是如何将它们相互比较呢?
让我们考虑两个选项:比较当前测试数据集上的模型版本(选项1),并比较每个版本发布时的当前测试数据集上的模型版本(选项2)。下表显示了我们为这两个选项运行的测试序列。

在模型对比的第二阶段,我们进行了一系列的统计检验:首先,我们比较了模型的目标指标。在这个阶段,我们看到在不同程度的数据污染的样本上训练的原始版本和更新后的版本之间没有显着差异。我们在实验攻击中获得了类似的结果。
· 配对样本的Wilcoxon符号秩检验
· 对独立样本进行Mann-Whitney U检验
· 样品均匀性的Kolmogorov-Smirnov检验
实验揭示了一些奇怪的事情:结果证明,即使在比较两个在干净样本上训练的模型时,标准也会产生显着差异,尽管这些模型的预测分布彼此差异不大。发生这种情况的原因是,有了大量的数据,测试对分布形状的最细微变化过于敏感。但是当我们减少统计测试中的数据量时,我们经常发现根本没有显着差异,因为攻击目标的消息甚至可能不会最终出现在所采集的样本中。对这个结果不满意,我们制定了自己的标准。
我们基于这样的一个事实,即在干净样本上训练的模型在相应测试数据集产生的分布形状方面几乎没有区别。而在对中毒样本进行训练的模型的预测分布中,“驼峰”可能出现在分布的右端。图13显示了一个大的“驼峰”以供说明。但实际上,它几乎不会引起注意,因为来自受攻击公司的电子邮件量可能只占总消息流的一小部分。

图 13. 合法电子邮件上模型预测的模型分布
在分析过程中,我们得出了Wasserstein指标。实际上,该指标用作分布之间距离的度量。我们的标准如下:
H0:训练前后对非垃圾邮件样本的预测分布没有显示出统计上的显着变化,即系统保持不变。
H1:分布的变化在统计上是显著的,也就是说,系统发生了变化。
我们使用Wasserstein度量来评估合法电子邮件样本中新旧模型预测分布之间的变化。为了评估预测分布变化的统计显著性,我们需要在正确的零假设下找出这些变化的分布,即没有发生显著变化的模型版本。我们使用引导获得了这个分布—在干净数据上训练的模型的抽样预测,但在不同的时间段。通过这种方式,我们重构了实际的真实世界情况。之后,我们进行了一系列的统计测试,比较了原始模型和在不同比例中毒数据样本上训练的模型的预测分布。Wasserstein标准没有显示正常模型或在延迟攻击数据上训练的模型的显着差异。这是意料之中的,因为我们已经看到延迟攻击在测试中没有以任何方式表现出来。然而,在其他情况下,我们发现了显着差异。这意味着Wasserstein标准允许我们及时检测大多数此类攻击。
对于延迟攻击,以及在数据中引入后门标签的一般可能性,需要对潜在后门进行详细的数据审计。正如测试机器学习模型对此类攻击的抵抗力一样。
要点
越来越多的机器学习方法被引入到各种服务中。这提高了性能指标并改善了用户的生活。然而,它也使新的攻击场景成为可能。我们的实验表明:
00001. 数据中毒攻击会对机器学习模型造成重大损害。
00002. 攻击者不需要是数据科学家。
00003. 时间戳可以很容易地用作攻击机器学习模型的后门。
00004. 标准质量指标不反映数据中毒攻击的事实。
00005. 为了降低成功攻击模型的可能性,必须控制训练和采样过程。
00006. 在披露模型训练和架构的细节时必须格外小心,以免攻击者利用它们。
00007. 在发布模型之前,应彻底测试所使用的标准,以确定模型的准备情况以及它们是否可以检测到潜在的攻击。如果标准不足以确定模型是否受到攻击,那么就有必要开发自己的模型。
本文翻译自:https://securelist.com/attack-on-anti-spam-machine-learning-model-deepquarantine/105358/如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh